关于 “” 的搜索结果, 共 2411 条
sparksession 支持并发访问吗?
by
 Whalley
Whalley
https://hainiubl.com/topics/36505?
2019-05-20
⋅
2789
⋅
0
⋅
1
比如有20个用户,传入各自的参数,我要用sparksession创建20个临时表,作为公共sql的in查询条件。这个sparksession是每个用户一个,还是当前程序就一个
spark 读取 sql 文件并创建 Graphx 图如何操作?
by
 浅唱
浅唱
https://hainiubl.com/topics/36506?
2019-05-20
⋅
2286
⋅
0
⋅
1
利用IDEA读取sql文件并生成对应的图(利用sql中的数据产生图)。具体操作怎么做呢,大佬给解释解释
Hbase 如何使用不同的 zookeeper 的不同端口?
by
 冥
冥
https://hainiubl.com/topics/36507?
2019-05-20
⋅
2764
⋅
0
⋅
1
为了了解 Hbase,搭建了个单机上多 zookeeper 实例,但是配置 Hbase 时,如何配置 zookeeper 的不同 clientPort?
可以给 hbase 设置账号和密码么?
by
 BOBO
BOBO
https://hainiubl.com/topics/36509?
2019-05-21
⋅
4596
⋅
0
⋅
1
可以给hbase设置账号和密码么?
hbase 通过 java API 访问的时候怎么能够控制访问权限?kerberos 比较复杂有简单的么?
by
 Sunmer
Sunmer
https://hainiubl.com/topics/36510?
2019-05-21
⋅
2667
⋅
0
⋅
1
hbase 通过java api访问的时候怎么能够控制访问权限?kerberos 比较复杂有简单的么?
Flume 为什么在 HDP 技术栈中被移除,有什么替代的框架吗?
by
 李伟
李伟
https://hainiubl.com/topics/36511?
2019-05-21
⋅
2850
⋅
0
⋅
1
HDP技术栈中使用什么进行数据采集?
如何理解 MapReduce 数据不动计算动?
by
 镜花水月
镜花水月
https://hainiubl.com/topics/36512?
2019-05-21
⋅
2676
⋅
0
⋅
1
大数据,MapReduce
怎么在 R 里面创建一个空的 tibble 或者 data.frame ?
by
 小龙
小龙
https://hainiubl.com/topics/36513?
2019-05-21
⋅
3936
⋅
0
⋅
1
要求生成168列 每一列的数据个数不一样每一列的空值用na补 求问各位大佬~
R 语言中 SARIMA-GARCH 模型怎么实现?
by
 滴磨成觞
滴磨成觞
https://hainiubl.com/topics/36514?
2019-05-21
⋅
3308
⋅
0
⋅
1
R语言中SARIMA-GARCH模型怎么实现?
如何在 Uncomtrade 上快速批量下载数据?
by
 寒冰雪域
寒冰雪域
https://hainiubl.com/topics/36515?
2019-05-21
⋅
4964
⋅
0
⋅
1
如何在Uncomtrade上快速批量下载数据?
用 python 数据做数据分析时,统计部分是用 API 调用 r 好,还是使用 statsmodels 等包好?
by
 YDS
YDS
https://hainiubl.com/topics/36516?
2019-05-21
⋅
2467
⋅
0
⋅
1
什么情况调用r语言比较好呢?
numpy 有没有办法直接对矩阵中的多个位置数据进行匹配?
by
 zhangxingong
zhangxingong
https://hainiubl.com/topics/36517?
2019-05-21
⋅
2933
⋅
0
⋅
1
已知一个矩阵(红线框住的矩阵),求在另外一个矩阵中的所有出现的位置。如图所示,在一个多维数组中,我需要匹配到红线框住的数据,并返回左上角第一个数的索引。这里只是举一个简单的例子,实际情况数据要大得多,因为对速度有要求,所以不能用循环的方式挨个匹配,求...
请问 Spark 如何利用 GPU 资源计算?
by
 李鴻飛
李鴻飛
https://hainiubl.com/topics/36518?
2019-05-21
⋅
2796
⋅
0
⋅
1
要做毕设,要优化一个算法(不是机器学习相关的),这个算法本来只是利用Spark平台,导师建议把Spark和GPU结合起来,让Spark调用GPU资源进行计算,但是最近几天查了很多资料,方法似乎有很多,但是感觉可行的太少,目前情况是这样的:
原来这个算法是用python的pyspa...
MongoDB 突然连接不上了,里面的数据还能找回吗?
by
 Alex
Alex
https://hainiubl.com/topics/36520?
2019-05-21
⋅
2344
⋅
0
⋅
1

用 sa 登陆查询分析器,SQL SERVER 不是本机名,创建表,用企业管理器打开数据库,能看见表结构吗?
by
 M先生
M先生
https://hainiubl.com/topics/36521?
2019-05-21
⋅
3128
⋅
0
⋅
1
用sa登陆查询分析器时,如果SQL SERVER(服务器名)不是本机名,创建xi(系)表后,再用企业管理器打开Teaching数据库,能看见xi表的结构吗?为什么?如果SQL SERVER(服务器名)是本机名,再用企业管理器打开Teaching数据库,能看见xi表的结构吗?为什么?
python 爬虫出来的数据怎么存储???
by
 夜莺
夜莺
https://hainiubl.com/topics/36523?
2019-05-22
⋅
2534
⋅
0
⋅
1
已经能爬到数据了,怎么保存?用什么办法比较好呢?后期还有要进行读取和处理数据,然后再存进去
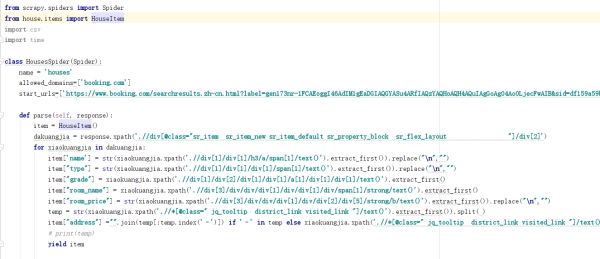
类似博客这样的图文混排内容在数据库中是以什么形式保存的呢?
by
 秋意浓
秋意浓
https://hainiubl.com/topics/36524?
2019-05-22
⋅
3071
⋅
0
⋅
1
类似博客这样的图文混排内容在数据库中是以什么形式保存的呢?直接以前端代码的形式?还是字符串(字符串的话如何保证图文前端正确的展示顺序呢)?
SqlServer2014 创建的数据库怎么能使他在 SqlServer2012 上面运行在个数据库。?
by
 冰雹
冰雹
https://hainiubl.com/topics/36525?
2019-05-22
⋅
2889
⋅
0
⋅
1
SqlServer2014创建的数据库怎么能使他在SqlServer2012上面运行在个数据库。?
R 语言的 ADF 和 Python 的 adfuller 算出来不一样,哪个有 bug?
by
 不忘初心
不忘初心
https://hainiubl.com/topics/36526?
2019-05-22
⋅
3065
⋅
0
⋅
1
先看 R 的:
> library(psymonitor)
> y <- c(0.796491122, -0.632473454, 0.591378141, 0.274361070, 2.234289299, 0.746846750, 0.213032970, -2.409676566, -1.671995924, 0.599171274, 1.076922187, 0.455016454, -0.351731783, -0.934165425, 0.689092161, 1.290...
在真实的生产环境中,Spark 会出现很多以 ANY 级别调度的 task 吗?
by
 晓儒
晓儒
https://hainiubl.com/topics/36527?
2019-05-22
⋅
2636
⋅
0
⋅
2
在真实的生产环境中,Spark会出现很多以ANY级别调度的task吗?
怎么在 hbase 数据库建表和列簇?
by
 MindHacker
MindHacker
https://hainiubl.com/topics/36528?
2019-05-22
⋅
2520
⋅
0
⋅
1
怎么在hbase数据库建表和列簇?
hdfs 的数据存储和管理方试是以什么的方式进行存储的。?
by
 张小果
张小果
https://hainiubl.com/topics/36529?
2019-05-22
⋅
3682
⋅
0
⋅
1
hdfs的数据存储和管理方试是以什么的方式进行存储的。?
