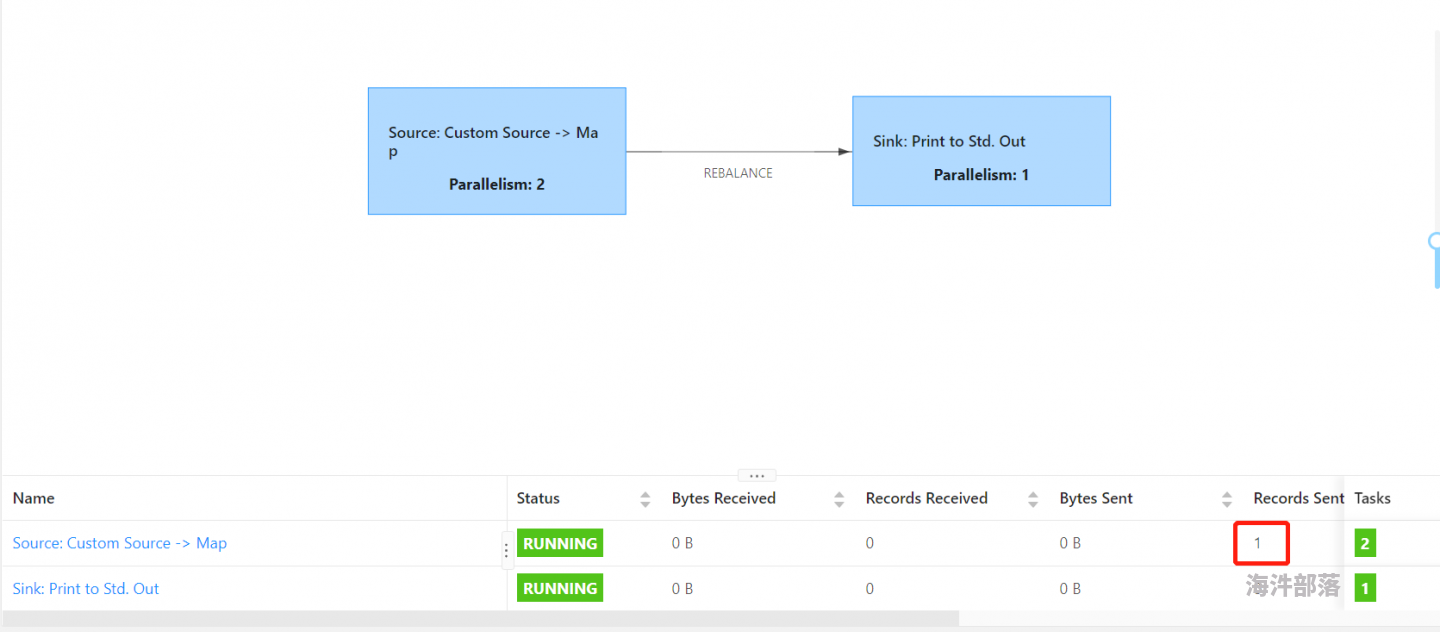
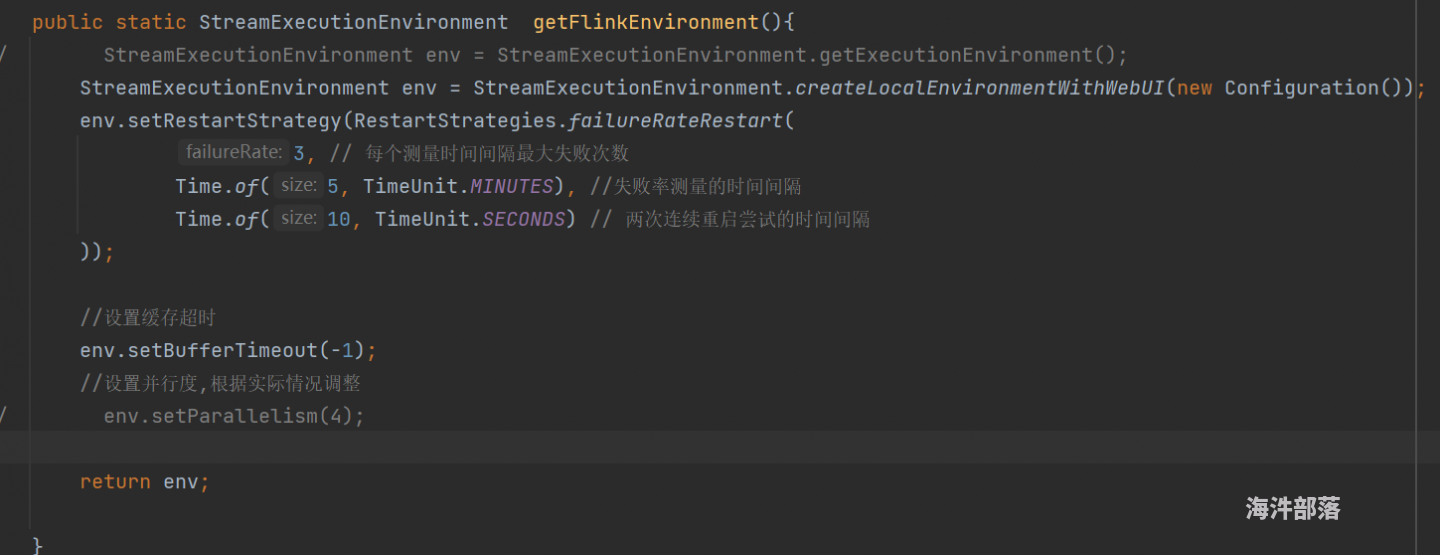
@青牛 我是用的几个测试数据,应该一个并行度就可以跑的。然后我改变并行度后,还是卡在keyby那里。我打印出下keyBy之前的输出,1> ScanWrapInfo{billCode='210128', jobCode='LHAR_UKK_URT_TL-210128', scanCode='12345', scanSiteCode='HHH', scanSiteId=11, scanSite='BALIDAO', scanTypeName='03', scanSiteTypeId='30', weight=4.3, volume=24000.0, preOrNextStationId=12000, preOrNextStation='URT', scanDate=Mon Sep 13 16:12:26 CST 2021},这个是对象的表示形式吧,按照它的一个属性 jobCode来分组是不是可以的?