关于 “” 的搜索结果, 共 2411 条
一个对象不再使用,有必要手动置为 null 吗?
by
 张文海
张文海
https://hainiubl.com/topics/37038?
2019-09-12
⋅
2261
⋅
0
⋅
1
是否多此一举呢?
Java 的一个问题,关于子类对象调用父类的返回值为 this 的方法,this 指向问题?
by
 如风
如风
https://hainiubl.com/topics/37039?
2019-09-13
⋅
3355
⋅
0
⋅
1
Java的一个问题,关于子类对象调用父类的返回值为this的方法,this指向问题。最近在网上看到了两个例子,觉得有点矛盾了,百思不得其解。先看图一的代码。

这个时候可以看到结果输出,子...
JVM 中的这些宏怎么理解?
by
 刘明
刘明
https://hainiubl.com/topics/37041?
2019-09-16
⋅
2086
⋅
0
⋅
1

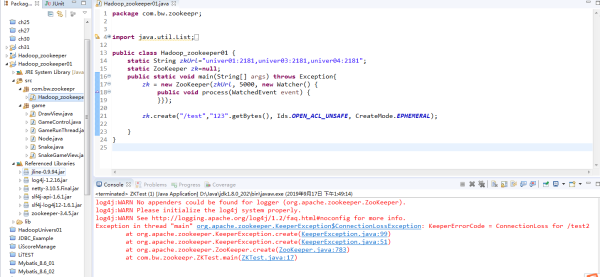
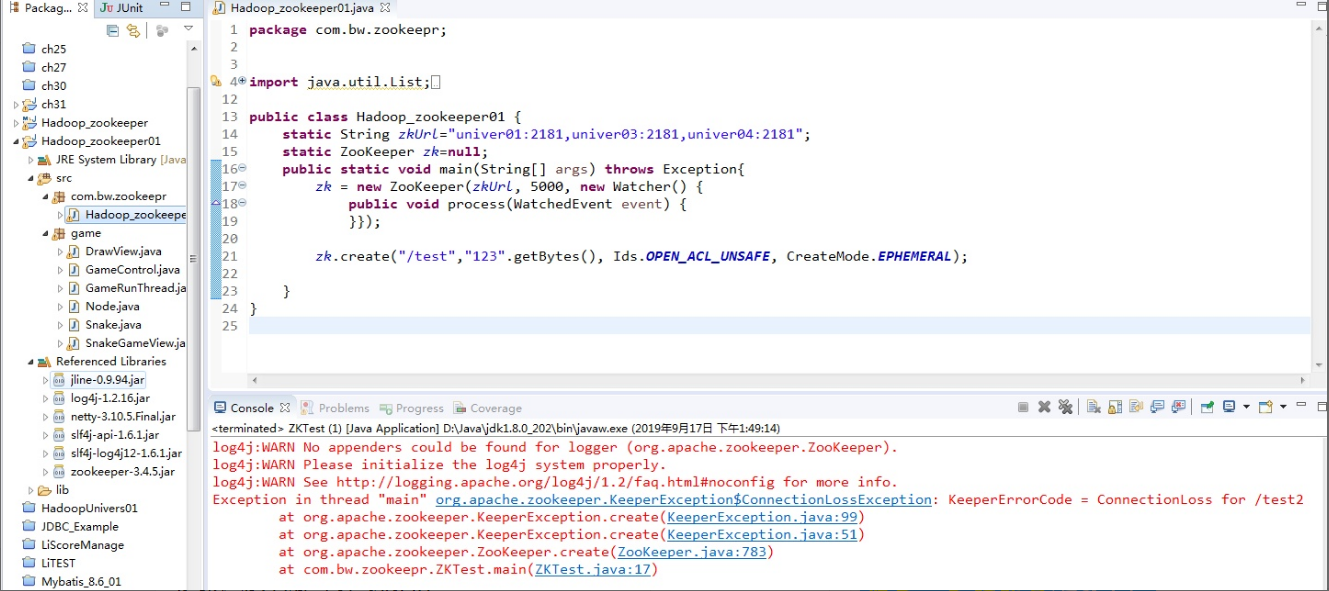
用 zookpeer 的时候出现了这种情况怎么解决?
by
 清与秋
清与秋
https://hainiubl.com/topics/37042?
