关于 “” 的搜索结果, 共 2411 条
Java 包装类型中的 Type 是做什么的?
by
 李彬
李彬
https://hainiubl.com/topics/36455?
2019-05-15
⋅
2732
⋅
0
⋅
1
/**
* The {@code Class} instance representing the primitive type
* {@code int}.
*
* @since JDK1.1
*/
public static final Class<Integer> TYPE = (Class<Integer>) Class.getPrimitiveClass("int");
每一个包装类型都有这一个字段,这个字段...
akka 适合那种耗时长的异步任务吗?
by
 gogo55ok
gogo55ok
https://hainiubl.com/topics/36456?
2019-05-15
⋅
2346
⋅
0
⋅
1
我公司项目比较特殊,核心业务全是异步任务,而且很多任务耗时间比较长步骤也很复杂,想过很多框架,看中了akka的灵活性以及集群的支持,我不知道akka适不适合这种场景,或者说还有什么更好的选择吗?语言主要用java
Python 中如何实现类似 JAVA 中 protected 关键字的功能?
by
 lsq
lsq
https://hainiubl.com/topics/36457?
2019-05-15
⋅
1993
⋅
0
⋅
1
今天上课写了一个类,用了私有属性,同时在类中写了一个普通方法访问私有属性。然后又定义另一个类继承第一个类,主程序中,声明一个子类的对象,调用父类方法的时候报错了,原因是访问了不存在的属性,这种问题怎么破?
python eval ('500/10') 最后结果怎么是 50.0 不是 50?
by
 闲云人生
闲云人生
https://hainiubl.com/topics/36459?
2019-05-16
⋅
7513
⋅
0
⋅
1
python eval('500/10')最后结果怎么是50.0不是50?
用 JAVA 语言编程计算器识别不出 add 请问应该怎么修改这一块?
by
 陈立贵
陈立贵
https://hainiubl.com/topics/36460?
2019-05-16
⋅
2360
⋅
0
⋅
1
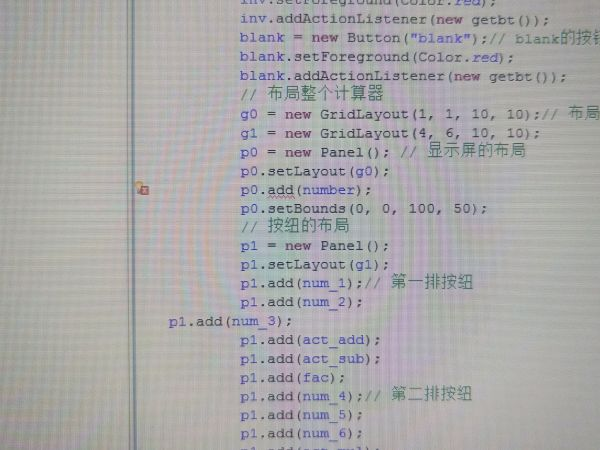
response.addcookie () 发生了什么?
by
 棉花糖的骨架
棉花糖的骨架
https://hainiubl.com/topics/36461?
2019-05-16
⋅
3346
⋅
0
⋅
2
为什么response.addcookie()之后,马上request.getcookies()就能得到cookie呢?照理说response.addcookie是给浏览器发送一个cookie,那么应该是下一次request才能get到cookie啊?
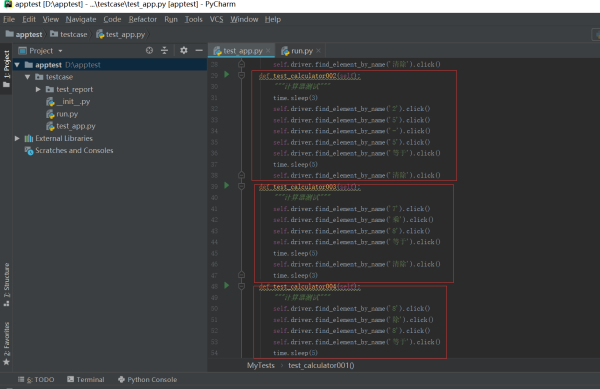
为什么 def test_calculator002 执行完 APK 会关掉再重启?
by
 LYR
LYR
https://hainiubl.com/topics/36462?
2019-05-16
⋅
2477
⋅
0
⋅
0
为什么我这个def test_calculator002执行完APK会关掉再重启才执行def test_calculator003?
akka 适合那种耗时长的异步任务吗?
by
 勿忘初心
勿忘初心
https://hainiubl.com/topics/36463?
2019-05-16
⋅
1992
⋅
0
⋅
1
我公司项目比较特殊,核心业务全是异步任务,而且很多任务耗时间比较长步骤也很复杂,想过很多框架,看中了akka的灵活性以及集群的支持,我不知道akka适不适合这种场景,或者说还有什么更好的选择吗?语言主要用java
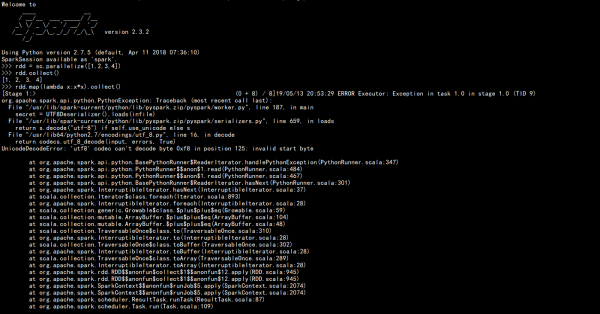
pyspark 编码会产生这种问题嘛?
by
 Sunseeker
Sunseeker
https://hainiubl.com/topics/36464?
2019-05-16
⋅
2469
⋅
0
⋅
1
今天在pysark中遇到了如图的报错问题,而如果用scala语言的话则没有问题,像这种情况一般问题出现在哪里呢?
关于 CDH (cloudera) 搭建过程中的几个问题,每台虚拟机怎么配置?
by
 小岗
小岗
https://hainiubl.com/topics/36465?
2019-05-16
⋅
2654
⋅
0
⋅
1
只有一台笔记本,装了虚拟机centos7,搭建CDH时需要建几个虚拟机呢,每个虚拟机都要装MySQL吗?
Hadoop 存放文件的格式是什么?
by
 alan
alan
https://hainiubl.com/topics/36466?
2019-05-16
⋅
2466
⋅
0
⋅
1
想要学习Hadoop并且也看过了一些教程,但是还是没弄明白企业级Hadoop是如何存放数据的。网上的教程基本是以csv为例子,直接放到hdfs,然后hive查询给出结果之类的。
那么企业级数据是怎么存放在Hadoop的呢,也是csv直接扔到hdfs么,还是别的格式类似Parquet然后用Spa...
ambari 集群 haoop 执行 mr hive 任务报错?
by
 物联网小小行
物联网小小行
https://hainiubl.com/topics/36474?
