关于 “” 的搜索结果, 共 2411 条
kafka 同一个消费组里 多个消费者 使用 consumer.assign (topicPartitions);会造成数据重复吗?
by
 shishuai19910217
shishuai19910217
https://hainiubl.com/topics/36305?
2019-04-19
⋅
16813
⋅
1
⋅
8
有两个消费者 同属于消费组A 都消费topic1的数据
两个消费者都是使用assign 手动指定分区 两个消费者指定的分区是一样的
请问 这两个消费者消费的数据会重复吗?
大数据集群启动 kerberos 认证和 sentry 后,使用普通用户操作 hive 的语句 select count (*) from tableXX;提示无权限?
by
 好好学习
好好学习
https://hainiubl.com/topics/36306?
2019-04-19
⋅
3672
⋅
0
⋅
1
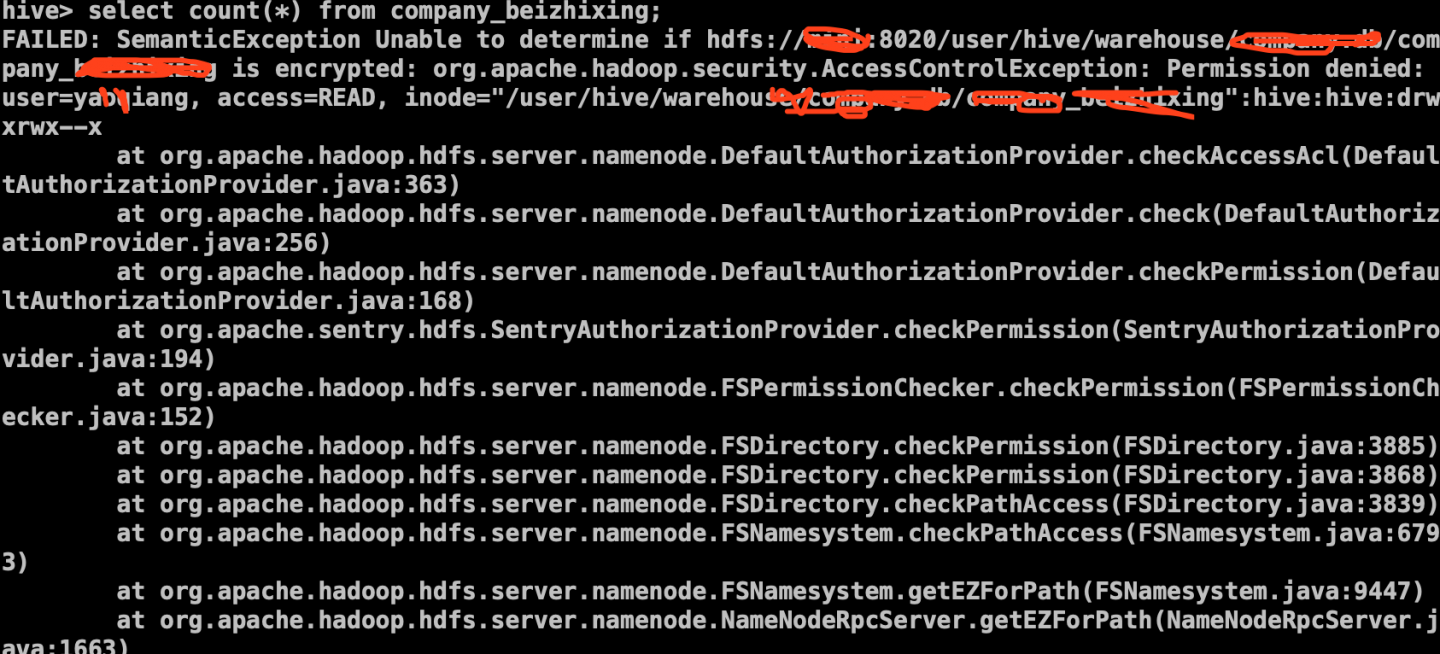
使用普通用户登录hive操作时无法运行select count(*) 该如何添加该用户的权限呢?跑mr程序,以及可以在hue界面上操作!
MySQL 数据库中有个字段是 JSON 格式,在 hive 中如何定义该字段?
by
好好学习
https://hainiubl.com/topics/36307?
2019-04-21
⋅
3673
⋅
0
⋅
2
MySQL数据库中有个字段是json格式的[{"tag_id":"111","tag_name","ktv"},{"tag_id":"112","tag_name","aaa"}],该字段内容很长很多,数据用sqoop导入到hdfs里面,想建立hive外部表,如何在hive表中定义该字段?请大神解答
能否利用 ogg+kafka+spark 实现数据的准实时更新,源端和目标端都是 oracle?
by
 BOBO
BOBO
https://hainiubl.com/topics/36309?
