@guoguo 那必须支持,要不然我就没必要修改Parser.jj 文件生成新的FlinkSQL 语法规则了,目的就是为了让sql hints 与算子绑定而不是跟表绑定,这样可以更细粒度控制 TTL,但开源的 Sql Hint 写法只能写在 select 后面或表后面才能sql校验通过,不会跟某个算子绑定,如:left join DATA_GEN_03 /+ OPTIONS('state.ttl.right'='12345S') / c
@123456789987654321 我主推jsonpath是想解放繁琐的ETL过程,想通过简单的配置就解决ETL问题,手写mapreduce的操作未免显得太古老,还不如我直接定义redshift的UDF函数,毕竟支持java和python库,redshift也支持的EMR ,也比MR更聪明,就是想利用EMR写成一个通用的先解析json数组再转换CSV的框架会有些困难
@青牛 我之前没用过,你说了我才知道有这功能,谢老师:blush:
@青牛 嗯嗯 多谢老师!
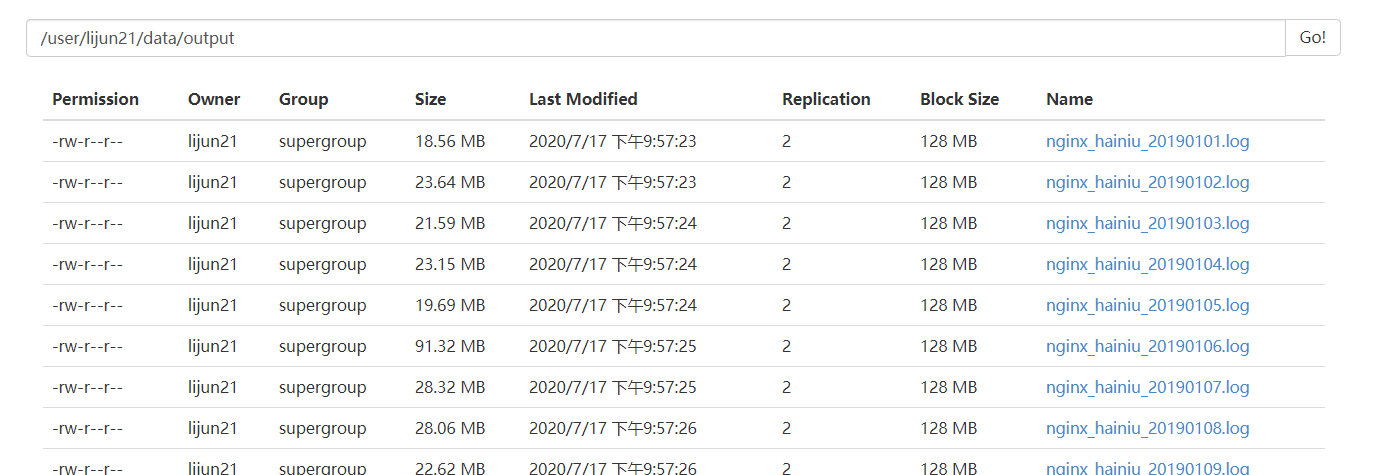
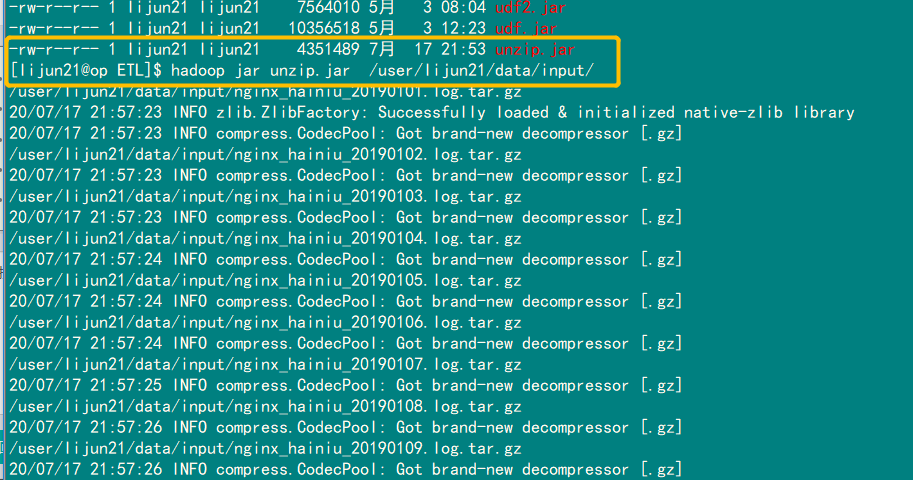
自动生成output文件目录并输出文件同时去除输出文件名的.tar.gz和.gz后缀:
控制台运行:
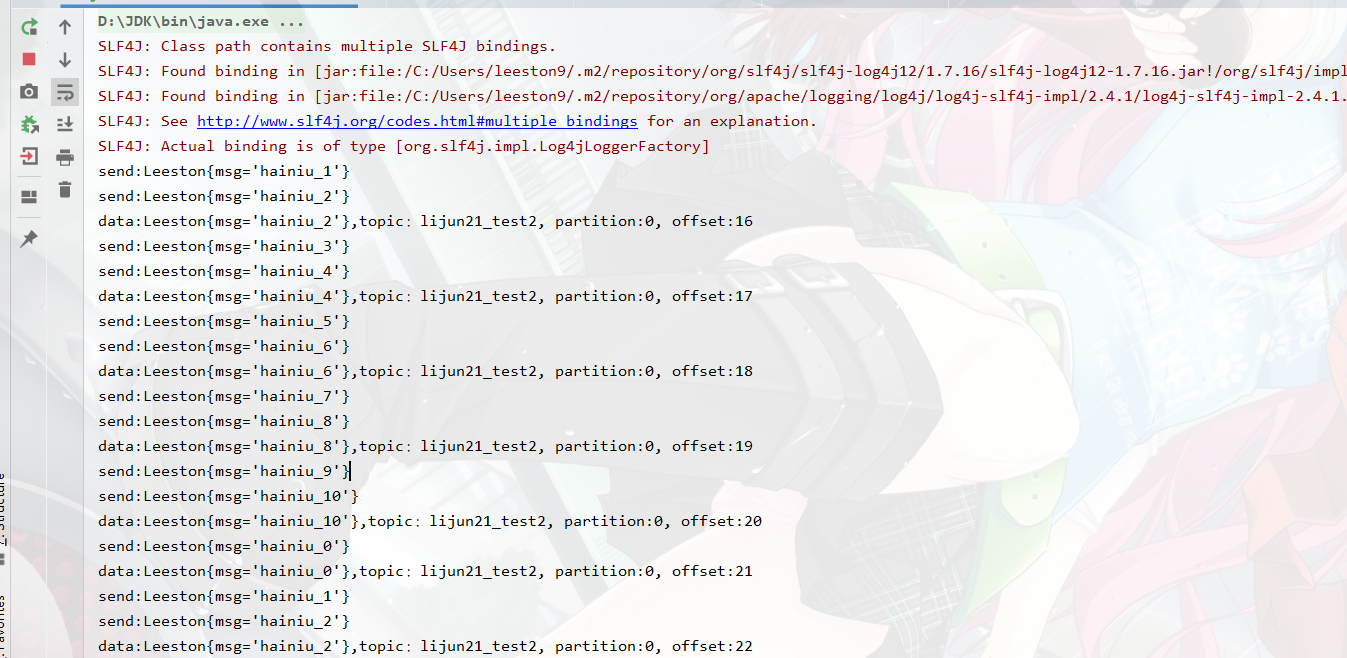
上面格式比较乱,不知道为什么:输出结果如下:
这时候就应该确认一下你用的是不是idea还是eclipse, 如果是idea 就必须要将pom里的 provided 修改为 compile 或者直接注释掉
@青牛 是的 写遛弯儿了:blush:
总结的很好,自从用了德鲁伊,再也不想用c3p0了:bowtie: