解决分布式一致性问题,即一个分布式系统中的各个进程如何就某个值达成一致
Paxos中的角色
- Proposer: 提出提案 (Proposal)。Proposal信息包括提案编号 (Proposal ID) 和提议的值 (Value)。
- Acceptor:参与决策,回应Proposers的提案。收到Proposal后可以接受提案,若Proposal获得多数Acceptors的接受,则称该Proposal被批准。
- Learner:不参与决策,从Proposers/Acceptors学习最新达成一致的提案(Value)。
Paxon中通过决议的核心分为两个阶段
- 第一阶段:Prepare阶段。Proposer向Acceptors发出Prepare请求,Acceptors针对收到的Prepare请求进行Promise承诺。
- 第二阶段:Accept阶段。Proposer收到多数Acceptors承诺的Promise后,向Acceptors发出Propose请求,Acceptors针对收到的Propose请求进行Accept处理。
P0:当集群中,超过半数的Acceptor接受了一个议案,那么这个议案就被选定了
默认:每个提案都具备id和value,其中id是递增的
问题分析
Proposal很多,Acceptor有人不接受议案,Acceptor接受的选择并不集中,结果没有任何一个议案形成多数派
问题处理
- 每个Acceptor必须接受一个议案
- 允许一个Acceptor接收多个议案,后接受的议案可以覆盖掉之前接受的议案
问题分析
Acceptor接收了议案后,一个议案已经成为了多数派,但是后来又有议案提出覆盖了之前接受的议案,导致一致性被破坏
问题处理
一次议案选举必须只选定一个议案,一旦选定,不能更改
目标汇总
Target1:一次选举必须要选定一个议案(不能出现所有议案被拒绝情况)
Target2:一次选举必须只选定一个议案(不能出现两个议案有不同的值但都被选定)
问题处理
P1:一个Acceptor必须接受它收到的第一个议案(容易处理)
P2:如果一个值为v的议案被选定,那么被选定的更大编号的议案,它的值必须是v
目标
如何实现一个值为v的议案被选定,被选定更大编号的议案,值必须是v
问题处理
P2a:一旦值为v的议案被选定,Acceptor接收更大编号的议案,它的值是v
P2b:一旦值为v的议案被选定,Proposer提出更大编号的议案必须值是v(更容易处理)
目标
值为v议案被选定,如何实现Proposer提出更大编号的议案的值必须是v
问题处理
P2c:在所有Acceptor中,任意选取半数以上的Acceptor集合,我们称这个集合为S。Proposal新提出的议案(简称Pnew)必须符合下面两个条件之一:
1)如果S中所有Acceptor都没有接受过议案的话,Pnew的值可以是任意值。