2019-04-22
⋅
3085
⋅
0
⋅
1
能否利用ogg+kafka+spark实现数据的准实时更新,源端和目标端都是oracle?
spark 处理数据的数据结构是什么?
by
 Sunmer
Sunmer
https://hainiubl.com/topics/36310?
2019-04-22
⋅
2518
⋅
0
⋅
1
用过MySQL数据库,想知道spark处理RDD是不是也跟处理表一样,可以很容易关联,分组,多个维度字段的分组。
为什么 HIVE 里显示有 3 张表,而 PYSPARK 里只显示一张表咧?
by
 李伟
李伟
https://hainiubl.com/topics/36311?
2019-04-22
⋅
2675
⋅
0
⋅
1
今天Mongodb里的2张表直接导入hive, hive里“show tables”里显示有3张表,而pyspark“show tables”里显示只有1张表呢?这是什么原因了,另外2张怎么才能读出来咧?备注(已经把机群重启了一次还是不行)
 镜花水月
镜花水月
https://hainiubl.com/topics/36312?
2019-04-22
⋅
2560
⋅
0
⋅
1
关于分区什么时候进行的问题
分区是在maptask 到reduceTask的时候进行分区,还是说在sc.textFile就开始分区了呢
我测试了一下,sc.textFile分区后我把每个分区的内容打印出来发现不是hash算法分区,但是当我经过了shuffle算子之后再打印各个分区的内容就是按照hash...
airflow 定义 task 调度 spark 离线任务(YARN),有没有办法获取 spark 任务的执行状态?
by
 小龙
小龙
https://hainiubl.com/topics/36313?
2019-04-22
⋅
4124
⋅
0
⋅
1
我理解的是 task 的执行状态是和 spark-submit 脚本挂钩的,而不是 spark 程序。但是定义 DAG 的时候,我希望是在 spark 程序成功完成的时候再执行下一个 task,而不是sh文件执行成功,请问有办法实现吗?
请问我这 pycharm 下的 spark 运行老是打印这行警告日志,咋去掉啊,我到 log4j 都改了还没用?
by
 滴磨成觞
滴磨成觞
https://hainiubl.com/topics/36314?
2019-04-22
⋅
2925
⋅
0
⋅
1
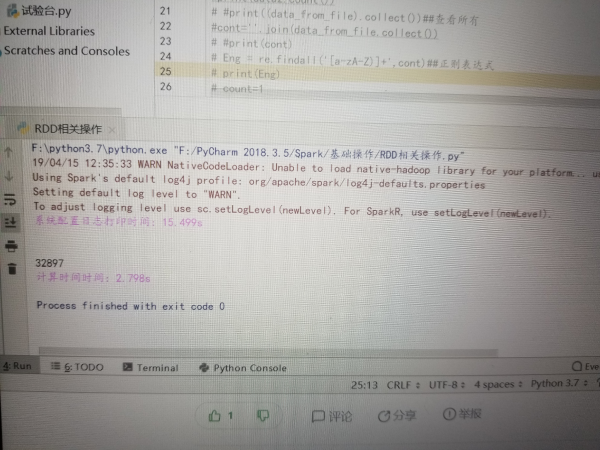
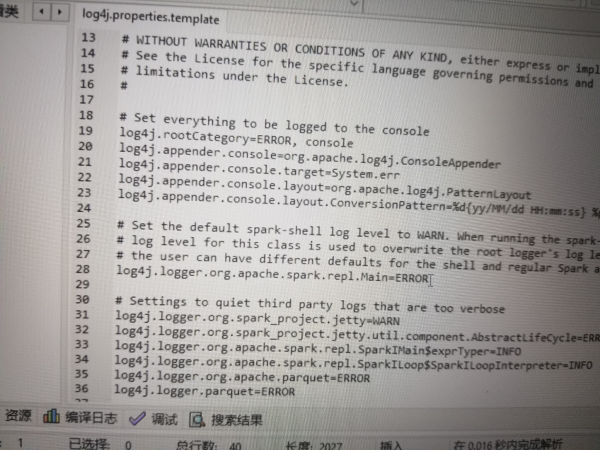
spark 程序 在 sc.stop 之后的代码在哪里执行的?怎么执行的?
by
 寒冰雪域
寒冰雪域
https://hainiubl.com/topics/36315?
