关于 “” 的搜索结果, 共 2411 条
Hadoop 遇到 UnknownHostException,且无权限更改 hosts 文件,有办法解决吗?
by
 冥
冥
https://hainiubl.com/topics/36939?
2019-07-24
⋅
2621
⋅
0
⋅
1
在部署,format的时候都正常,也可以正常上传文件,可是在执行任务时无法正常运行了。其他地方都是直接使用的服务器ip。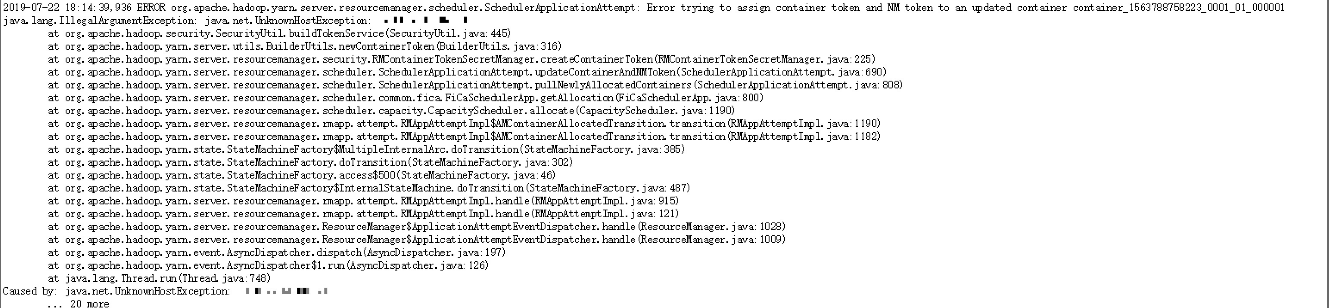
现有的一些算法库如何移植到分布式系统上?
by
 半杯湖底沙
半杯湖底沙
https://hainiubl.com/topics/36940?
2019-07-24
⋅
1933
⋅
0
⋅
1
现有很多数据处理算法库都是针对单机写的,如图像处理库gdal,opencv,以及自己的算法库(c\c++or python)等高级算法库,它们将如何移植到分布式平台hadoop或spark上使用,如果这些算法库都移植不过去,目前分布式平台数据处理也太不高级了
hadoop 集群中 datanode 启动几秒钟为什么就自动关闭了。?
by
 zqlchlh
zqlchlh
https://hainiubl.com/topics/36941?
2019-07-24
⋅
2604
⋅
0
⋅
1

sql server 中如何对数据进行分层抽样?
by
 李腾飞
李腾飞
https://hainiubl.com/topics/36943?
2019-07-25
⋅
4380
⋅
0
⋅
1
是这样,想根据一个字段对数据进行分层抽样,这个字段大概有300来个可取的值,不要说每个可取值随机抽样然后union……会瞎的。
百度不到答案,还请有经验的大大不吝赐教!
Python 经过 Tucker 分解之后如何恢复原始矩阵?
by
 hadooper
hadooper
https://hainiubl.com/topics/36944?
2019-07-25
⋅
3034
⋅
0
⋅
1
使用Python中的tensorly对一个三维矩阵进行分解(Tucker分解),如何对分解结果才能恢复成原始三维数据矩阵 ?
为什么 String 在 java 中是不可变的?
by
 Whalley
Whalley
https://hainiubl.com/topics/36945?
2019-07-25
⋅
2323
⋅
0
⋅
1
为什么String在java中是不可变的?
sqoop2 怎么导入 hbase?
by
 大中
大中
https://hainiubl.com/topics/36946?
2019-07-29
⋅
2965
⋅
0
⋅
13
sqoop2 怎么导入hbase,用phoenix jdbc driver 报错classnotfound,加入phoenix-client.jar,报权限错误。
请问这个 java 代码中 player 是什么?
by
 Alex
Alex
https://hainiubl.com/topics/36948?
