关于 “” 的搜索结果, 共 2411 条
CDH 平台 篇
by
 阿布都的都
阿布都的都
https://hainiubl.com/topics/76141?
2023-01-09
⋅
2116
⋅
0
⋅
0
**配套笔记课件地址:**
1. 大数据平台概述:http://www.hainiubl.com/topics/76029
2. cdh大数据平台搭建:http://www.hainiubl.com/topics/76030
3. kerberos和sentry部署:http://www.hainiubl.com/topics/76031
4. kerberos与sentry原理及使用:http://www.hain...
Scala 篇(野牛主讲)
by
阿布都的都
https://hainiubl.com/topics/76142?
2023-01-09
⋅
1836
⋅
0
⋅
0
**配套笔记课件地址:**
1. scala:http://www.hainiubl.com/topics/76104
**[海汼部落云平台](https://cloud.hainiubl.com)**产品使用教程:https://www.hainiubl.com/topics/76618
Spark 篇(野牛主讲)
by
阿布都的都
https://hainiubl.com/topics/76143?
2023-01-09
⋅
2089
⋅
0
⋅
0
**配套笔记课件地址:**
1. spark:http://www.hainiubl.com/topics/76146
**[海汼部落云平台](https://cloud.hainiubl.com)**产品使用教程:https://www.hainiubl.com/topics/76618
Flink 篇(野牛主讲)
by
阿布都的都
https://hainiubl.com/topics/76144?
2023-01-09
⋅
2050
⋅
0
⋅
0
**配套笔记课件地址:**
1. flink:http://www.hainiubl.com/topics/76113
2. flinkcep:http://www.hainiubl.com/topics/76106
3. flinksql:http://www.hainiubl.com/topics/76107
**[海汼部落云平台](https://cloud.hainiubl.com)**产品使用教程:https://www....
1.spark3(野牛主讲)
by
阿布都的都
https://hainiubl.com/topics/76146?
2023-01-09
⋅
2293
⋅
0
⋅
0
# 1 spark 概述
## 1.1 Spark产生的背景
MapReduce的局限性:
1)仅支持Map 和 Reduce 两种操作;
2)MapReduce多个任务的中间结果落地磁盘,不能充分利用内存,任务运行效率低;
3)适合批处理,不适合实时性要求高的场景;
4)程序编写过于复...
Python 篇
by
阿布都的都
https://hainiubl.com/topics/76147?
2023-01-09
⋅
1815
⋅
0
⋅
0
**配套笔记课件地址:**
1. python开发环境安装与python基础1:http://www.hainiubl.com/topics/76119
2. python基础2:http://www.hainiubl.com/topics/76120
3. 多线程:http://www.hainiubl.com/topics/76121
4.日志模块和实现多线程并发框架:http://www.hainiu...
[教程] Hadoop 教程(Hadoop3.x 从部署到源码分析全套讲解)
by
 青牛
青牛
https://hainiubl.com/topics/76148?
2023-01-10
⋅
7516
⋅
5
⋅
3
> Hadoop作为大数据软件体系的开山之作,自然是学习大数据必经之路,学好便可打通仁通二脉,为接下来学习任何大数据软件打下坚固的基础。
本教程配备免费云坏境,可快速演练Hadoop分布式存储与计算特点。让大数据初学者彻底告别学习大数据止步于集群搭建的烦恼,不需要...
1-MySQL 介绍 DDL,DML,DQL 操作
by
 薪牛
薪牛
https://hainiubl.com/topics/76149?
