telnet host 10086
- 个人中心
- Ta 发表的回复(2255)
-
请问一下,telnet 10086 connection refused 我应该做哪些检查呢?
-
flume 相关?
@wwwzhangnanwc 哈哈,下次粗心打屁股
-
flume 相关?
@wwwzhangnanwc f1改成source1
-
flume 相关?
这个问题跟你挺像的。你看一下
-
请问一下,nginx 的这个报错是什么原因呢?
检查一下eth0网卡的配置文件
-
请问一下,nginx 的这个报错是什么原因呢?
感觉你网卡的MAC地址不正确
-
hive 自定义 udaf 的缓冲区集群工作原理是什么?
@Balder-Chang 不要把它理解成缓冲区,就理解成数据的bean,过去的是自己的,底层是mr都是自己跑自己的。
-
hive 自定义 udaf 的缓冲区集群工作原理是什么?
MyAvgAggregationBuffer就是数据的bean,每map用自己的,然后在reduce进行汇总,merge方法就相当于reducer中的reduce方法,UDAF那几个方法就是个mr的过程。
-
请问一下,hive runner 我在 setup 的时候 eclipse 上报错 有点完全没有头绪。。是哪里错了呢?
@LUNLI 用navicat连接测试一下hive账户。如果能连接上,就说明mysql没有问题。那就是你程序的问题。
-
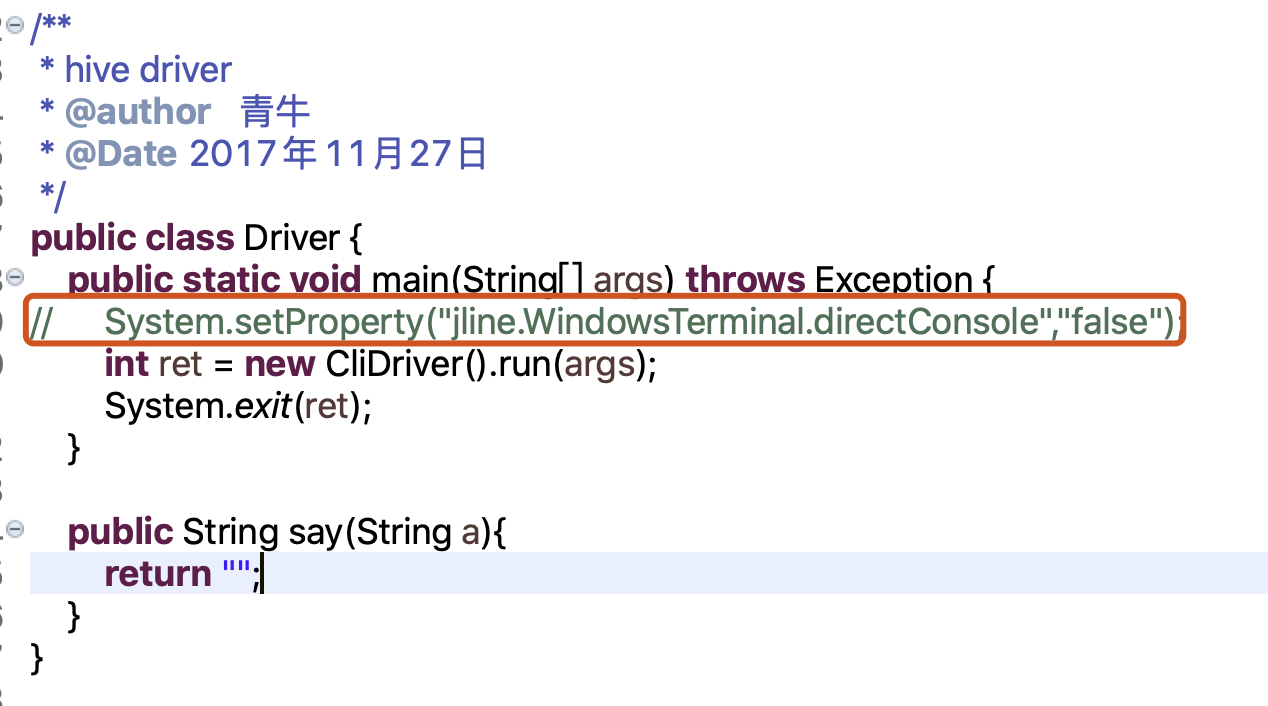
请问一下,hive runner 我在 setup 的时候 eclipse 上报错 有点完全没有头绪。。是哪里错了呢?
