关于 “” 的搜索结果, 共 2411 条
spark 的核心设计思想是什么?
by
 冰雹
冰雹
https://hainiubl.com/topics/37106?
2019-11-05
⋅
2593
⋅
0
⋅
1
spark的核心设计思想是什么?
Hive MetaStore 引入的背景是什么?为什么要使用 Hive MetaStore?
by
 不忘初心
不忘初心
https://hainiubl.com/topics/37107?
2019-11-05
⋅
2360
⋅
0
⋅
1
Hive MetaStore引入的背景是什么?为什么要使用Hive MetaStore?
大数据技术平台有哪些?
by
 晓儒
晓儒
https://hainiubl.com/topics/37108?
2019-11-05
⋅
2358
⋅
0
⋅
1
大数据技术平台是指Hadoop这些吗?还是大数据技术平台与大数据平台有区别吗?搞蒙了
python 如何实现查询 sql 数据库并生成 HTML 文件?
by
 卢本伟牛X
卢本伟牛X
https://hainiubl.com/topics/37110?
2019-11-06
⋅
2909
⋅
0
⋅
1
python如何实现查询sql数据库并生成html文件?
spark 如何和 yarn 结合的?
by
 张凌天
张凌天
https://hainiubl.com/topics/37111?
2019-11-06
⋅
2040
⋅
0
⋅
1
总所周知,yarn是一个资源调度器,能够让各种计算框架运行在之上,例如spark,mapreduce. 那么问题就来了,就拿spark来举例,spark是如何和yarn结合的,将用户开发的程序放到yarn上运行的。这里我不是问yarn-client提交的流程哈, 我是想表达,例如AM,spark是如何去初...
Sql 批量查询某一字段,如果某一值没有则整个结果就不返回任何记录,请问有什么合适的函数能替代 IN 吗?
by
 Colen
Colen
https://hainiubl.com/topics/37112?
2019-11-07
⋅
2771
⋅
0
⋅
1
有个SQL筛选逻辑想请教一下:
有语句 SELECT id FROM table_a WHERE id IN(1,2,3,9999);
以上SQL由于id 1,2,3存在table_a表中,只有9999不存在,所以结果集能返回id为1,2,3的记录;
我这儿有个需求要这样做,如果table_a表id不包含9999,则整个结果集就不返回...
MySQL 千万数据 count + where 查询慢如何解决?
by
 风口浪尖
风口浪尖
https://hainiubl.com/topics/37113?
2019-11-07
⋅
3334
⋅
0
⋅
1
Mysql千万级别数量,使用索引过滤后查询数据最大单元仍会有几百万数据量,count + where和select offset 5000000极慢如何解决?
JAVA 安装时为什么要手动配环境变量?
by
风口浪尖
https://hainiubl.com/topics/37114?
2019-11-12
⋅
2460
⋅
0
⋅
1
JAVA为啥不像Python或golang那样安装包自动配置好环境变量,而是要使用者手动添加呢,配置环境变量那部看起来也不复杂啊
PostgreSQL 为什么删除了数据库以后,里面的表还在?
by
 蓝天
蓝天
https://hainiubl.com/topics/37115?
2019-11-12
⋅
2839
⋅
0
⋅
1
新手小白,刚刚开始学习psql,先建了数据库 shop,又建表product。然后手欠drop database shop 。完了发现那表product还在。莫名很懵逼。。。想知道表为什么没有跟数据库shop一块删掉。
这个表既然还存在,那现在是在哪个数据库里?我只建了一个数据库。。。小白表示...
kafka 在量化交易程序中有用吗?
by
 Shihw丶疙瘩
Shihw丶疙瘩
https://hainiubl.com/topics/37116?
2019-11-12
⋅
2428
⋅
0
⋅
1
kafka在量化交易程序中有用吗?
MySQL 一张表根据时间做了分区和子分区后,存百亿数据会不会有问题?
by
 陪你去看海
陪你去看海
https://hainiubl.com/topics/37117?
2019-11-12
⋅
2483
⋅
0
⋅
1
MySql一张表根据时间做了分区和子分区后,存百亿数据会不会有问题?
分区按年做,子分区按月做,每月数据量基本一致,大概在5000W左右。几年下来数据会在几十亿,所以干脆问100亿数据量,只做这么一张表可行否?
Python 中 /,//,*,**,%运算符的作用各是什么?
by
 张小果
张小果
https://hainiubl.com/topics/37118?
2019-11-13
⋅
2708
⋅
0
⋅
1
Python中/,//,*,**,%运算符的作用各是什么?
Python 如何高效省时将几十亿行数据中的某一列保存到另一文件中?
by
 肖海艳
肖海艳
https://hainiubl.com/topics/37119?
2019-11-13
⋅
2664
⋅
0
⋅
1
我试着用csv的readline循环读,每次每一千万行。结果跑了一晚上十几个小时只写进了一亿数据。我发现读的速度其实是很快的,但是写的速度,一小时不到一千万的那种。我看网上讨论的大数据读取使用panda,但很少谈到写入的
怎么数据库建立表示一直出现 can't create table (errno: 150) 错误?
by
 浅唱
浅唱
https://hainiubl.com/topics/37120?
2019-11-14
⋅
2804
⋅
0
⋅
1
我查看了我所要创建的外键和主键的类型,和编码的格式也没发现不对的地方,但是还是建表失败,这是图书代码
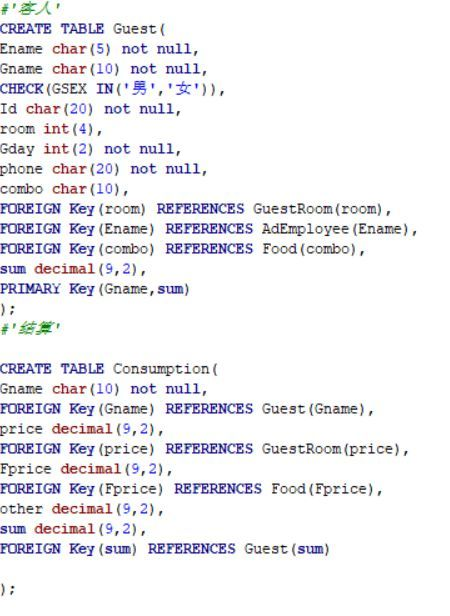
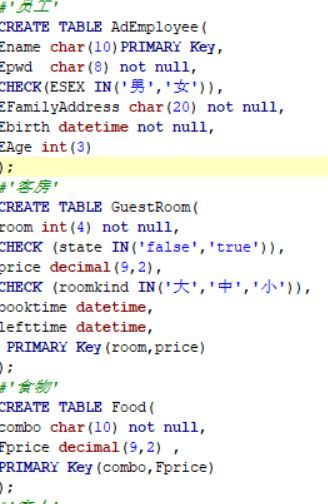...
zookeeper 客户端报以下错误,是什么原因导致?
by
 广广
广广
https://hainiubl.com/topics/37121?
2019-11-14
⋅
2163
⋅
0
⋅
1
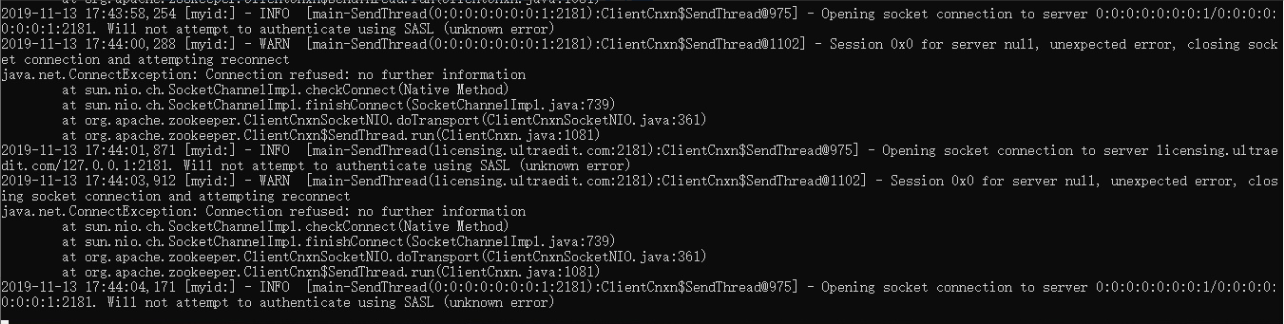
flink 消费 kafka,保证数据不丢失且只消费一次语义,也要像 sparkstreaming 一样手动管理 offset 吗?