2023-01-10
⋅
2227
⋅
0
⋅
0
# 1 数据库基本概念
## 1.1 数据库
数据库产生背景:
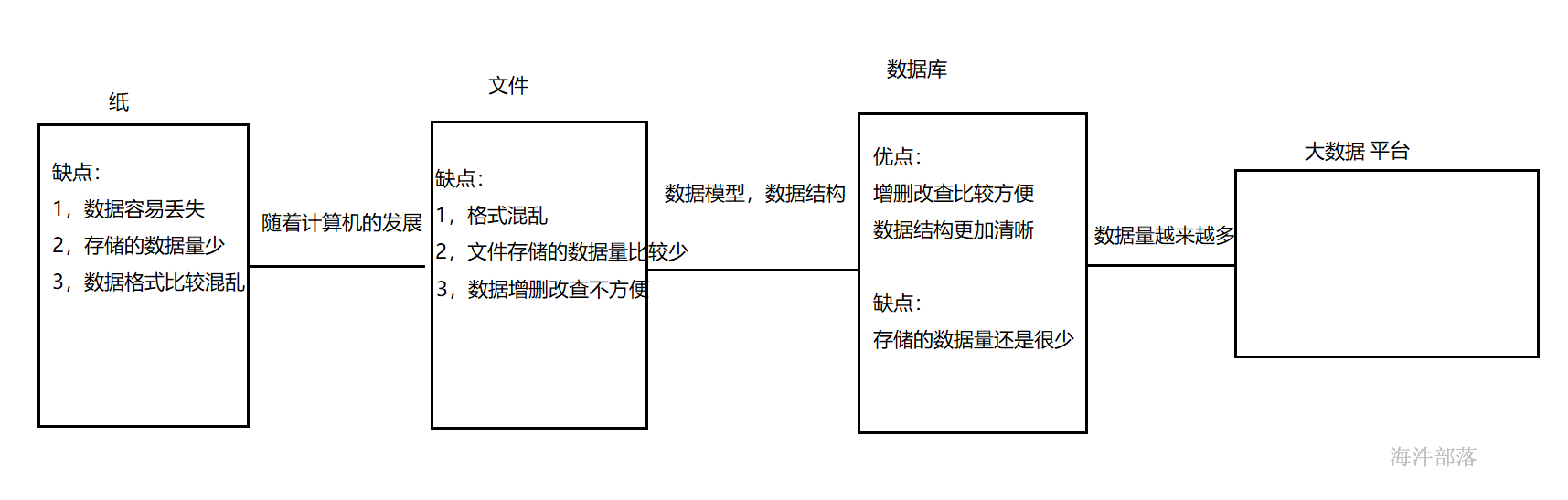
数据库就是存储数据的仓库,数据按照特定的格式将数据存储起来,用户可以对数据库中的数据进行增加,修改,删...
2-MySQL 约束,视图,索引及常见函数
by
薪牛
https://hainiubl.com/topics/76150?
2023-01-10
⋅
2033
⋅
0
⋅
0
# 1 SQL约束
SQL 约束用于规定表中的数据规则。实际上就是表中数据的限制条件。是**为了保证数据的完整性**而实现的一套机制。
MySQL的约束种类如下:
- 非空约束:NOT NULL
NOT NULL约束强制该字段不接受 NULL 值。
- 唯一约束:UNIQUE
UNIQUE 约束唯一标识数据...
3-MySQL jdbc,事务,连接池
by
薪牛
https://hainiubl.com/topics/76151?
2023-01-10
⋅
1878
⋅
1
⋅
0
# 1 jdbc
## 1.1 jdbc概述
JDBC(Java DataBase Connectivity,java数据库连接技术)是一种用于执行SQL语句的Java API。
JDBC是Java访问数据库的标准规范,可以为不同的关系型数据库提供统一访问,它由一组用Java语言编写的接口和类组成。
J...
[教程] MySQL 教程(从原理解析到在线实战,踩破技术天花板)
by
青牛
https://hainiubl.com/topics/76152?
2023-01-11
⋅
3847
⋅
1
⋅
0
> Mysql是一个传统关系型数据库常作为其它大数据组件的配置存储服务,也做为数仓系统中的汇总结果存储,同时也是数仓中字典表与实体表的数据来源,可见其用途之广泛。所以也是想学习大数据的小伙伴们的必修技术。
本课程从多种SQL经典案例入门贯穿mysql的学习过程,并...
Mapreducer 之 mapper
by
 DER
DER
https://hainiubl.com/topics/76154?
2023-01-11
⋅
2000
⋅
1
⋅
0
# MapReducer之Mapper
## **1.背景**
1)海量数据在单机上处理因为硬件资源限制,无法胜任;
2)将单机版程序扩展到集群来分布式运行,极大增加程序的复杂度和开发难度;
3)引入 MapReduce 框架后,开发人员可以将绝大部分工作集中在...
Mapreducer 之 reducer
by
DER
https://hainiubl.com/topics/76155?