有没有 clickhouse 与 MySQL 之间的数据转移工具,类似 hdfs 到 MySQL 的 sqoop 工具?
by
 肖海艳
肖海艳
https://hainiubl.com/topics/36530?
2019-05-22
⋅
5454
⋅
0
⋅
1
有没有clickhouse与mysql之间的数据转移工具,类似hdfs到mysql的sqoop工具?
HDFS 真的能把 10 个 1T 的目录做成一个 10T 的透明目录吗?
by
 Perry
Perry
https://hainiubl.com/topics/36531?
2019-05-22
⋅
2645
⋅
0
⋅
1
HDFS真的能把10个1T的目录做成一个10T的透明目录吗?
python 中元类的使用,该怎么理解呢?
by
 慧有未来
慧有未来
https://hainiubl.com/topics/36532?
2019-05-23
⋅
2732
⋅
0
⋅
1
_board_classes = {} #板子类型字典
class BoardMeta(type): #类BoardMeta,类的模板,所以必须从`type`类型派生
def __init__(cls, name, bases, dct): #类似构造函数,self类似this指针,其他是强制传入的...
paddlepaddle 和 python 是什么关系?
by
 mhcnsk
mhcnsk
https://hainiubl.com/topics/36533?
2019-05-23
⋅
2613
⋅
0
⋅
1
小白一枚,望大神可以讲得容易理解一点
为什么 MapReduce 中 context.write () 有时候不执行或者没有数据?
by
 Colen
Colen
https://hainiubl.com/topics/36534?
2019-05-23
⋅
2803
⋅
0
⋅
1
为什么MapReduce中context.write()有时候不执行或者没有数据?
Flink on yarn 提交时出错,请问有人遇到过吗?
by
 风口浪尖
风口浪尖
https://hainiubl.com/topics/36535?
2019-05-23
⋅
2504
⋅
0
⋅
1
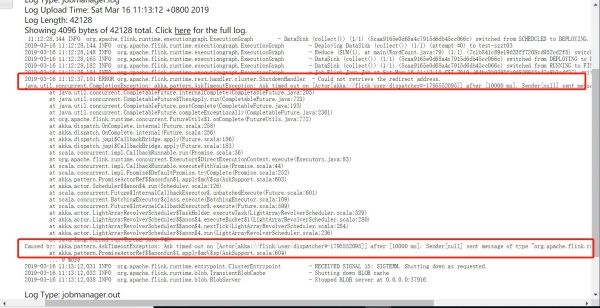
webpack 加载自定义模块和 node_modules 模块有何区别?
by
 蓝天
蓝天
https://hainiubl.com/topics/36536?
2019-05-23
⋅
2791
⋅
0
⋅
1
(function (global, factory) {
typeof exports === 'object' && typeof module !== 'undefined' ? factory(exports, require('d3-selection'), require('d3-transition')) :
typeof define === 'function' && define.amd ? define(['exports', 'd3-selection', 'd3...
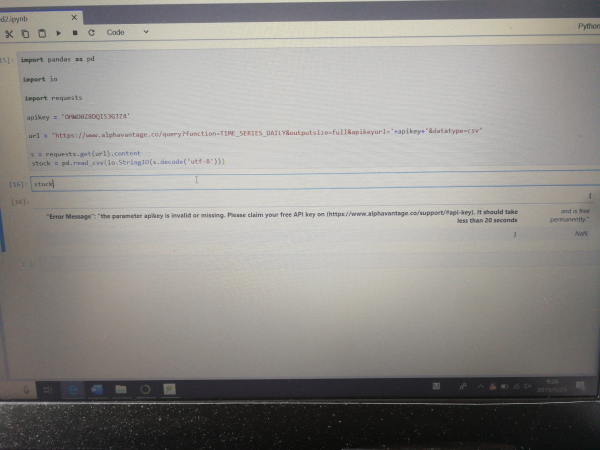
注册了 alpha vantage 的 apikey 但是在 jupyterlab 里面显示是无效的?
by
 Shihw丶疙瘩
Shihw丶疙瘩
https://hainiubl.com/topics/36537?
2019-05-23
⋅
3774
⋅
0
⋅
1
已经反复刷新了,但是还是显示apikey无效是为什么