2019-04-22
⋅
2887
⋅
0
⋅
1
spark程序 在sc.stop之后的代码在哪里执行的?怎么执行的?
spark 中 spark.reducer.maxSizeInFlight 多大合适?
by
 YDS
YDS
https://hainiubl.com/topics/36316?
2019-04-22
⋅
3091
⋅
0
⋅
1
看相应的配置说明,都说的比较模糊,如果我的内存比较大,这个参数是不是可以配置很大,比如说1g,这样是否拉取数据很快?
如何在 hive 与 pig 中选择?
by
 zhangxingong
zhangxingong
https://hainiubl.com/topics/36317?
2019-04-22
⋅
2689
⋅
0
⋅
1
在进行在数据连接和过滤(jion and filter result data from various sources)阶段,选择hive或者pig,实际作出的取舍是什么?不了解实现原理,有点理解不了二者的优点和缺点.....
spark collect (),当数据量比较大时,卡死怎么解决?
by
 七里芬芳
七里芬芳
https://hainiubl.com/topics/36318?
2019-04-22
⋅
4183
⋅
0
⋅
1
初学spark,自己尝试写了个矩阵乘法的小程序。
pair1,pair2分别是两个二元组,记录着一组矩阵的值和编号(矩阵数据是从文件逐行读入,
文件格式是每行有一个数值,要生成行主序的矩阵。
本例中从文件读入100行数据(10*10矩阵),并逐行依次编号0~99,
对应产生100...
MySQL 的某个字段类型为 JSON,导入到 hive 中出现中文乱码?
by
好好学习
https://hainiubl.com/topics/36319?
2019-04-22
⋅
4311
⋅
0
⋅
2
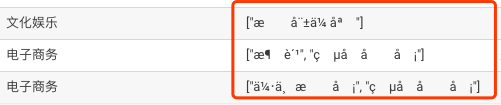
mysql的其他字段(定义的varchar)若为中文导入hive正常显示,但是在mysql中的json字段导入到hive中有中文的话会出现中文乱码?上图用的hue输入select * from XXX limit 3;查询的结果,请...
MySQL 中某个字段定义成 JSON 类型,其数据也是 JSON 类型,导入到 hive 表里面 (在 hive 里面定义成 string),出现乱码?
by
好好学习
https://hainiubl.com/topics/36320?
2019-04-23
⋅
4251
⋅
0
⋅
1

MySQL的原始json数据长这样,导入hive后hue查询显示如下:
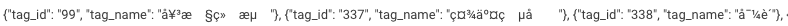
但是在mysql中定义成varchar类型的字段导入到hi...
MapReduce 如何数据切块并进行读取的?
by
 峰谷
峰谷
https://hainiubl.com/topics/36321?
2019-04-23
⋅
2297
⋅
0
⋅
1
比如wordcount这个例子,我的输入文件是一个10G的文件,如果分块的大小是64M,那么就会有多个文件分到不同的节点上面。
但是如果以64M分割,其中一个单词Hello,的“Hel”在【节点1】上面,而“lo”在【节点2】上面。
那么map任务分别在【节点1】和【节点2】上面执行。...
关于音频大数据的存储?
by
 漂泊
漂泊
https://hainiubl.com/topics/36322?
2019-04-28
⋅
2895
⋅
0
⋅
1
**音频、视频大数据是如何存储的呢?**
是用什么框架吗?与 hadoop这一块的存储是不是相似呢?
有没有相关的应用呀?
在 spark 中,Seq 有个 toDF 方法?
by
 秋意浓
秋意浓
https://hainiubl.com/topics/36324?
2019-04-29
⋅
4864
⋅
0
⋅
1
如下代码所示:
private lazy val myTestData1 = Seq(
(1, 1),
(1, 2),
(2, 1),
(2, 2),
(3, 1),
(3, 2)
).toDF("a", "b")
可以看到在Spark中Seq可以直接通过toDF函数,变成Spark自己的存储对象DataFrame, 而这个toDF函数本身是不属于Seq的。我...
我是一个大学生 ,想装 Spark,什么型号的电脑可满足要求?
by
 冰雹
冰雹
https://hainiubl.com/topics/36325?
2019-04-29
⋅
2711
⋅
0
⋅
1
我是一个大学生 ,想装Spark,什么型号的电脑可满足要求?
Mahout 的 ALS 推荐算法输出文件乱码怎么解决?
by
 不忘初心
不忘初心
https://hainiubl.com/topics/36326?
2019-04-29
⋅
2560
⋅
0
⋅
1
用Mahout的ParallelALSFactorizationJob类读入输入文件,格式是(整数,整数,浮点数),但ParallelALSFactorizationJob输出的文件乱码不可读,我没输入任何中文

 晓儒
晓儒
https://hainiubl.com/topics/36327?