2023-01-11
⋅
1873
⋅
0
⋅
0
# Mapreducer之reducer
## 1.reducer的功能
经过以上部分的讲解和使用,我们已经知道了mapper的功能和使用场景,但是reducer部分还没有接触,现在我们针对reducer部分进行使用和练习
mapreducer主要是分为两个部分,mapper和reducer部分,其中mapper主要负责单个文件...
mapreduce 优化和执行
by
DER
https://hainiubl.com/topics/76156?
2023-01-11
⋅
1853
⋅
0
⋅
0
## mapreduce优化和执行
## 1.mapreduce的配置
```xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compli...
01 hive 介绍与安装
by
薪牛
https://hainiubl.com/topics/76157?
2023-01-17
⋅
3434
⋅
3
⋅
0
# 1 hive介绍与原理分析

Hive是一个**基于**Hadoop的开源数据仓库工具,用于存储和处理海量结构化数据。它是Facebook 2008年8月开源的一个数据仓库框架,提供了类似于...
02 hive 数据类型、运算符、建库、建表
by
薪牛
https://hainiubl.com/topics/76158?
2023-01-17
⋅
2822
⋅
1
⋅
0
# 1 数据类型
## 1.1 基本类型
| 数据类型 | 大小 | 范围 | 示例 |
| ----------- | ----- | ------------------------------------------------------ | ------------ |
| TINYINT | 1byte | -12...
03 hive 的表操作、数据加载、导出
by
薪牛
https://hainiubl.com/topics/76159?
2023-01-17
⋅
2419
⋅
3
⋅
0
# **1 表SQL操作**
## 1.1 通过select数据集创建表
```sql
--通过select数据集创建表语法格式
create table table_name [stored as orc]
as
select ......
```
只能是内部表,不支持分区,分桶
示例:
```sql
--创建内部表inner_test1
create table inner_...
04 hive 的 select、union、join、grouping sets
by
薪牛
https://hainiubl.com/topics/76160?
2023-01-17
⋅
2186
⋅
0
⋅
0
# 1 HIVE SELECT 语法
```sql
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY co...
05 hive 的排序、窗口函数用法、UDF 函数、hive 优化
by
薪牛
https://hainiubl.com/topics/76161?
2023-01-17
⋅
2812
⋅
1
⋅
0
# 1 排序

**order by**
会对输入做全局排序,因此只有一个reducer。
设置reduce个数没用
order by 在hive.mapred.mode = strict 模式...
06 hive 面试题
by
薪牛
https://hainiubl.com/topics/76162?
2023-01-17
⋅
2240
⋅
0
⋅
0
* # 数据准备
1. 建表
```sql
create table dept (deptid int ,deptname string,address string);
create table emp(empid int ,empname string,salary DECIMAL ,ruzhidate date,mgr int,deptid int);
```
2. 插入数据
```sql
insert into dept values(1,'研发...
[教程] Hive 教程(Hive3.x 从基础到优化到面试一套全搞定)
by
青牛
https://hainiubl.com/topics/76163?
2023-01-18
⋅
11065
⋅
4
⋅
18
> Hive是基于Hadoop的大数据SQL处理引擎,有了它用SQL也能处理大数据,企业中常用于数据仓库中的数据计算,它能让大数据处理变的十分简单,所以非常受企业的欢迎。并且好多支持sql的大数据组件都使用hive的元库,所以说学习hive是入行大数据的必修课程。
**前置知识...
1.Hbase 安装和 DDL
by
DER
https://hainiubl.com/topics/76165?
2023-01-19
⋅
2778
⋅
1
⋅
0
# Hbase安装和DDL
## 1.hbase的简述
在学习hbase之前同学们已经学习完毕了hdfs和yarn以及mr,hbase作为google的大数据三篇比较重要的论文之一,它的起源叫做bigtable,意思非常简单就是大表的意思,是一个分布式存储很多数据的大型表格系统,它是对于hdfs中的数据...
2.hbase 的架构和读写流程
by
DER
https://hainiubl.com/topics/76166?
