关于 “” 的搜索结果, 共 2411 条
spark 读取 oracle 后,其中有个字段是 xml 的,怎么解析 xml 中的标签啊,求大佬?
by
 冰雹
冰雹
https://hainiubl.com/topics/37139?
2019-11-26
⋅
2823
⋅
0
⋅
1
spark读取oracle后,其中有个字段是xml的,怎么解析xml中的标签啊,求大佬?
Springboot 集成 Swagger2 生成接口文档的时,如何处理通用泛型类返回?
by
 不忘初心
不忘初心
https://hainiubl.com/topics/37140?
2019-11-26
⋅
3893
⋅
0
⋅
1
使用swagger生成接口文档,控制层返回给前端的数据类型统一为String了,需要将 String的内容解释为相关的泛型类
覆盖索引为什么没有回表呢?
by
 张凌天
张凌天
https://hainiubl.com/topics/37141?
2019-11-28
⋅
2593
⋅
0
⋅
1
我们都知道对于主键索引来说,叶子节点存着数据;
对于二级索引来说,叶子节点并不保存数据,而是存着主键索引的键值;
一个走覆盖索引的查询,按我的理解取数据过程是这样的:通过二级索引树上找到对应的主键键值,然后去主键索引树里面取对应的数据。
但是从...
springmvc 返回一个类和我自己将这个类转为 JSON 格式字符串返回有区别吗?
by
 卢本伟牛X
卢本伟牛X
https://hainiubl.com/topics/37142?
2019-11-28
⋅
2280
⋅
0
⋅
1
springmvc返回net.sf.json.JsonObject类型会报一个没有转换器的错
spark 底层是 rdd,flink 底层是怎样的数据结构来维护运算?
by
 ling775000
ling775000
https://hainiubl.com/topics/37143?
2019-11-28
⋅
3054
⋅
0
⋅
1
如题
Python 中类的 call 函数是如何执行的?
by
不忘初心
https://hainiubl.com/topics/37144?
2019-12-02
⋅
2372
⋅
0
⋅
1
看到好多类中都有call函数,但是却没有显示的调用?
python 中 for 循环的值怎么表示与之前的值相等?
by
 晓儒
晓儒
https://hainiubl.com/topics/37145?
2019-12-02
⋅
2624
⋅
0
⋅
1
我想把一个列表中相同的元素移除,但是我不知道怎么写
Python 中如何实现训练集与测试集按顺序划分,而不是随机划分呢?
by
 sqdmydxf
sqdmydxf
https://hainiubl.com/topics/37146?
2019-12-03
⋅
3436
⋅
0
⋅
1
比如说数据是1980-2018年的,我需要按照前面35年为训练集,后面2015-2018这四年为测试集?
数据库或者 MySQL 如何实现表 A 中某个字符串中的子字符串替换为表 B 中的对应的值?
by
 蔡呆呆
蔡呆呆
https://hainiubl.com/topics/37147?
2019-12-03
⋅
2632
⋅
0
⋅
1
表A中name字段可能内容如下: apple, orange. 或者 apple, banana. 表B中name字段是分别是apple, orange, banana, Chinese字段分别是: 苹果, 橘子, 香蕉等几百种水果. 如果把表A中的name字段中的每个字符串的子字符串根据表B的内容替换为对应的中文名. 最好是能只用SQL解...
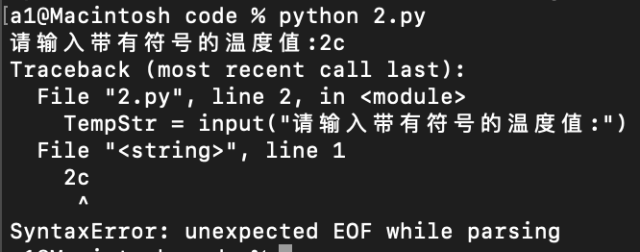
我的这代码为什么报错?
by
 Perry
Perry
https://hainiubl.com/topics/37148?
2019-12-04
⋅
2437
⋅
0
⋅
1
我是mac平台,用的是atom编辑,这个代码是温度转换,求教为什么报错?

