关于 “” 的搜索结果, 共 2411 条
kafka 如何删除 topic?
by
 田孟旭
田孟旭
https://hainiubl.com/topics/36266?
2019-04-03
⋅
5774
⋅
0
⋅
1
server.properties 已经设置了
delete.topic.enable=true
auto.create.topics.enable=false
但是删除时候还是报这个问题,
气疯了,kafka这么设计难道智障吗
Topic htmltrack_error is already marked for deletion
如何缓解 Kafka 集群在有大量 topic 时性能快速劣化的问题?
by
 空军一号
空军一号
https://hainiubl.com/topics/36268?
2019-04-03
⋅
7053
⋅
0
⋅
1
线上观测到topic多了就会造成磁盘文件过多退化为随机写和节点负载不均衡. 不涉及技术机密的情况下, 各位能分享下都是怎么缓解乃至解决的吗?
kafka topic 数据如何写入 hdfs?
by
 我是小小美食家
我是小小美食家
https://hainiubl.com/topics/36269?
2019-04-03
⋅
7167
⋅
0
⋅
1
kafka集群的topic是可以动态添加的,添加之后就会有数据写到topic,那么我想问下:我怎么把topic里面的数据写入到hdfs里面,还有是什么时候写呢,怎么停止topic的这个消费?
kafka 发布消息如何达到不重不漏?
by
 凌晨4点的洛杉矶
凌晨4点的洛杉矶
https://hainiubl.com/topics/36270?
2019-04-03
⋅
6780
⋅
0
⋅
1
kafka目前提供了at least once的传递保证,在消费端去重是比较容易的,生产者方面,如果在考虑成本的情况下,如何实现去重,或者幂等性发布
kafka 0.9 之后的版本如何获取 offset 用于计算出 lag 呢?
by
 徐福兴
徐福兴
https://hainiubl.com/topics/36271?
2019-04-03
⋅
5791
⋅
0
⋅
1
想要监控其lag
现在网上找的方法大多是0.8的 各位大牛能不能指点迷津呢?
kafka 如何减少消息时延?
by
 大东
大东
https://hainiubl.com/topics/36272?
2019-04-03
⋅
5830
⋅
0
⋅
1
现在部署3个服务器作为服务集群,集群系统负载不高,平均每秒收发40k左右,从发送者的jmx来看延时比较小,基本都是1ms左右能发送完成,但是接受者似乎时延不稳定,一般在5-8ms左右,有时候跳到20ms-30ms,我的时延判断是根据接收的时候记录当前系统时间和record里面的发...
cdh 集群启用 kerberos 认证出现如下错误?
by
 好好学习
好好学习
https://hainiubl.com/topics/36273?
2019-04-03
⋅
6860
⋅
0
⋅
1
cdh集群启用kerberos认证出现如下错误,该如何解决?

hdfs也是这个错,不知道什么问题?请大神解决
SparkSQL 使用两表查询,表 2 获取表 1 查询的 id 范围范围,测试查询时间有几秒,该如何优化?
by
 DenzelLee
DenzelLee
https://hainiubl.com/topics/36275?
2019-04-09
⋅
2561
⋅
0
⋅
1
sql:select xxx from a where id in(select id from b where t =100) and time =xxx
形如以上的SQL可以做怎样的优化,目前a表为数据表,b表为模板表,where id in的表示为了适应业务上的灵活变化。现在这个sql测试执行时间为几秒,会比数据库慢一些,能有什么好的SQL...
spark Dataset<Row>如何分页获取或者以行位单位遍历获取?
by
 广广
广广
https://hainiubl.com/topics/36276?
2019-04-09
⋅
5326
⋅
0
⋅
1
dataset<Row>的limit、take方法只有获取前多少行,但我想以行的形式遍历获取,或者分页形式,只要不是一次全部获取就可以。全部获取内存不够
spark 如何计算自己占用内存的大小?
by
 倩倩
倩倩
https://hainiubl.com/topics/36277?
2019-04-09
⋅
3643
⋅
0
⋅
1
看blog说,spark可以通过周期性地采样近似估算内存的大小,这是怎么做到的?
如何用 scala 实现 dataframe 添加自增序号列,并且将序号列放在第一列?
by
 coxx
coxx
https://hainiubl.com/topics/36278?