2023-01-19
⋅
2304
⋅
1
⋅
0
## hbase的架构和读写流程
## 7.hbase的整体架构
hbase的region存储原理图
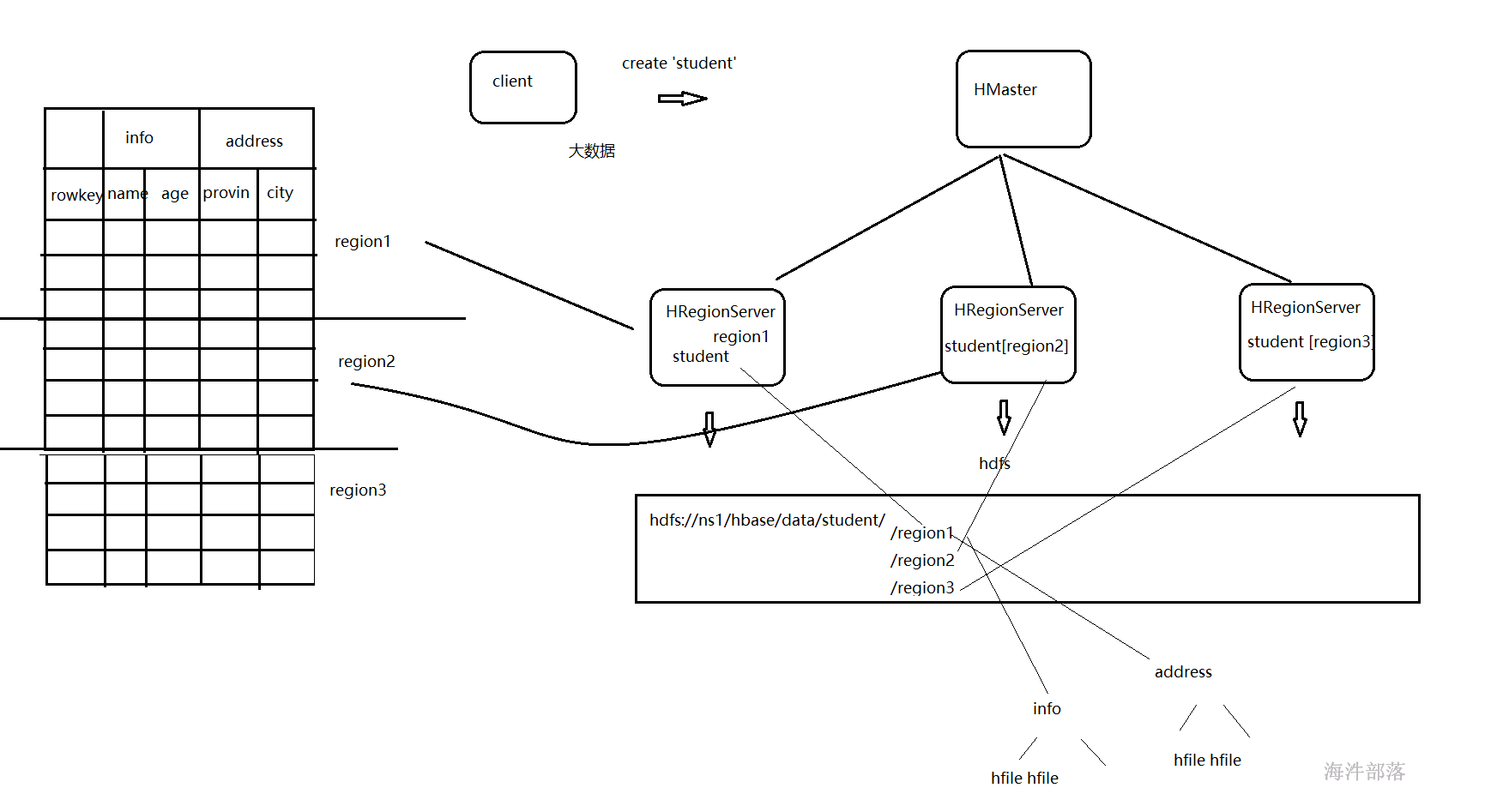

by
青牛
https://hainiubl.com/topics/76170?
2023-01-29
⋅
8764
⋅
4
⋅
10
> HBase是一个可以存储大量数据的NoSql数据库,可以用rowKey的形式快速的获取数据,有了它对大数据的计算结果的快速存取就方便了很多。本课程里不仅讲解了HBase的安装与原理,还增加了MR读写HBase、bulkload批量导入、结合phoenix的sql引擎操作HBase、HBase做为hive的外...
1 flume 介绍,安装,常见 source
by
薪牛
https://hainiubl.com/topics/76171?
2023-02-02
⋅
2713
⋅
3
⋅
0

# 1 flume概述
Flume是cloudera(**CDH版本的hadoop**) 开发的一个分布式、可靠、高可用的海量日志收集系统。它将各个服务器中的数据收集起来并送到指定的地方去,...
2 flume 常见 channel、sink
by
薪牛
https://hainiubl.com/topics/76172?
2023-02-02
⋅
2270
⋅
1
⋅
0
# 1 flume 常见channel介绍
Channel是连接Source和Sink的组件,大家可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件,Flume对于Channel,则提供了Memory Channel、JDBC Chanel、File Channel...
3 flume Sink Processors 、Interceptor
by
薪牛
https://hainiubl.com/topics/76173?
2023-02-02
⋅
2007
⋅
0
⋅
0
# 1 Flume Sink Processors
## 1.1 Failover Sink Processor
故障转移处理器可以同时指定多个sink输出,按照优先级高低进行数据的分发,并具有故障转移能力
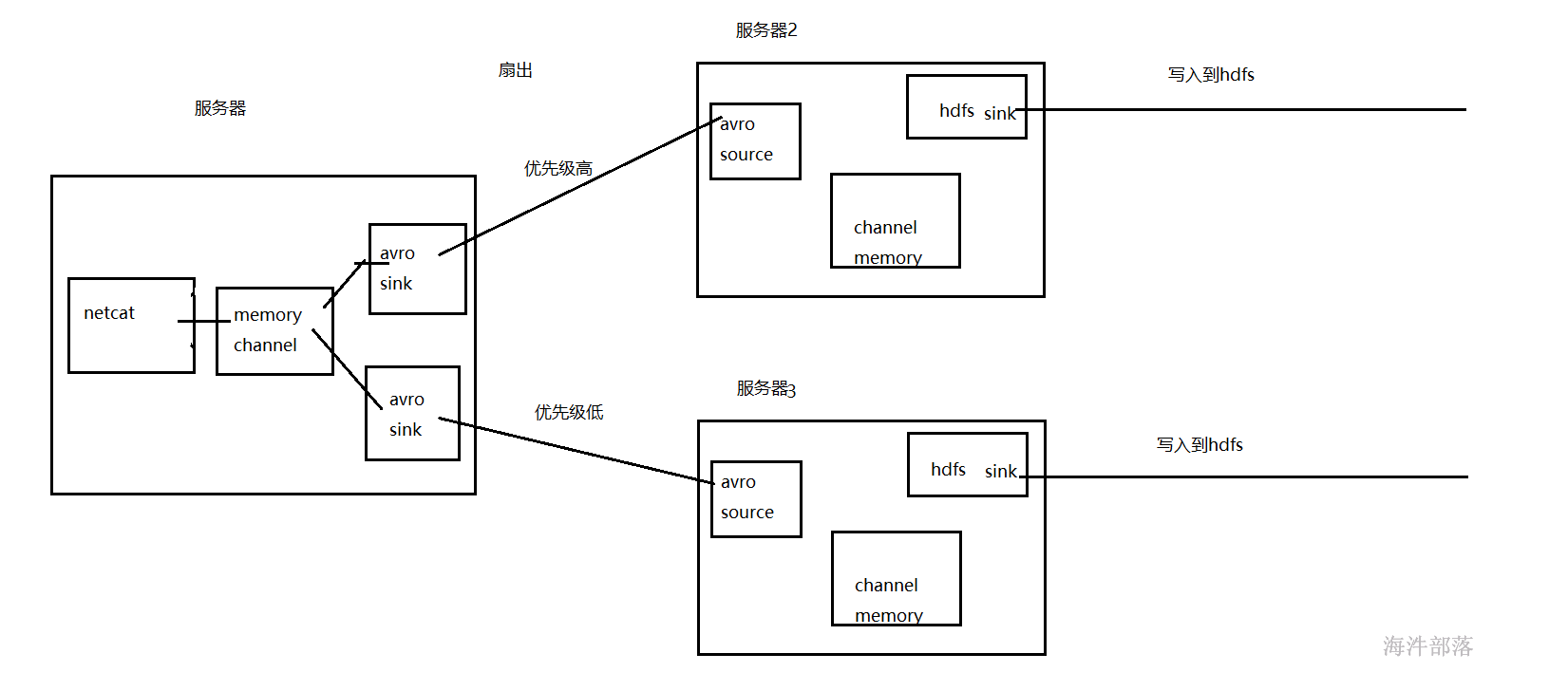
需...