2019-07-29
⋅
2602
⋅
0
⋅
1
还有,请问有什么适合入门的书籍看看吗?主要对web方面感兴趣。通过知乎的推荐买了本head frist java,这逻辑看得一脸蒙,感觉文章里面好多缺代码似的。

如何使用 jmx 获取 kafka 数据?
by
 M先生
M先生
https://hainiubl.com/topics/36949?
2019-07-29
⋅
3017
⋅
0
⋅
1
在kafka2.11以上版本中如何使用jmx获取kafka的数据?jconsole连接不上,网上说的方法针对kafka的版本都太旧了,停留在0.8版本,最新版本上采用那些办法并不适用。自己写了一点程序运行时出现如下错误不知如何解决
 不忘初心
不忘初心
https://hainiubl.com/topics/36950?
2019-07-30
⋅
2402
⋅
0
⋅
1
kafka,flink,storm,都只能使用Java进行开发?
Python 如何将 PyCBitmap 保存为 jpg 格式的文件?
by
Alex
https://hainiubl.com/topics/36952?
2019-07-30
⋅
3641
⋅
0
⋅
1
使用win32api中e的SaveBitmapFilez方法只能将PyCBitmap保存为BMP文件,一张1920*1080的图像接近8M大小,请问如何压缩成jpg格式的图片呢?
pyspark on yarn 模式如何搭建?
by
M先生
https://hainiubl.com/topics/36953?
2019-07-30
⋅
3206
⋅
0
⋅
1
请问一下如何基于集群Python3搭建pyspark集群on yarn模式?
问题1:在集群搭建好yarn和hadoop后,需要每台都装同版本的Python3以及相同的依赖包,如pandas吗。
问题2:搭建好后如何启动pyspark进入yarn模式,如果可以的话能否在jupyter调用,而非submit模式。...
这段 Java 代码为什么有错误?
by
 滴磨成觞
滴磨成觞
https://hainiubl.com/topics/36955?
2019-08-01
⋅
2236
⋅
0
⋅
1
Number x = new Integer (3);
System.out.println(x.compareTo(new Integer(4));
错误信息是x没有compareTo这个方法。可x也是Number类为什么没有这个方法呢
hadoop 是不是本身就支持 Windows?
by
 寒冰雪域
寒冰雪域
https://hainiubl.com/topics/36956?
2019-08-01
⋅
2479
⋅
0
⋅
2
最近学大数据,在windows上搭建spark环境,下载了hadoop2.7的二进制版本,然后打开hadoop文件夹看了一下,发现里面居然有linux和windows两种命令行脚本文件,但是教程说的却是要下载一个winutil把那个hadoop的bin直接覆盖了,可是这不是很矛盾吗,既然hadoop不支持windo...
python 出现 module random'has no attribute sets 错误怎么办?
by
 YDS
YDS
https://hainiubl.com/topics/36957?
2019-08-01
⋅
2625
⋅
0
⋅
1
求解答
java webmagic 多线程爬取,其中一个线程爬取时出现越界异常 框架会怎么处理?
by
 zhangxingong
zhangxingong
https://hainiubl.com/topics/36958?
2019-08-01
⋅
2605
⋅
0
⋅
1
java webmagic 多线程爬取,其中一个线程爬取时出现越界异常 框架会怎么处理?
python 出现 module random'has no attribute sets 错误怎么办?
by
 李鴻飛
李鴻飛
https://hainiubl.com/topics/36959?
2019-08-01
⋅
2277
⋅
0
⋅
1
求解答
TB 级数据排序,可以用 hive 的 order by ?
by
大中
https://hainiubl.com/topics/36960?
2019-08-02
⋅
3077
⋅
0
⋅
3
TB级数据怎么排序,分页?
solrcloud 可以搜索 tb 级数据?
by
大中
https://hainiubl.com/topics/36961?
2019-08-02
⋅
2582
⋅
0
⋅
1
solrcloud适合处理tb级的数据吗?tb级的indexer如何快速导入?
怎么在 hbase-indexer 中建 copyfield?
by
大中
https://hainiubl.com/topics/36962?
2019-08-02
⋅
2637
⋅
0
⋅
5
怎么在hbase-indexer中建copyfield,如果不能建,如何使从hbase导入的indexer跨字段搜索?
