关于 “” 的搜索结果, 共 2411 条
请问我哪俩个地方出问题了?
by
 生亦何欢
生亦何欢
https://hainiubl.com/topics/36018?
2019-01-14
⋅
2796
⋅
0
⋅
1
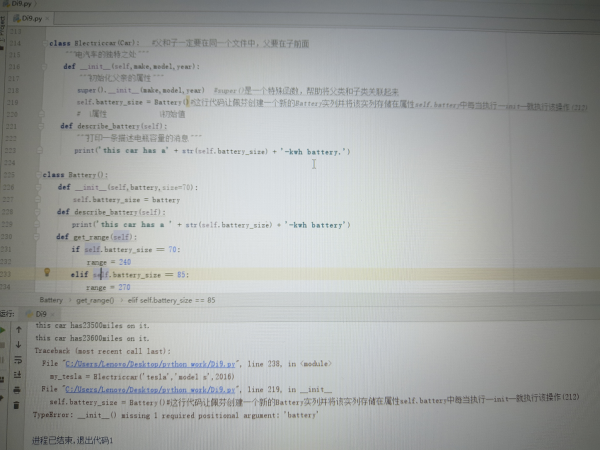
为什么会显示_init_里面缺少一个位置参数Battery
Error: module 'wave' has no attribute 'open'如何如何解决?
by
生亦何欢
https://hainiubl.com/topics/36019?
2019-01-14
⋅
4319
⋅
0
⋅
1
python 3.7 .0 AttributeError: module 'wave' has no attribute 'open'
Pycharm 中 tensorflow 无法运行?
by
生亦何欢
https://hainiubl.com/topics/36020?
2019-01-14
⋅
3077
⋅
0
⋅
1
正在调试BERT开放的Python代码。但是“import tensorflow”部分一直报错(用pip或pip3安装同样报错),其他模块都能运行。想请教一下,在BERT算法中,如何能让tensorflow顺利运行,或者不能运行的原因可能是什么?
python 爬虫,使用 scrappy-Redis 框架中 RedisCrawlSpider 怎么登陆?
by
 卢本伟牛X
卢本伟牛X
https://hainiubl.com/topics/36021?
2019-01-14
⋅
2814
⋅
0
⋅
1
使用RedisCrawlSpider爬网站想先登陆,需要怎么做,改写那些函数,之后怎么办?
python pivot_table 后,如何计算某一列长度?
by
 十年
十年
https://hainiubl.com/topics/36022?
2019-01-14
⋅
2918
⋅
0
⋅
1
pivot_test_data=pd.read_csv('pivot_test_data.csv')
pivot_test=pd.pivot_table(
pivot_test_data,
index='uid',
values='donetime',
aggfunc=len,
fill_value=0,
margins=True
)
print(len(pivot_test['uid']))
在这一步报错,key error。
此外,我想...
spark-phoenix 一直出现一个 bug?
by
卢本伟牛X
https://hainiubl.com/topics/36024?
2019-01-17
⋅
7977
⋅
0
⋅
2
18/09/19 21:24:06 INFO ConnectionQueryServicesImpl: HConnection established. Stacktrace for informational purposes: hconnection-0x2d38edfd java.lang.Thread.getStackTrace(Thread.java:1559)
org.apache.phoenix.util.LogUtil.getCallerStackTrace(LogUtil...
scan 查出来的 row 是 rowkey 吗?
by
 张凌天
张凌天
https://hainiubl.com/topics/36025?
2019-01-17
⋅
2538
⋅
0
⋅
1
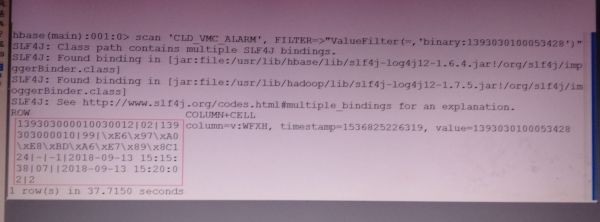
从hbase中用scan查出来的row,用get查不到数据。请大神们帮忙查看一下主键是否有加密?
spark 读取 MongoDB,进行计算,MongoDB 游标超时如何解决?
by
生亦何欢
https://hainiubl.com/topics/36026?
2019-01-17
⋅
4017
⋅
0
⋅
1
最近在单机情况下,发现spark在读取MongoDB进行计算的时候,MongoDB游标老是超时。网上看了下解决方案。
1.设置MongoDB的游标超时时间,但是貌似时间设置过长,会导致oom的情况发生。
2.读取MongoDB之后马上cache rdd,然后action存入本地内存。但是发现还是会执...
求 spark 大神帮忙看下,用 scala 操作 dataframe 转 rdd 的时候,row 对象的取值问题?
by
十年
https://hainiubl.com/topics/36027?
