奶牛老师这头像真帅喔
- Hbase 数据迁移
- 通过 Spark ThriftServer 查询 Hive 效率太慢,有没有优化办法?
- HDFS 写数据时,DataNode 为什么是串行写?
- [下载] Flink 教程
- [下载] Hadoop3 教程
- [下载] Hive 教程
- [下载] StructuredStreaming 教程
- flink 连 kafka 的方式是什么?直连还是?
- 我照着海牛的视频部署集群,结果配置到 myql 的时候报错
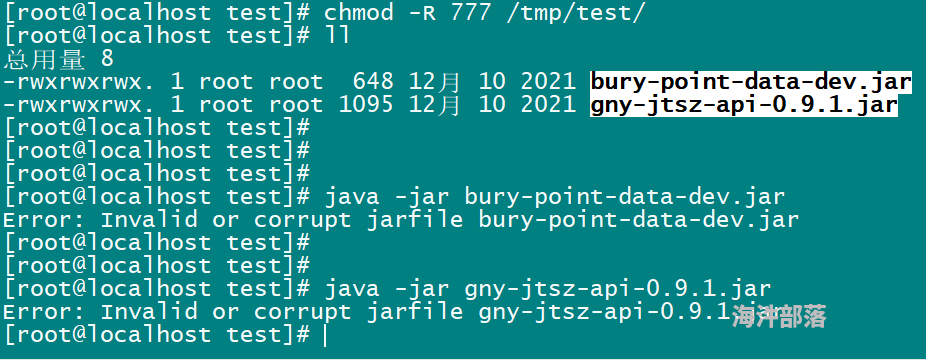
- jar 包打包失败,试了一晚上了,也没大成功?
- jar 包打包失败,试了一晚上了,也没大成功?
- 最简单高效的 JSON 转 CSV
- 企业级 NGINX 配置 1
- 企业级 NGINX 配置 2
- HIVE 基础-->安装,建表 (前两天)

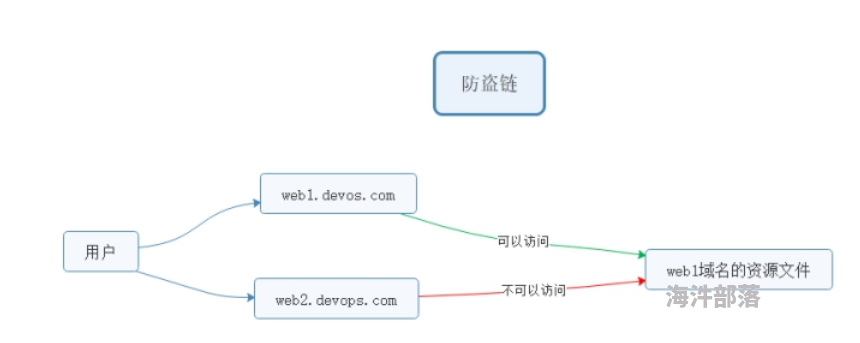 防盗链原理图
防盗链原理图