by
 ling775000
ling775000
https://hainiubl.com/topics/37123?
2019-11-14
⋅
5328
⋅
0
⋅
1
还是flink自己可以有办法处理
怎么数据库建立表示一直出现 can't create table (errno: 150) 错误?
by
 李鴻飛
李鴻飛
https://hainiubl.com/topics/37124?
2019-11-15
⋅
2738
⋅
0
⋅
1
我查看了我所要创建的外键和主键的类型,和编码的格式也没发现不对的地方,但是还是建表失败,这是图书代码
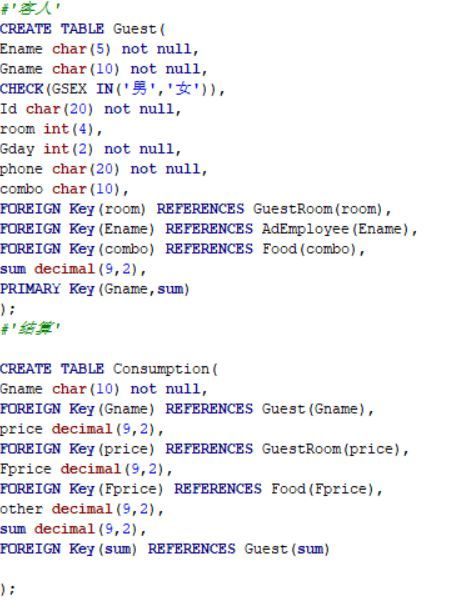
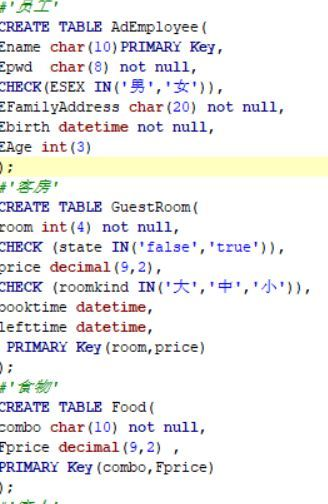...
zookeeper 客户端报以下错误,是什么原因导致?
by
 风吹过
风吹过
https://hainiubl.com/topics/37125?
2019-11-15
⋅
2104
⋅
0
⋅
1
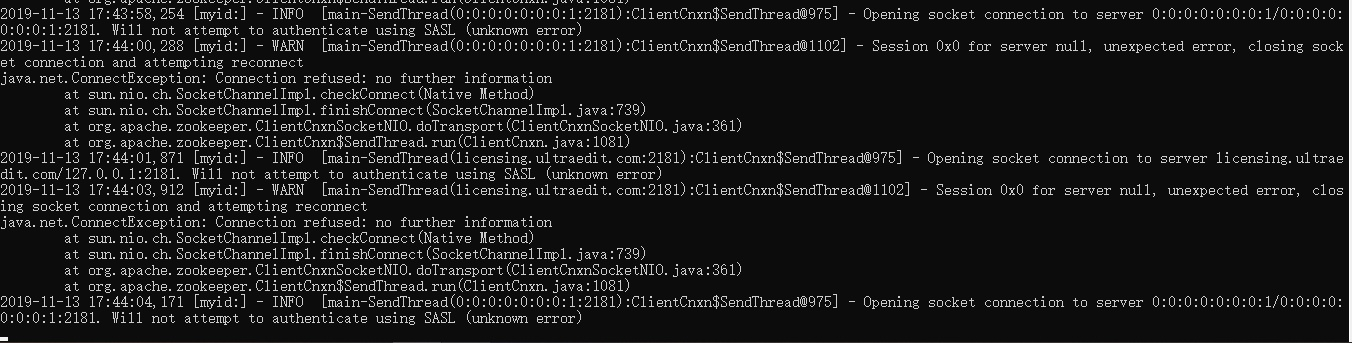
在 scala 中 Future [Try [T]] 与 Try [Future [T]] 有什么区别?