2)如果S中有一个或多个Acceptor曾经接受过议案的话,要先找出其中编号最大的那个议案,假设它的编号为N,值为V。那么Pnew的编号必须大于N,Pnew的值必须等于V。
问题
确定议案的过程中呈现id大者决定一切,如果S集合之外有一个提案的ID大于所有S集合内的id,就会出现一致性破坏现象
问题分析
需要在议案提交前确定自己的编号是当前已经提出过议案的最大编号
问题处理
分阶段的出现:需要在议案提交前向Acceptor确认当前自身id是否是议案的最大编号,然后再提交
目标
如何实现两个阶段:Prepare阶段该确认ID是否为最大值,Accept阶段提交议案
目标实现
- 议案(id,v)在提交前,将id通知给S集合的Acceptor。收到通知的Acceptor将id跟自己之前收到的议案进行比较,如果id小则不回复,如果id更大,就将id确认为最大编号,并回复
- Acceptor同时做出承诺:不再接受比n小的议案。
- 当Proposer收到回复的数量大于Acceptor总量的一半时,议案(id,v)才能正式提交。
细节解释:只要保证一开始S集合中id最大即可,因为S集合的数量大于Acceptor数量的一半,所以S集合中id最大就是整个Acceptor中id最大
问题
Proposer1提交议案的过程中,如果另一个Proposer2进入Prepare阶段,提交议案的id比之前更Proposer1更大,会出现议案提交后接受的Acceptor少于一半的情况,并没有达成一致性
问题处理
提交回复:Acceptor接受议案后会给Proposer回复,如果Proposer收到的回复大于Proposer的一半时,则表示一致性达成,否则会再次进入Prepare阶段。
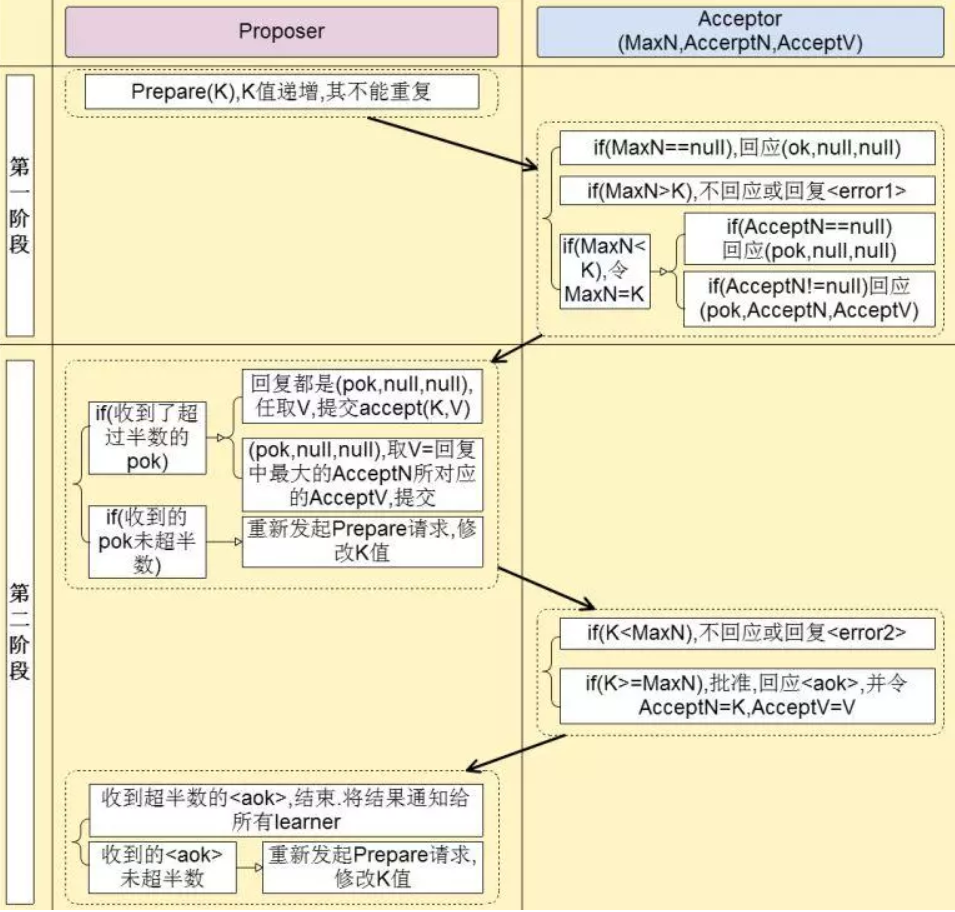
主要角色
-
领导者(leader同Paxos中Proposer):负责进行投票的发起和决议,更新系统状态(数据同步),发送心跳。事务请求唯一调度者和处理者,保证集群事务处理的顺序性
-
跟随者(follower同Paxos中Acceptor):用于接受客户端请求、向客户端返回结果,在选主过程中参与投票。收到写事务请求直接转发给Leader
- 观察者(Observer同Paxos中Learner):可以接受客户端请求,将写请求转发给leader,但Observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度。
Paxos算法的活锁问题:ZooKeeper只有一个leader的原因
Paxos中分为Prepare阶段和Accept阶段,但在运行的过程中,会存在一种极端情况,两个Proposer依次提出一系列编号递增的议案,就会陷入死循环,无法完成Accept阶段,如图
专有术语