2019-04-29
⋅
2687
⋅
0
⋅
1
今天Mongodb里的2张表直接导入hive, hive里“show tables”里显示有3张表,而pyspark“show tables”里显示只有1张表呢?这是什么原因了,另外2张怎么才能读出来咧?备注(已经把机群重启了一次还是不行)
 MindHacker
MindHacker
https://hainiubl.com/topics/36328?
2019-04-29
⋅
2633
⋅
0
⋅
1
MongoDB 可以支撑一般的 OLTP 应用了,Hive/Spark 也已经可以代替大规模的 OLAP 应用,ElastisSearch 则完全领先于数据库自带的全文检索功能。那么 SQL 的生命力是不是会越来越弱了?
Spark/Hbase 是否可以做离线批量计算?
by
 张小果
张小果
https://hainiubl.com/topics/36329?
2019-04-29
⋅
2967
⋅
0
⋅
1
看相关资料,都是Spark/Hive处理批量离线数据,Storm/HBase处理实时数据。
Hive的优点很清晰,结合Spark SQL可以直接用SQL查询,开发效率高。
缺点也很明显,Hive查询时,所有数据遍历检索,查询时间长。
此外,Spark又有Spark Streaming + Kafka + HBas...
hive 中的表数据是怎么分布到集群中不同机器去存储的?
by
 肖海艳
肖海艳
https://hainiubl.com/topics/36330?
2019-04-29
⋅
3146
⋅
0
⋅
1
比如greenplum是通过指定分布键。hive也是一样吗?
如何在 hive 与 pig 中选择?
by
 Perry
Perry
https://hainiubl.com/topics/36331?
2019-04-29
⋅
3045
⋅
0
⋅
1
在进行在数据连接和过滤(jion and filter result data from various sources)阶段,选择hive或者pig,实际作出的取舍是什么?不了解实现原理,有点理解不了二者的优点和缺点.....
已学完 python 基础知识,该如何继续提升算法能力,以及如何过渡到机器学习?
by
 mhcnsk
mhcnsk
https://hainiubl.com/topics/36332?
2019-04-30
⋅
2337
⋅
0
⋅
1
已学完python基础知识,该如何继续提升算法能力,以及如何过渡到机器学习?
为什么 Python 的 project 文件体积那么大?
by
 Colen
Colen
https://hainiubl.com/topics/36333?
2019-04-30
⋅
2629
⋅
0
⋅
1
完全新手,用pycharm创建的项目没有代码的时候有30多M,同时idea一个项目也就几K,这是为什么呢?
Python 如何抓取这个验证码图片?
by
 风口浪尖
风口浪尖
https://hainiubl.com/topics/36334?
2019-04-30
⋅
2413
⋅
0
⋅
1
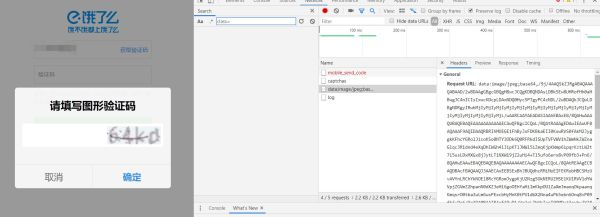
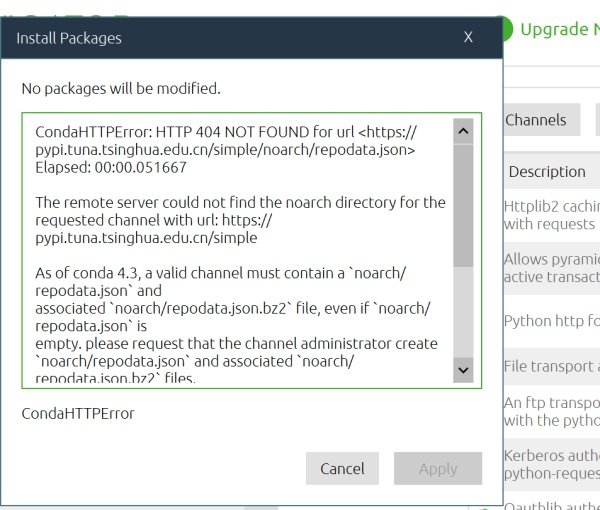
anaconda 为什么安装不了包?
by
 Shihw丶疙瘩
Shihw丶疙瘩
https://hainiubl.com/topics/36336?
2019-04-30
⋅
2569
⋅
0
⋅
1
在anaconda环境下安装包时总是提醒安装路径不对,怎么解决?