by
 街角缠绵
街角缠绵
https://hainiubl.com/topics/37126?
2019-11-15
⋅
2753
⋅
0
⋅
1
在scala中Future[Try[T]]与Try[Future[T]]有什么区别?
Python 将字符串写入文件时出现问题,应该怎么解决?
by
 那些年后会有期
那些年后会有期
https://hainiubl.com/topics/37127?
2019-11-18
⋅
2291
⋅
0
⋅
1
比如我要把"6-22"写入csv文件,结果在csv文件中显示为6月22日
kafka 为什么要实现自己的 channel?
by
 半杯湖底沙
半杯湖底沙
https://hainiubl.com/topics/37128?
2019-11-18
⋅
2399
⋅
0
⋅
1
kafka 为什么要实现自己的channel?
python 中如何隐藏 cmd 返回的提示?
by
 Wiley
Wiley
https://hainiubl.com/topics/37129?
2019-11-19
⋅
3123
⋅
0
⋅
1
各位大哥你们好,我将要运行一下命令:
shell_cmd = 'ffmpeg -ss 00:%s -i \"%s\" -to 00:%s -c copy \"%s\"'%(time_pt_ms,file_path_message,time_pw,out_dir_tmp)
os.system(shell_cmd)
 Phyllis2016
Phyllis2016
https://hainiubl.com/topics/37130?
2019-11-19
⋅
2692
⋅
0
⋅
1
如题, 在集群部署python时,有没有批量安装模块的方法呢
在 Spark 的 MLlib 中,不同的 distributed matrix 提供的计算接口为什么不一致呢?
by
 我是小小美食家
我是小小美食家
https://hainiubl.com/topics/37132?
2019-11-20
⋅
2615
⋅
0
⋅
1
比如RowMatrix和IndexRowMatrix提供了computeSVD方法,而CoordinateMatrix和BlockMatrix却不支持,这是为什么呀?
scala 是否有 spring cloud 套件?比如 scala 版本的 eurake,fegin 这些?
by
 矢量
矢量
https://hainiubl.com/topics/37133?
2019-11-21
⋅
2489
⋅
0
⋅
1
scala是否有spring cloud套件?比如scala版本的eurake,fegin这些?
有没有大佬帮我看一下,为什么我这么写了 table 中没有数据显示啊,本人萌新一枚,求教~?
by
 慧有未来
慧有未来
https://hainiubl.com/topics/37134?