java 泛型上界通配符为什么不可以 set?
by
 BOBO
BOBO
https://hainiubl.com/topics/37149?
2019-12-04
⋅
2741
⋅
0
⋅
1
java泛型上界通配符已经描述了类型的顶级父类, 比如 <? extend Food> 可以在set时候将所有的类型向上转型为Food。为什么不可以set呢?
进行 ETL 的时候,用 pandas 和 kettle/Informatica 有什么不同?
by
 矢量
矢量
https://hainiubl.com/topics/37150?
2019-12-05
⋅
3366
⋅
0
⋅
1
他们的侧重点在哪里?
Flink 批处理完成后,我怎么得到通知?
by
 慧有未来
慧有未来
https://hainiubl.com/topics/37151?
2019-12-05
⋅
2951
⋅
0
⋅
1
比如说回调我的rest接口,或者写个消息到消息队列,有什么可行的方法吗?另外我试过写进MQ,但集群模式提交不起作用,本地测试才有效
zookeeper 完全分布式配置时,集群会使用什么端口?
by
 高文超
高文超
https://hainiubl.com/topics/37152?
2019-12-06
⋅
2276
⋅
0
⋅
1
zookeeper完全分布式配置时,集群会使用什么端口?
python 定义一个类,类里有一个实例属性是关于时间的,怎么样写才能让这个属性根据时间变化?
by
 那些年后会有期
那些年后会有期
https://hainiubl.com/topics/37153?
2019-12-06
⋅
2167
⋅
0
⋅
1
关于这个问题,我写了个简单的实例。下边的实例每次都是打印的时间是一样的,怎么才能打印当时的时间
import time
import schedule
class ShortMessage:
def __init__(self, message_time=None):
self.message_time = message_time
if self.message_time...
为什么说 Hadoop 是一个生态系统?
by
sqdmydxf
https://hainiubl.com/topics/37154?
2019-12-09
⋅
2580
⋅
0
⋅
1
为什么说Hadoop是一个生态系统?
Hadoop 除了 Hbase 是否支持其它数据库?
by
蔡呆呆
https://hainiubl.com/topics/37155?
2019-12-09
⋅
2624
⋅
0
⋅
1
Hadoop除了支持Hbase外,是否支持其它的数据用于替代Hbase?比如能否用Oracle、SQL、Mongodb?
多 hive 表关联成一张大表,表的大小差距比较大,如何提效?
by
 九月
九月
https://hainiubl.com/topics/37158?
2019-12-11
⋅
2727
⋅
0
⋅
1
多hive表关联成一张大表,表的大小差距比较大,如何提效?
map/reduce 过程,如何用 map/reduce 实现两个数据源的联合统计?
by
 街角缠绵
街角缠绵
https://hainiubl.com/topics/37159?
2019-12-11
⋅
2682
⋅
0
⋅
1
map/reduce过程,如何用map/reduce实现两个数据源的联合统计?
python colorama 模块不能正常输出颜色怎么解决?
by
 liuye
liuye
https://hainiubl.com/topics/37160?
2019-12-12
⋅
2877
⋅
0
⋅
1
代码:

结果:

Hadoop 单机模式搭建和伪分布式搭建的区别主要有哪些?
by
 大地
大地
https://hainiubl.com/topics/37161?
2019-12-12
⋅
2610
⋅
0
⋅
1
Hadoop单机模式搭建和伪分布式搭建的区别主要有哪些?
Hadoop 单机模式搭建和伪分布式搭建的区别主要有哪些?
by
 Phyllis2016
Phyllis2016
https://hainiubl.com/topics/37163?
2019-12-13
⋅
2354
⋅
0
⋅
1
Hadoop单机模式搭建和伪分布式搭建的区别主要有哪些?
hive 中创建外部表时 location 如何指定数个位置?
by
高文超
https://hainiubl.com/topics/37164?
2019-12-13
⋅
3753
⋅
0
⋅
1
因为数据本身动态的存储于hdfs中两个不同的位置,创建外部表时希望指定location同时读取两个位置的数据,若其中一个位置没有数据的话则读取另一个,想请教如何指定location才好?
如何在 spark 中集成 lightGBM,做大批量数据建模?
by
矢量
https://hainiubl.com/topics/37165?
2019-12-17
⋅
3276
⋅
0
⋅
1
最近公司有个需求,需要对100GB+的数据做ETL,然后做分类建模,并且能够对建模后的模型结果做出解释,于是选择了优秀的lightGBM。在网上找了很多资料,没有找到一个清晰的将lightGBM和spark结合的方法和示例,麻烦知乎的大佬给些指导,谢谢~~
Java 中的 Collection 为什么设计成接口而非抽象类?
by
慧有未来
https://hainiubl.com/topics/37166?
2019-12-17
⋅
2625
⋅
0
⋅
2
作为单列集合这个事物的抽象,为什么不设计成抽象类而要设计成接口?
[新手必读] 大数据的现在与将来
by
 青牛
青牛
https://hainiubl.com/topics/37174?
2019-12-19
⋅
5976
⋅
9
⋅
2
同学们,你们既然选择学习大数据,就要先了解一下,目前大数据的应用场景,目前大数据广泛应用于互联网,比如我们经常使用的微信,今日头条,抖音,淘宝等,在这些应用中我们经常能看到我们被精准推荐了某个广告。
其实大数据的应用不止是互联网,还有很多场景...
Yarn 的出现到底给 MapReduce、Spark 等带来了什么?
by
 李伟
李伟
https://hainiubl.com/topics/37175?
2019-12-20
⋅
2579
⋅
0
⋅
1
好多MapReduce On Yarn , Spark On Yarn
可是没有yarn, MapReduce Spark 不是一样跑
spark 如何和 yarn 结合的?
by
 镜花水月
镜花水月
https://hainiubl.com/topics/37176?
2019-12-20
⋅
2341
⋅
0
⋅
1
总所周知,yarn是一个资源调度器,能够让各种计算框架运行在之上,例如spark,mapreduce. 那么问题就来了,就拿spark来举例,spark是如何和yarn结合的,将用户开发的程序放到yarn上运行的。这里我不是问yarn-client提交的流程哈, 我是想表达,例如AM,spark是如何去初...
yarn 与 hdfs 的关系?
by
 我是小小美食家
我是小小美食家
https://hainiubl.com/topics/37177?
2019-12-20
⋅
3074
⋅
0
⋅
1
如果打算使用yarn,在上面跑storm,或者spark,安装yarn时,一定要安装hdfs或启动hdfs么?看各种资料,启动yarn时,都要连带着启动hdfs,他们之间到底什么关系。
Java 程序每次运行都需要编译一次吗?
by
 0123
0123
https://hainiubl.com/topics/37178?
2019-12-21
⋅
2462
⋅
0
⋅
1
Java程序每次运行都需要编译一次吗?