2019-05-16
⋅
3221
⋅
0
⋅
1
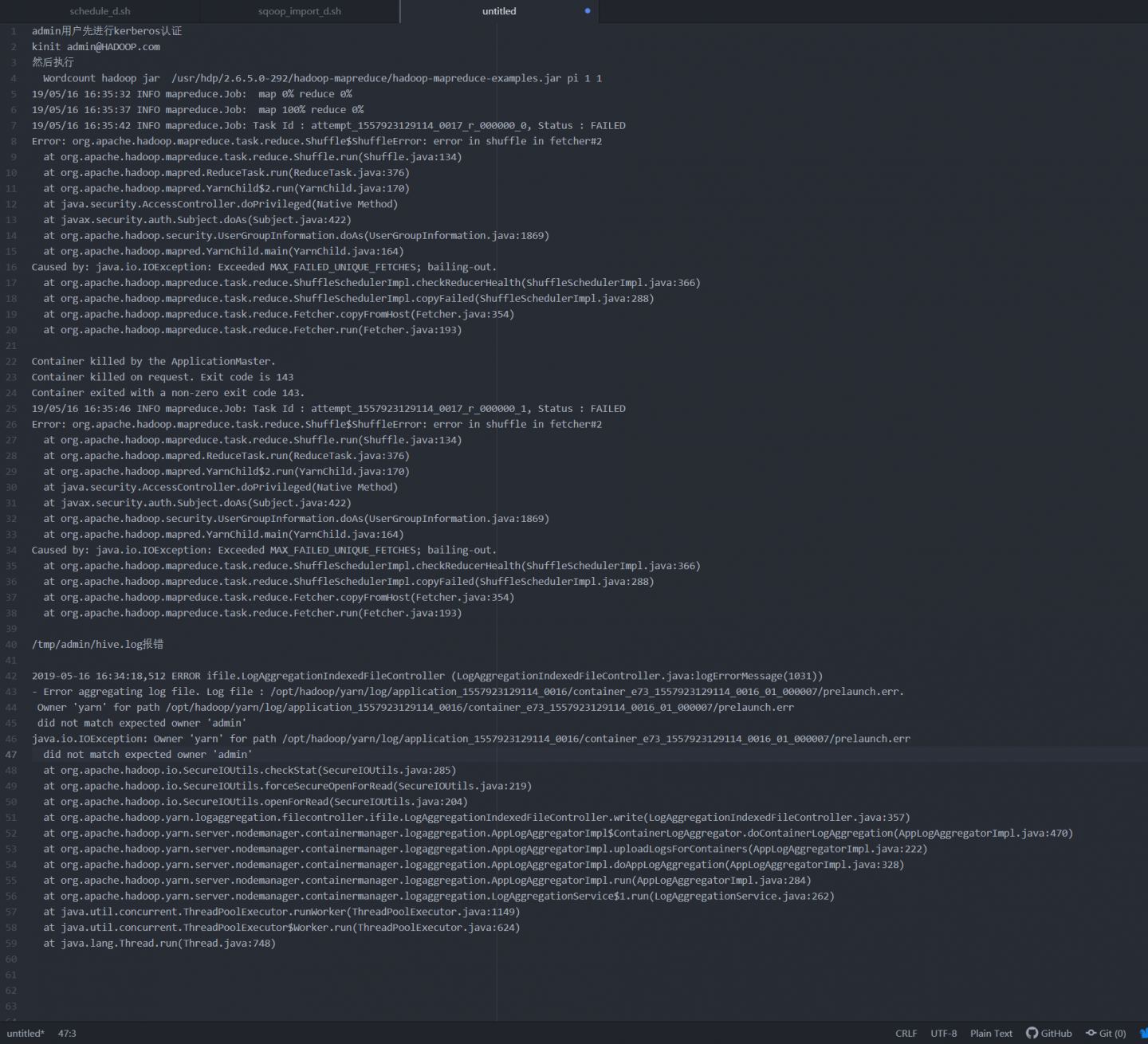找了半天了也没找到解决的方式,调整mapreduce.reduce.shuffle.input.buffer.percent" * "mapreduce.reduce.shuffle.parallelcopies等参数执行MR任务还是不好使,清空和修改目录权限 hadoop/...
pycharm 中的 python interpreter 用哪个好, 各有何优缺点?
by
 給你一朵向陽花
給你一朵向陽花
https://hainiubl.com/topics/36476?
2019-05-17
⋅
2767
⋅
0
⋅
1
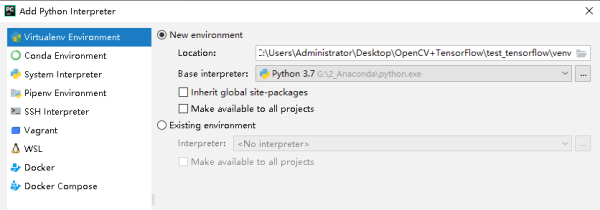
Python 可以做的事情其他语言也可以做,企业为什么要选择 Python?
by
 等待
等待
https://hainiubl.com/topics/36477?