- 服务器ID(SID):标识一台ZooKeeper集群中的机器,SID和myid值一样,不能重复
- 事务ID(ZXID):标记唯一一次服务器状态的变更,某一时刻,集群中的每台机器的ZXID不一定都一致
两种模式:恢复模式(发现阶段+同步阶段),广播模式(广播阶段)
发现阶段:选举
- 集群中机器出现故障,则进入选举过程,切换到LOCKING状态
- 选举规则:第一优先级:ZXID大者,第二优先级:SID大者
同步阶段
完成Leader选举后,正式工作之前,Leader服务器会首先确保事务日志中所有的Proposal是否已经被过半的服务器Commit。
-
Leader服务器会为每一个Follower服务器都准备一个队列
-
将那些没有被同步的事务以Proposal消息的形式逐个发送给Follower服务器
- 然后每一条Proposal消息之后都紧接着Commit消息表示该事务已被提交
等到Follower服务器都将未同步的事务从Leader服务器同步过来并成功应用到本地数据库后,Leader服务器会将该Follower服务器加入真正可用的Follower列表中
广播阶段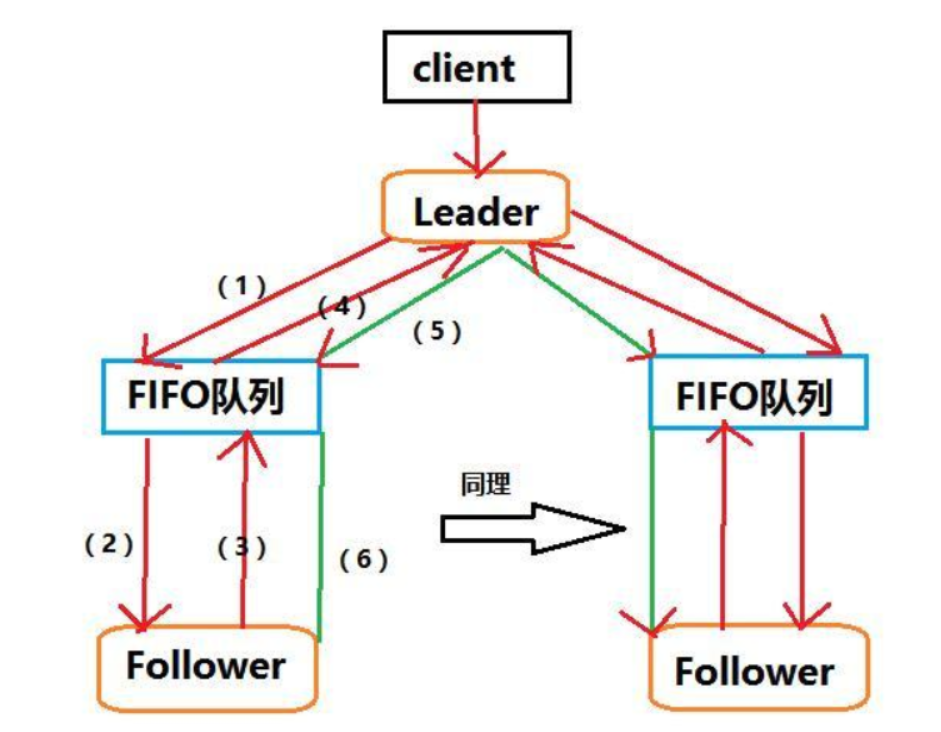
- leader首先把proposal发送到FIFO队列里
- FIFO取出队头proposal给Follower
- Follower首先会以事务日志的形式写入到本地磁盘,成功后反馈一个ACK给队列
- 队列把ACK交给leader
- leader收到半数以上ACK,就会发送commit指令给FIFO队列
- FIFO队列把commit给Follower,所有服务器完成事务的提交
两者之间的联系
- 两者都存在类似Leader进程的角色,向其负责协调多个Follower进程的运行
- Leader进程都会等待超过半数的Follower做出正确的反馈后,才将下一个提案提交
- 在ZAB协议中,每个Proposal中都包含一个epoch值,用来代表当前的Leader周期,在Paxos算法中,同样存在这样的标识,只是名字变成了Ballot
区别
在Paxos算法设计的基础上,ZAB协议添加了同步阶段,新的Leader会确保存在过半的Follower已经提交了之前Leader周期中所有事务Proposal。能够有效保证Leader在新的周期提出Proposal之前,所有的进程都已经完成了对之前的Proposal的提交。其余两个阶段两者类似。
总的来讲
ZAB协议和Paxos算法的本质区别在于,两者的设计目标不太一样,ZAB协议主要用于构建一个高可用的分布式数据主备系统,如ZooKeeper,而Paxon算法则是用于构建一个分布式的一致性状态机系统。
仅个人总结,欢迎指正,部分图片来自互联网
参考《从Paxos到Zookeeper 分布式一致性原理与实践》