2019-04-09
⋅
5190
⋅
0
⋅
1
我用withColumn对dataframe增加了一个自增序号列,但是序号列是在最后一列,用select方法将序号列放在第一列的时候序号值发生错误
spark-sql -f aa.sql 执行 sql 文件为什么文件开头报错就直接退出来了,不能全部执行?
by
 独醉在今朝
独醉在今朝
https://hainiubl.com/topics/36279?
2019-04-09
⋅
3562
⋅
0
⋅
1
spark-sql -f aa.sql执行sql文件为什么文件开头报错就直接退出来了,不能全部执行?
sparksqlselect.join.group 是会对应生成什么样的 rdd.再划分 stage 的?
by
 盛宏伟
盛宏伟
https://hainiubl.com/topics/36280?
2019-04-09
⋅
2614
⋅
0
⋅
1
sparksqlselect.join.group是会对应生成什么样的rdd.再划分stage的?
Spark DataFrame 筛选数据问题?
by
 匡时济世
匡时济世
https://hainiubl.com/topics/36281?
2019-04-09
⋅
2842
⋅
0
⋅
1
现在的spark.Dataframe如下 我希望找出MAC字段第8位在是'2'或 '3' 或 'A'的所有行,请问怎么操作?

我使用主要pyshaprk,如果能用pyspark回答就最好了,Scala和Java也可以~
怎么在 Mac 上配置 PyMesh?
by
 王康
王康
https://hainiubl.com/topics/36285?
2019-04-11
⋅
3305
⋅
0
⋅
1
因为科研需要,要使用第三方库PyMesh(项目地址:https://github.com/PyMesh/PyMesh),我按照官网的教程,用docker配置可用,但是下载源代码后,在用cmake编译第三方库的时候出现错误。现在有两个问题:
1.用Docker配置成功的话,能不能在自己的IDE里面通过import pymes...
这个 python 函数的传参数错在了哪里?
by
 李腾飞
李腾飞
https://hainiubl.com/topics/36286?
2019-04-11
⋅
2805
⋅
0
⋅
1
为什么这一句img1 = self.newImg(img1, img2, False)
每次传去的参数img1都是一样的呢?都是self.imgInfoList[0],
按理这个img1的值每调用一次newImg()就会改变哈,求指导,在线等,谢谢
一下是部分脚本
 hadooper
hadooper
https://hainiubl.com/topics/36287?
2019-04-11
⋅
2392
⋅
0
⋅
1
已经安装好 anaconda3 和 python3.5。请问如何正经使用 Jupyter notebook?
by
 Whalley
Whalley
https://hainiubl.com/topics/36288?
2019-04-11
⋅
2957
⋅
0
⋅
1
anaconda在c盘,python_files也在c盘。 求大神教,如何在Jupyter notebook中正常运行已有的python程序。
Python 如何正确调用 vissim 的 GetResult?
by
 浅唱
浅唱
https://hainiubl.com/topics/36289?
2019-04-11
⋅
5101
⋅
0
⋅
1
这是源代码
# coding=utf-8
import win32com.client as COM
vissim_com=COM.Dispatch("Vissim.Vissim")
vissim_com.LoadNet('D:\\vissim\\test\\21.inp')
vissim_com.LoadLayout('D:\\vissim\\test\\vissim.ini')
vnet=http://vissim_com.Net
sim=vissim_com.S...
pycharm 怎么快速跳出""或者 ()?
by
 冥
冥
https://hainiubl.com/topics/36290?
2019-04-11
⋅
2550
⋅
0
⋅
1
每次我都是用方向右键,或者"和)键跳出的,有没有更方便快捷的方法啊?
anaconda 安装了 pyqt5 后,打不开 spyder,怎么办?
by
 半杯湖底沙
半杯湖底沙
https://hainiubl.com/topics/36291?
2019-04-11
⋅
4094
⋅
0
⋅
1
anaconda能打开prompt和jupter,navigator和spyder都打不开,连图标都没有显示,什么都没出现
numpy 的数据类型为 np.object 时,矩阵运算时支持那些加速机制吗?
by
 zqlchlh
zqlchlh
https://hainiubl.com/topics/36292?