2019-09-17
⋅
2032
⋅
0
⋅
1
java 里面,'\24'表示什么意思?求大佬解答?
by
 数里淘金
数里淘金
https://hainiubl.com/topics/37043?
2019-09-17
⋅
2773
⋅
0
⋅
1
java里面,'\24'表示什么意思?求大佬解答?
你们的 spark 任务一般跑多久?
by
 矢量
矢量
https://hainiubl.com/topics/37044?
2019-09-18
⋅
2732
⋅
0
⋅
1
你们的spark任务一般跑多久?
kafka connect 做 ETL,会造成数据丢失或重复吗?如果是的话,该怎么解决?
by
 慧有未来
慧有未来
https://hainiubl.com/topics/37045?
2019-09-18
⋅
2872
⋅
0
⋅
1
kafka connect做ETL,会造成数据丢失或重复吗?如果是的话,该怎么解决?
大数据工程师日常都做什么工作呢?
by
 江厌离
江厌离
https://hainiubl.com/topics/37046?
2019-09-19
⋅
2117
⋅
0
⋅
1
每天都在做什么,日常工作如何的呢?工作强度怎么样呢
FLINK 中 AggregateFunction 里面的四个方法中的 merge 方法是做什么用的?
by
 Shihw丶疙瘩
Shihw丶疙瘩
https://hainiubl.com/topics/37047?
2019-09-19
⋅
4265
⋅
0
⋅
2
官方API说是合并累加器,不太明白为什么累加器要合并。
正则表达式中能否进行大小判断 ?
by
 陪你去看海
陪你去看海
https://hainiubl.com/topics/37048?
2019-09-19
⋅
3090
⋅
0
⋅
1
有一系列文件,数量大概4万多,所以不能手工处理,文件名类似404FDAF6BA1317E043E72CCAFF97349611-40.pdf 3BC37F9AF8DA902CD42DCA0B189B75A888-104.pdf 等 最后几位为页码,一般是xxxx-xxxx,位宽不足的没有0填充 试图用正则表达式进行文件重命名,{\d{1,4}}-{\d{1,4}}...
如果没有 cluster,只在本地安装使用 spark,想要处理大数据集(20G+)会对效率有帮助吗?
by
 大地
大地
https://hainiubl.com/topics/37051?
2019-09-23
⋅
2582
⋅
0
⋅
1
如果没有cluster,只在本地安装使用spark,想要处理大数据集(20G+)会对效率有帮助吗?
为什么 pyspark 做 np.array 的迭代计算每个 task 运行速度与分配的 core 成反比?
by
 妞妞
妞妞
https://hainiubl.com/topics/37052?
2019-09-23
⋅
2645
⋅
0
⋅
1
我想把rdd的每一块数据转化为np.array,然后进行迭代计算。对rdd先glom,然后再map。(data_rdd.glom().map(func)) func为迭代函数
python中矩阵计算是并行的,我top了一下,在python下,矩阵计算时大概会调用4个cup。
在pyspark中,我测试了一下,如果每个节点只起...
目前 Hadoop 的前景怎么样?
by
 Wiley
Wiley
https://hainiubl.com/topics/37053?
2019-09-23
⋅
2244
⋅
0
⋅
1
目前Hadoop的前景怎么样?
哪些大数据组件用到了 Python?
by
 眷恋い黯然
眷恋い黯然
https://hainiubl.com/topics/37054?
2019-09-24
⋅
2224
⋅
0
⋅
1
大数据的很多组件都是用 java 开发的,但最近也发现这些大数据组件也用到了 Python,比如 pyspark,phoenix 的命令行工具,有时在 ambari 的界面也会看到一些有关 Python 的错误信息。
所以想知道哪些大数据组件用到了 Python?都用在哪个地方?使用的版本是?
请问,hbase 适合存储大量的 mp4 文件吗?
by
 刘三毛
刘三毛
https://hainiubl.com/topics/37055?