@LUNLI 另外mac不用加这行代码哈,然后你配置好环境变量,其它的没区别了
-
请问一下,hive runner 我在 setup 的时候 eclipse 上报错 有点完全没有头绪。。是哪里错了呢?
@LUNLI 你这个是你的mysql库没连接上,先用命令mysql -uhive -p 在terminal里面测试一下。
-
请问一下,我的 hive 里 001 的分隔符并不显示 请问是为什么呢?
@羽翔 恩控制台显示不了那个\001,只能打开看
-
关于 hive 在 eclipse 上 pom 文件出错的问题?
@wwwzhangnanwc 恩,网络不好的事,有的时候jar包没下载全
-
如何在 join 的 mapper 阶段 不同表来自多个输入时,如何指定对应的输入文件?
@羽翔 给你两种多目录输入的方法,你参考一下
第一种:
/** * InnerJoin.java * com.hainiu.mapreducer.mr * Copyright (c) 2017, 海牛版权所有. * @author 青牛 */ package com.hainiu.mapreducer.mr; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; /** * mr实现类似于sql的innerjoin * * @author 青牛 * @Date 2017年8月28日 */ public class InnerJoin extends Configured implements Tool { public static final String SIGN1 = "\t"; public static final String SIGN2 = "\001"; public static class InnerJoinMapper extends Mapper<LongWritable, Text, Text, WordWritable> { private Text outKey = new Text(); private WordWritable outValue = new WordWritable(); /** * 可以从这个map任务的输入文件的目录名称来判断是属于那类数据从而进行数据的分类 * map任务中使用context对象可以获得本次任务的输入地址 */ @Override protected void setup(Context context) throws IOException, InterruptedException { FileSplit inputSplit = (FileSplit) context.getInputSplit(); String path = inputSplit.getPath().toString(); if (path.contains("minout")) { outValue.setType("1"); } else if (path.contains("maxout")) { outValue.setType("2"); } } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String str = value.toString(); String strs[] = str.split(SIGN1); if (strs.length != 2) { return; } String word = strs[0]; Long num = Long.parseLong(strs[1]); outKey.set(word); outValue.setN(num); outValue.setWord(outKey); context.write(outKey, outValue); } } public static class InnerJoinReducer extends Reducer<Text, WordWritable, Text, Text>{ private Text outValue = new Text(); private List<Long> firstList = new ArrayList<Long>(); private List<Long> secondList = new ArrayList<Long>(); @Override protected void reduce(Text key, Iterable<WordWritable> value,Context context) throws IOException, InterruptedException { //注意进行缓存的清理,不然下一个key的数据也会被追加到每次key的后面 firstList.clear(); secondList.clear(); for(WordWritable wordWritable:value){ if(wordWritable.getType().equals("1")){ firstList.add(wordWritable.getN()); }else{ secondList.add(wordWritable.getN()); } } //时行数据的拼接输出 for(Long max:secondList){ for(Long min:firstList){ outValue.set(max + SIGN1 + min); context.write(key, outValue); } } } } public int run(String[] args) throws Exception { Configuration conf = getConf(); //定义Job名字并设置任务配置 Job job = Job.getInstance(conf, "innerjoin"); //设置Jar使用的Class job.setJarByClass(InnerJoin.class); //设置使用的Mapper Class job.setMapperClass(InnerJoinMapper.class); //设置使用的Reducer Class job.setReducerClass(InnerJoinReducer.class); //设置mapper任务的输出value类型 job.setMapOutputValueClass(WordWritable.class); //设置任务的输出Key类型 job.setOutputKeyClass(Text.class); //调协任务的输出Value类型 job.setOutputValueClass(Text.class); //设置任务的输入地址,可以设置多个目录为输入,用逗号隔开/tmp/mulitipleoutmaxmin/maxout,/tmp/mulitipleoutmaxmin/minout FileInputFormat.addInputPaths(job, args[0]);; //设置任务的输出地址,对应的是一个目录 Path outputDir = new Path(args[1]); FileOutputFormat.setOutputPath(job, outputDir); //删除输出目录 FileSystem fs = FileSystem.get(conf); if (fs.exists(outputDir)) { fs.delete(outputDir, true); System.out.println("out put delete finish"); } //等待任务执行完成 int i = job.waitForCompletion(true) ? 0 : 1; return i; } public static void main(String[] args) throws Exception { System.exit(ToolRunner.run(new InnerJoin(), args)); } }第二种:
/** * InnerJoin.java * com.hainiu.mapreducer.mr * Copyright (c) 2017, 海牛版权所有. * @author 青牛 */ package com.hainiu.mapreducer.mr; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.mapreduce.lib.input.MultipleInputs; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; /** * mr实现类似于sql的innerjoin * * @author 青牛 * @Date 2017年8月28日 */ public class InnerJoin2 extends Configured implements Tool { public static final String SIGN1 = "\t"; public static final String SIGN2 = "\001"; public static class InnerJoinMaxMapper extends Mapper<LongWritable, Text, Text, WordWritable> { private Text outKey = new Text(); private WordWritable outValue = new WordWritable(); /** * 根据任务设置不同的数据输出类型 */ @Override protected void setup(Context context) throws IOException, InterruptedException { outValue.setType("2"); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String str = value.toString(); String strs[] = str.split(SIGN1); if (strs.length != 2) { return; } String word = strs[0]; Long num = Long.parseLong(strs[1]); outKey.set(word); outValue.setN(num); outValue.setWord(outKey); context.write(outKey, outValue); } } public static class InnerJoinMinMapper extends Mapper<LongWritable, Text, Text, WordWritable> { private Text outKey = new Text(); private WordWritable outValue = new WordWritable(); /** * 根据任务设置不同的数据输出类型 */ @Override protected void setup(Context context) throws IOException, InterruptedException { outValue.setType("1"); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String str = value.toString(); String strs[] = str.split(SIGN1); if (strs.length != 2) { return; } String word = strs[0]; Long num = Long.parseLong(strs[1]); outKey.set(word); outValue.setN(num); outValue.setWord(outKey); context.write(outKey, outValue); } } public static class InnerJoinReducer extends Reducer<Text, WordWritable, Text, Text> { private Text outValue = new Text(); private List<Long> firstList = new ArrayList<Long>(); private List<Long> secondList = new ArrayList<Long>(); @Override protected void reduce(Text key, Iterable<WordWritable> value, Context context) throws IOException, InterruptedException { //注意进行缓存的清理,不然下一个key的数据也会被追加到每次key的后面 firstList.clear(); secondList.clear(); for (WordWritable wordWritable : value) { if (wordWritable.getType().equals("1")) { firstList.add(wordWritable.getN()); } else { secondList.add(wordWritable.getN()); } } //时行数据的拼接输出 for (Long max : secondList) { for (Long min : firstList) { outValue.set(max + SIGN1 + min); context.write(key, outValue); } } } } public int run(String[] args) throws Exception { Configuration conf = getConf(); //定义Job名字并设置任务配置 Job job = Job.getInstance(conf, "innerjoin2"); //设置Jar使用的Class job.setJarByClass(InnerJoin2.class); //设置使用的Reducer Class job.setReducerClass(InnerJoinReducer.class); //设置mapper任务的输出value类型 job.setMapOutputValueClass(WordWritable.class); //设置任务的输出Key类型 job.setOutputKeyClass(Text.class); //调协任务的输出Value类型 job.setOutputValueClass(Text.class); //设置任务的输入地址,并设置每个地址使用的mapper MultipleInputs.addInputPath(job, new Path(args[0]), TextInputFormat.class, InnerJoinMaxMapper.class); MultipleInputs.addInputPath(job, new Path(args[1]), TextInputFormat.class, InnerJoinMinMapper.class); //设置任务的输出地址,对应的是一个目录 Path outputDir = new Path(args[2]); FileOutputFormat.setOutputPath(job, outputDir); //删除输出目录 FileSystem fs = FileSystem.get(conf); if (fs.exists(outputDir)) { fs.delete(outputDir, true); System.out.println("out put delete finish"); } //等待任务执行完成 int i = job.waitForCompletion(true) ? 0 : 1; return i; } public static void main(String[] args) throws Exception { System.exit(ToolRunner.run(new InnerJoin2(), args)); } } -
关于 hive 在 eclipse 上 pom 文件出错的问题?
@wwwzhangnanwc 那就是你里面有的pom没下载到,不行就本地仓库删除了重新下载