2019-04-11
⋅
3184
⋅
0
⋅
1
numpy的底层是C和Fortran写的,基于blas有一些加速机制。近期,在使用numpy时,数据元素的类型是object类型,并且对该类型重写了部分基础运算的魔术方法,例如加法,乘法。在进行np.sum或np.dot时,通过看CPU效率,似乎并没有采用并行机制?请问有什么方法可以实行numpy...
Python 的游戏模块只有 pygame 吗?
by
 x843974585
x843974585
https://hainiubl.com/topics/36293?
2019-04-11
⋅
2400
⋅
0
⋅
1
还有没有其他的?
JavaStreamingContextFactory 在 spark2.3 中找不到了?
by
 菜鸟程序狗
菜鸟程序狗
https://hainiubl.com/topics/36294?
2019-04-14
⋅
3736
⋅
0
⋅
1
spark1.6中的JavaStreamingContextFactory类,在spark2.3中被哪个类替代了,
storm 怎么调用 python exe 可执行文件?
by
 韦晓阳
韦晓阳
https://hainiubl.com/topics/36295?
2019-04-15
⋅
3347
⋅
0
⋅
3
为了防止python代码泄露,将python脚本弄成exe可执行文件,执行器该怎么调用?
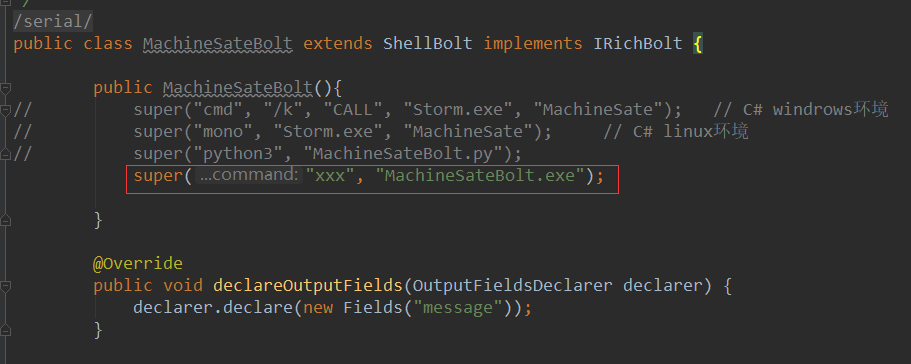
storm 怎样均衡的处理 kafka 数据?
by
 shishuai19910217
shishuai19910217
https://hainiubl.com/topics/36296?
2019-04-15
⋅
3052
⋅
0
⋅
3
现状: 在kafka定义了一个主题 topic_log (只有一个分区) storm去消费这个主题
现有10个工程先后的向topic_log添加数据 (工程A先向topic_log发布消息 工程B后发布)
storm在处理数据的时候就会先处理工程A然后再处理工程B 这样会导致 storm处理工程B的时间延迟...
spark 在运行过程中 gc 时间太长 怎么处理?
by
 李鴻飛
李鴻飛
https://hainiubl.com/topics/36298?
2019-04-17
⋅
5217
⋅
0
⋅
1
spark在在运行过程中core设置为400 但是执行到400整数倍的时候 任务就会卡一会儿 查看 发现gc时间比较长;任务是使用sql直接对dataframe进行操作;任务时间1.3h gc时间达到37min 从web ui中查看的;已经在使用的udf函数中 尽量避免了new对象和对象拷贝
停止 spark 时原有 worker 没有成功停止,再启动时又新增了 worker,有什么影响吗?
by
 Alex
Alex
https://hainiubl.com/topics/36301?
2019-04-17
⋅
2640
⋅
0
⋅
1
最初stop时我没注意到没有成功stop,就进行了start,导致目前每个slave上有两个worker,会有什么影响吗?我又试了下stop,新增的worker可以停止,但最初的worker仍然没有停止。
spark 框架构建时这算不算错误,警告级别,不影响正常运行吧?
by
 M先生
M先生
https://hainiubl.com/topics/36302?
2019-04-17
⋅
2701
⋅
0
⋅
1
kafka 消费者怎样每次只消费 30 条?
by
shishuai19910217
https://hainiubl.com/topics/36304?
2019-04-19
⋅
4277
⋅
0
⋅
1
我有 3个主题 每个主题有3个分区 ?
实现:每个分区取10条记录 (一个分区一次只消费10条)最终取出 3(主题)*10*3(分区)=90条记录