2019-11-21
⋅
2641
⋅
0
⋅
1
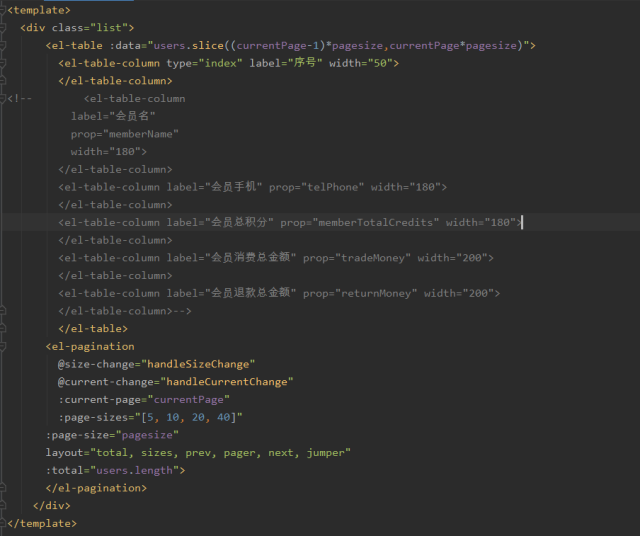
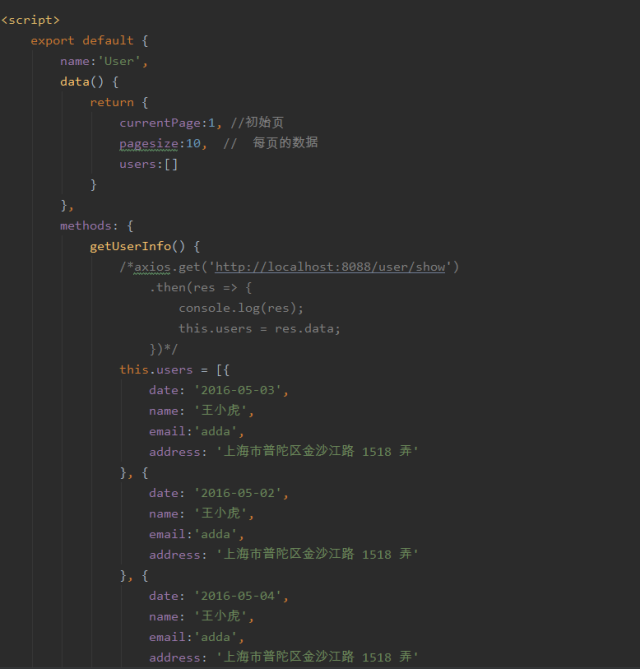
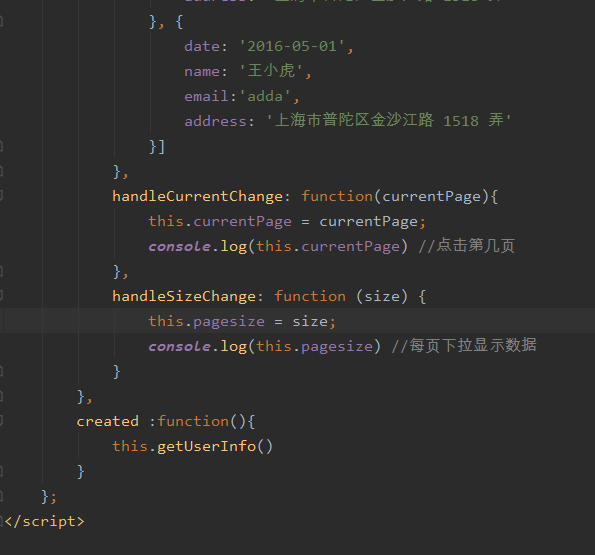
 需要做哪些优化?
by
 咻咻
咻咻
https://hainiubl.com/topics/37135?
2019-11-22
⋅
3028
⋅
0
⋅
1
1000节点的大数据集群(hadoop,spark)需要做哪些优化?
1.整体集群组件架构大方向上的优化和设计?
2.hdfs,yarn,zookeeper重要指标的调参?
3.你在大集群使用,运维,优化中遇到的大坑有啥?
同一个 spark 项目中可以混用 python 和 scala 吗,有没有尝试过的大佬来交流下?
by
 刘玉星
刘玉星
https://hainiubl.com/topics/37136?
2019-11-22
⋅
2682
⋅
0
⋅
1
比如说离线模块用python,在线模块用scala。之间的rdd调用会产生影响吗
设置了 pythonpath 环境变量,程序中无法读出来,这是什么原因?
by
 许宁
许宁
https://hainiubl.com/topics/37137?
2019-11-25
⋅
2517
⋅
0
⋅
1
windows系统设置了pythonpath环境变量,执行python程序时,sys.path未读取不到所设置的环境变量