2019-05-17
⋅
2540
⋅
0
⋅
1
Python的工资相比其他语言还要高一点,这样的情况下企业又什么理由来选择Python
python 有没有离线城市经纬度数据包?
by
 2118
2118
https://hainiubl.com/topics/36478?
2019-05-17
⋅
2840
⋅
0
⋅
1
大概想实现的效果就是输入经纬度,输出是哪个国家哪个城市。求教各位大佬有没有离线的数据推荐,不是使用各种线上API的方法有吗?
python3.4.4 版的 idle 里的 debug 为什么用不了?
by
 刘玉星
刘玉星
https://hainiubl.com/topics/36480?
2019-05-17
⋅
2936
⋅
0
⋅
1
之前在台式机上装的3.4.4一点问题都没有,debug完全正常。最近新买的笔记本,装上之后,debug总是不受控制的缩界面然后勾上source global等那四个选项过一会儿勾就消失。
大数据的多表联合查询统计怎么处理?
by
 coxx
coxx
https://hainiubl.com/topics/36481?
2019-05-17
⋅
2683
⋅
0
⋅
1
我现在做了一个查询功能,查询数据来源于两个表A,B,A有6000万,B有500万,查询条件,2个表都有,做分页统计的时候,需要统计个数量用来做前端的分页处理,用join查询,根本查询不出来,因为第一次查询,根本没有任何查询条件,相当于全查,建了个字段加索引(delete_fla...
找不到文件 “/home/lsj/etc/hadoop/core-site.xml” 怎么办?
by
 独醉在今朝
独醉在今朝
https://hainiubl.com/topics/36482?
2019-05-17
⋅
3152
⋅
0
⋅
1
hadoop伪分布式配置,找不到文件“/home/lsj/etc/hadoop/core-site.xml”。怎么办
spark submit 运行正常,但是 oozie 提交 spark on yarn 会报错怎么办?
by
 盛宏伟
盛宏伟
https://hainiubl.com/topics/36483?
2019-05-17
⋅
2179
⋅
0
⋅
1
报找不到一些类的方法的错,但是我的oozie的share lib更新过了,全新的spark的jar
求 hadoop 大神?
by
 匡时济世
匡时济世
https://hainiubl.com/topics/36484?
2019-05-17
⋅
2495
⋅
0
⋅
1
hdfs系统在上传文件时候,明明设置了三个副本,上传成功之后却没有副本,在日志中出现下面的内容
2012-09-18 13:42:38,901 INFO org.apache.hadoop.ipc.Client: Retrying connect to server: master/192.168.1.240:9000. Already tried 0 time(s).2012-09-18 13:42:39,...
Hansen 由于 region split 导致 region 短暂下线客户端写入失败问题 如何解?
by
 jures
jures
https://hainiubl.com/topics/36487?
2019-05-17
⋅
2393
⋅
0
⋅
1
单节点 创建表时没有预分区
Python 如何将字符串式列表转化为可以操作的列表?
by
 Kali
Kali
https://hainiubl.com/topics/36488?
