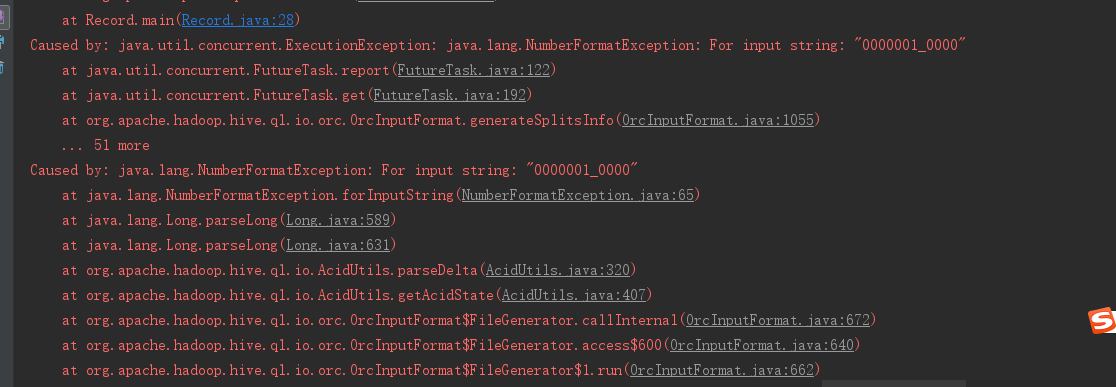
 这个表里没有这个数据 我貌似发现spark读取hive3.0的管理表都报这个错误
这个表里没有这个数据 我貌似发现spark读取hive3.0的管理表都报这个错误
- spark 读取 hive 的问题?
- 关于 spark 写 hbase 用 bulkload 方式的问题?
- 海牛部落 spark 系列教程(四十四):spark-hbase_bulkload、spark 程序集群运行、spark-streaming
- 海牛部落 spark 系列教程(四十四):spark-hbase_bulkload、spark 程序集群运行、spark-streaming
- 海牛部落 spark 系列教程(四十四):spark-hbase_bulkload、spark 程序集群运行、spark-streaming
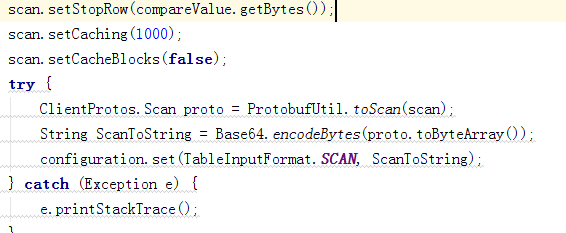
- 关于 hbase 的 scan 的问题?
- 关于 hbase 的 scan 的问题?
- 关于 hbase 的 scan 的问题?
- 海牛部落 spark 系列教程(四十三):spark-hbase
- 海牛部落 Hbase 系列教程(三十一):Hbase 根据自定义方法预分 region
- 海牛部落 java 系列教程(二十七):Hbase 的 Java 操作
- 为啥我的 sparksql 加了 where 不管用呢?
- Hbase 如何用 javaAPI 列出列族及字段名?
- 海牛部落 hbase 系列教程(二十八):hbase 的 filter 用法,hbase 数据的批量导入
- Hbase 如何用 javaAPI 列出列族及字段名?