大数据学习需要学习算法吗?
by
 张小果
张小果
https://hainiubl.com/topics/36963?
2019-08-05
⋅
2735
⋅
0
⋅
1
请教下,大数据学习需要学习算法吗?如果需要学习,这个算法是算法导论里的算法还是机器学习中的算法啊
spark 中 driver 参与数据加载吗?
by
 小龙
小龙
https://hainiubl.com/topics/36964?
2019-08-05
⋅
3078
⋅
0
⋅
1
比如说加载kafka数据,是每个executor各自加载一部分还是driver加载之后发送给executor?
Structured Streaming 如何完成数据处理呢?
by
滴磨成觞
https://hainiubl.com/topics/36965?
2019-08-05
⋅
2274
⋅
0
⋅
1
场景: Structured Streaming + kafka + maxwell, 处理mysql-binlog的实时流数据.
通过代码kafka_df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "spark-kafka:9092") \
.option("subscribe", "streaming").load
得到...
java 怎么取 Map 里得 字符串 List<对象>?
by
寒冰雪域
https://hainiubl.com/topics/36966?
2019-08-05
⋅
2565
⋅
0
⋅
1
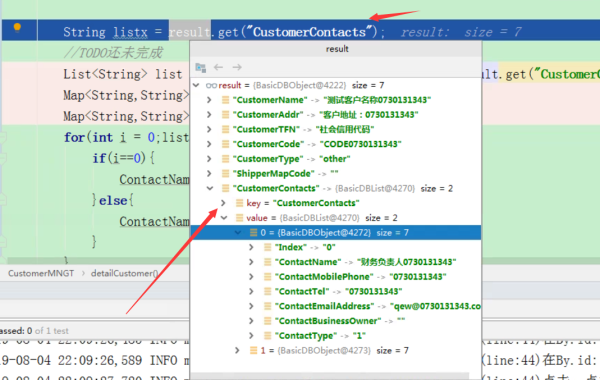
郁闷只要get这个Key就报错了,郁闷呀,大佬们谁能告诉我怎么取这个list
数据库 MySQL 数据和索引分别存在哪些文件中?
by
寒冰雪域
https://hainiubl.com/topics/36967?
2019-08-06
⋅
2816
⋅
0
⋅
1
补充:innodb引擎存储索引和数据的文件在哪些路径下
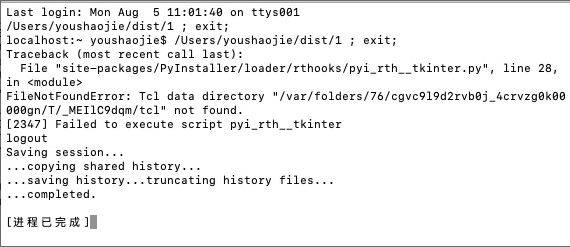
大佬们,这是怎么回事呀???Mac 不用 turtle 库打包就可以,用了 turtle 库打包就报错了?
by
 张
张
https://hainiubl.com/topics/36968?
2019-08-06
⋅
2767
⋅
0
⋅
1

请教下关于大数据 ETL 工程师的工作?
by
 肖海艳
肖海艳
https://hainiubl.com/topics/36969?
2019-08-07
⋅
2854
⋅
0
⋅
3
感觉听人提到ETL更多时候是说写SQL,想问问这工作中写JAVA的比重有多少?
sqoop 导入 hbase 原表没有 pk 怎么办?
by
大中
https://hainiubl.com/topics/36970?
2019-08-07
⋅
2358
⋅
0
⋅
1
sqoop 导入hbase 原表没有pk ,应该怎么导入,怎么在导入中自建rowkey
spark streaming 直连 kafka,某个 leader 挂了之后,不会去连新的 leader 吗?
by
 陪你去看海
陪你去看海
https://hainiubl.com/topics/36971?
2019-08-07
⋅
2614
⋅
0
⋅
1
spark1.6,kafka0.8.2.1
spark streaming直连kafka,某个leader挂了之后,应用也挂了,而且重启应用也起不来,除非挂掉的leader起来后才行,什么原理,如何解决?