2019-09-24
⋅
2934
⋅
1
⋅
1
想将无人机拍摄的视频文件存储在大数据平台中,不知道hbase是否适合这样使用?
如果没有 cluster,只在本地安装使用 spark,想要处理大数据集(20G+)会对效率有帮助吗?
by
 he12138
he12138
https://hainiubl.com/topics/37056?
2019-09-24
⋅
2178
⋅
0
⋅
1
如果没有cluster,只在本地安装使用spark,想要处理大数据集(20G+)会对效率有帮助吗?
MySQL 数据库,如何根据时间字段,筛选出最新的那条数据?
by
 晓月星稀
晓月星稀
https://hainiubl.com/topics/37057?
2019-09-27
⋅
3008
⋅
1
⋅
1
如下图,accountid为用户字段,需要根据latest_boottime筛选出最大时间的那条数据(latest_boottime字段有空值),我之前用了max,但是查出来的数据有问题,如图2,activetime,sn字段不是最新那条时间的数据。麻烦各位大神帮忙支个招。
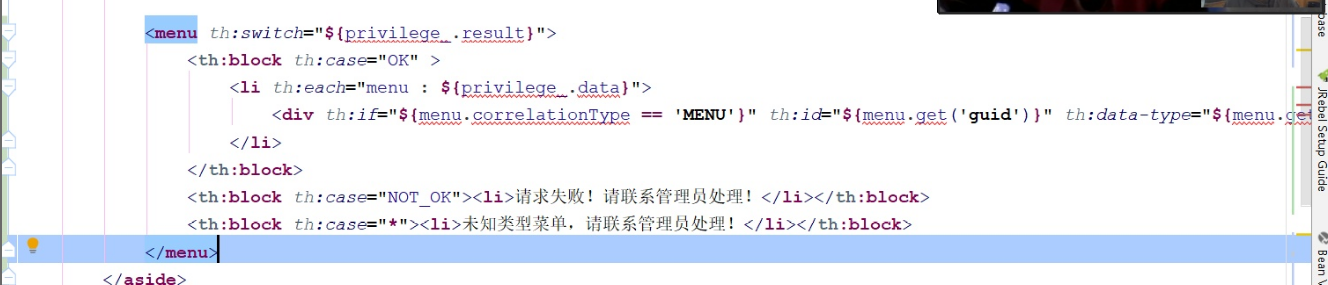
 卢本伟牛X
卢本伟牛X
https://hainiubl.com/topics/37060?
2019-09-29
⋅
2935
⋅
0
⋅
1
请问下为什么在使用thymeleaf的th:each来遍历的时候,会在开始和结束的时候自动添加一个空的<li></li>标签,我用其他方式输出都是正确的,这个找了半天原因没有找到?如下图:
 张凌天
张凌天
https://hainiubl.com/topics/37061?
2019-09-29
⋅
3317
⋅
0
⋅
1
public void finddirnum(DataEntity dataEntity, AtomicLong amount) {
if (dataEntity.isDir()) {
List<DataEntity> list = iDataEntityDao.findAllByParentAndUserId(dataEntity, "0");
for (DataEntity de : list) {
if (de.isDir()) {
finddirnum(de, amount);...
在 HDFS 上建立的文件被存在了哪?
by
 Zxiang
Zxiang
https://hainiubl.com/topics/37062?
2019-09-30
⋅
2164
⋅
0
⋅
1
最近在coursera上上课,跟着学hadoop;有一个部分我有一点疑惑,在下载了hadoop并在HDFS上建立了一个文件,这个文件会存在哪呢?是我本地的某个地方吗?
hive merge mapsfiles 影响 MR 中哪个部分?
by
眷恋い黯然
https://hainiubl.com/topics/37063?
2019-09-30
⋅
6264
⋅
0
⋅
1
为什么?A.sort B.map后 C.spill D.读取源数据
Redis 是怎么管理 session 的?
by
刘三毛
https://hainiubl.com/topics/37064?
2019-09-30
⋅
2000
⋅
0
⋅
1
shiro+redis将session缓存到redis中,设置失效时间。在登录的时候是怎么判断session还在的?