2019-05-17
⋅
2301
⋅
0
⋅
1
好像eval函数对于[1,2,a,[2,4],6]这样的没有用,因为其中有未定义的a,idle运行时会报错
题目是这样
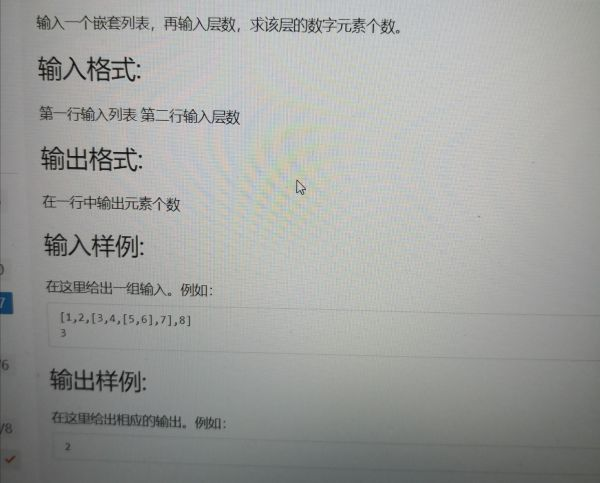
你好,我是个在线大学生,我想问下,在 Python 和 Scala 在大数据中 Python 是不是更多的运用于数据挖掘,而 Scala 用于 spark 的数据筛选。谢谢?
by
 半杯湖底沙
半杯湖底沙
https://hainiubl.com/topics/36489?
2019-05-17
⋅
2620
⋅
0
⋅
1
你好,我是个在线大学生,我想问下,在Python和Scala在大数据中Python是不是更多的运用于数据挖掘,而Scala用于spark的数据筛选。谢谢
Spark 可以调试 rdd 内部的操作吗?
by
 zqlchlh
zqlchlh
https://hainiubl.com/topics/36490?
2019-05-17
⋅
2613
⋅
0
⋅
1
使用远程调试的方法可以调试driver节点上spark程序 但是spark程序大部分都是rdd内部的转换操作, 如filter,map等内部的操作,这些操作都在executor内完成,随着程序越写越大,出现bug再所难免,这些rdd的操作该如何调试呢?
netbeans 设计 jframe 怎么循环数据?
by
 x843974585
x843974585
https://hainiubl.com/topics/36491?
2019-05-17
⋅
2428
⋅
0
⋅
1
用netbeans建了一个jframe窗体,窗体加了一个面板,面板上拖拽了很多组件做成了一个表单,现在我从后台传过来一个JSONArray,里面有多条JSON数据,已经拿到数据了,但是每个表单只能存一条,怎么用代码或者其他方法,复制出更多的容器,用来存放这些数据呢?
PHP curl 抓取到网页后怎么处理数据,做成统计表(比如最近一个月天气)?
by
 DenzelLee
DenzelLee
https://hainiubl.com/topics/36492?
2019-05-17
⋅
2329
⋅
0
⋅
1
PHP curl抓取到网页后怎么处理数据,做成统计表(比如最近一个月天气)?
在 NCBI 上怎么下载转录组数据?
by
 广广
广广
https://hainiubl.com/topics/36493?
2019-05-17
⋅
4787
⋅
0
⋅
0
在NCBI上怎么下载转录组数据?
Python 中 sklearn.svm 使用过程中,横纵坐标值为什么会影响决策面(边界)?
by
 王康
王康
https://hainiubl.com/topics/36502?
2019-05-20
⋅
2992
⋅
0
⋅
1
在学习使用python中的SVM时,等比例扩大横纵坐标值会直接影响分类结果。以这个网页上的代码为例,当数据的横纵坐标值等比例扩大100倍时,数据点的分布并没有变化,然而决策面变了。这是为什么呢?谢谢。
 李腾飞
李腾飞
https://hainiubl.com/topics/36503?
2019-05-20
⋅
2746
⋅
0
⋅
0
怎样调用sha算法将peerchallenge,authenticatorchallenge,username生成challenge
为何 hadoop streaming 集群运行结果与测试结果差异极大?
by
 hadooper
hadooper
https://hainiubl.com/topics/36504?
2019-05-20
⋅
2492
⋅
0
⋅
1
求助一下各位。
背景:
原始数据中的每行是个样本,每条样本包含一些关键字,mr作业目标是计算特定的一些关键字在所有样本中的覆盖率(即关键字出现次数 / 样本总数),线下使用cat map sort reduce 测试的结果无异常,但提交作业到hadoop集群后结果很奇怪,有两点...