做 hadoop 关机时候应该注意点什么,有时候关机再开机很多东西就没了 ?
by
 匡时济世
匡时济世
https://hainiubl.com/topics/37065?
2019-10-08
⋅
2752
⋅
0
⋅
1
我就知道开机删除data. logs格式化hdfs!但是有时候关机时间长东西还是没或者一些配置莫名其妙变了?大神告诉一下关机之前注意事项!还有像我scp拷贝东西,正常没问题的,配置好时间一长就莫名其妙出问题了啥端口号22拒绝了啥的,也不知道咋改对看了很多有时候挺费劲的...
用 zookpeer 的时候出现了这种情况怎么解决?
by
 Alive
Alive
https://hainiubl.com/topics/37067?
2019-10-09
⋅
2745
⋅
0
⋅
1
main 方法怎么进行数据库存库操作?
by
 jack
jack
https://hainiubl.com/topics/37068?
2019-10-09
⋅
2375
⋅
0
⋅
1
main方法怎么进行数据库存库操作?
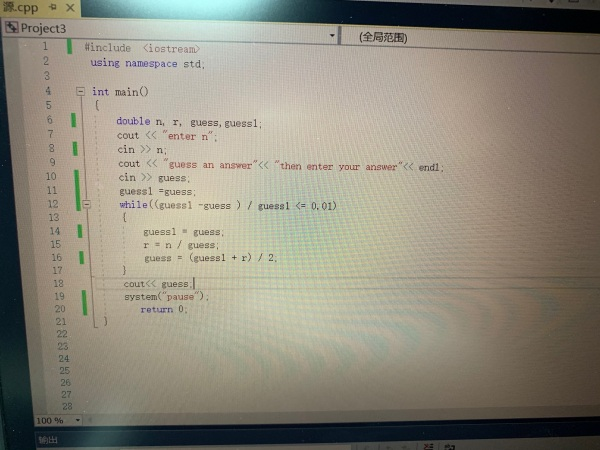
这个巴比伦算法哪里错了,为什么我的 while 语句无法循环?
by
 CrazyStone
CrazyStone
https://hainiubl.com/topics/37069?
2019-10-09
⋅
2203
⋅
0
⋅
1
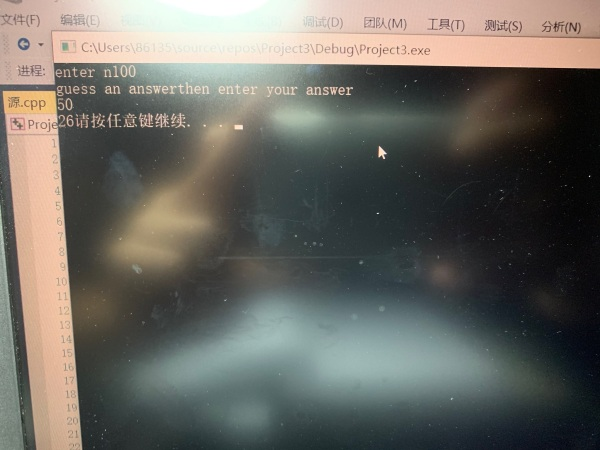
Python 报错'int' object is not subscriptable 怎么办?
by
 Zhbgs2000
Zhbgs2000
https://hainiubl.com/topics/37070?
2019-10-10
⋅
4814
⋅
0
⋅
1
Python报错'int' object is not subscriptable怎么办?
k8s 为什么不用 drf 做调度算法?
by
 会发光的明哥哥
会发光的明哥哥
https://hainiubl.com/topics/37071?
2019-10-10
⋅
2540
⋅
0
⋅
1
dominant resource fairness 算法,启发了很多分布式系统,包括yarn,mesos, 算是集群资源管理的经典算法。为啥 kube-scheduler 里不使用呢?
为什么 SQL SERVER 2000 存储过程修改后不定时会自动还原成修改之前的内容,就像从没修改过?
by
 李伟
李伟
https://hainiubl.com/topics/37072?
2019-10-12
⋅
2834
⋅
0
⋅
1
修改完后检查过存储过程确实已修改并保存,但是过个一天或两天,就自动还原了。