2019-01-17
⋅
3311
⋅
0
⋅
1
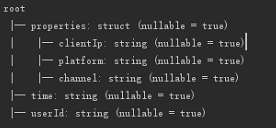
我的dataframe约束是上面这样子的。
dataFrame.rdd.map(row => (row.getAs[Struct]("properties"), row.getAs[String]("userId"))).foreach(println)
上面的代码我可以取第一层的...
Hive 为什么不支持日期格式?
by
 听说
听说
https://hainiubl.com/topics/36028?
2019-01-17
⋅
2624
⋅
0
⋅
1
今天做Oracle存储过程迁移到Hadoop上,我看到存储过程里面有个条件是XXX=to_date(yyyy,'yyyymmdd'),于是转换成hadoop应该是类型匹配,XXX是个date类型的,但是我使用的Hadoop自定义函数'${TXNDATE}',但是这是一个字符串类型的,我需要将这个转换成YYYYMMDD的日期格式,...
sparksqlselect.join.group 是会对应生成什么样的 rdd.再划分 stage 的?
by
 天行者
天行者
https://hainiubl.com/topics/36029?
2019-01-17
⋅
2388
⋅
0
⋅
1
如题
Spark 里 RDD 数据怎么拿到 hashmap 中呢?
by
卢本伟牛X
https://hainiubl.com/topics/36033?
2019-01-23
⋅
3101
⋅
0
⋅
0
val sc = new SparkContext(conf)
val rdd01 = sc.textFile("G:/input/a.txt")
val rdd02 = rdd01.map(x=>(x.split("\t")(0),x.split("\t")(1).trim.toInt))
var map2 = new mutable.HashMap[String,Int]()
rdd02.foreach(println(_))
rdd02.foreach(x=>...
如何通过 python 连接到远程服务器的 sparksql,求指导,各位大佬,?
by
生亦何欢
https://hainiubl.com/topics/36034?
2019-01-23
⋅
2778
⋅
0
⋅
1
如何通过python连接到远程服务器的sparksql,求指导,各位大佬,?
大数据工程师的日常工作内容是干嘛?
by
十年
https://hainiubl.com/topics/36035?
2019-01-23
⋅
2457
⋅
0
⋅
1
现在在做Java开发,利用下班时间在自学大数据。想了解下大数据工程师的日常工作内容,好有所针对的学。目前Hadooop权威指南看了四遍,hive权威指南看了三遍了,内容好多,怕走弯路,希望在做大数据的工程师们说一下
如何理解 fine-grained 和 coarse-grained?
by
张凌天
https://hainiubl.com/topics/36036?
2019-01-23
⋅
3876
⋅
0
⋅
1
最近在看UCBerkeley的几年前的一篇讲RDD的论文。文中提到了coarse-grained update和fine-grained update。图像分析中似乎也有fine-grained classification。对这两个形容词,或者说这两个形容词定义的操作应该怎么理解?
Spark submit 参数调优是否有一定标准或者规律?
by
听说
https://hainiubl.com/topics/36037?
2019-01-23
⋅
2568
⋅
0
⋅
1
看了很多文章,但是大多数都只是告诉你这四个参数是什么作用。
唯有16年的Spark Summit大会上Top 5 Mistakes When Writing Apache Spark Applications演讲专题提到了一种计算方法(固定executor-cores为5,每太理解为什么他说超过5 hdfs 的thoughout会降低)并手把手的...
请问批量操作多台服务器的脚步在哪里下载呢?
by
 o329O
o329O
https://hainiubl.com/topics/36038?
2019-01-23
⋅
2590
⋅
0
⋅
1
[Hadoop 系列教程(二):批量操作多台服务器](http://www.hainiubl.com/topics/80)
ambari 快速批量部署方案?
by
 韦晓阳
韦晓阳
https://hainiubl.com/topics/36041?
2019-02-11
⋅
3261
⋅
0
⋅
1
业务是基于工业精密制造业,后面随着项目的增多,需要对ambari平台快速批量的部署,研究了docker,都说docker存数据不太靠谱,集群是伪分布式,服务器资源占用率高,,,怎么优化,有没有其他更好的方案?
IDEA 远程调试 Hadoop 压缩与解压缩时客户端无法连接主机?
by
卢本伟牛X
https://hainiubl.com/topics/36045?
2019-02-15
⋅
2705
⋅
0
⋅
1
跟着教程想实现通过IDEA远程调试压缩与解压缩。代码编写完成后导出jar文件到共享目录下,在该目录下本地运行正常。但是通过配置远程调试进行执行时,IDEA一直无法连接到服务器,linux端已经处于监听状态。求大神指教。
linux端已经处于监听状态:

hadoop2.9.1 测试单机模式时报错,不懂怎么解?
by
张凌天
https://hainiubl.com/topics/36055?
2019-02-20
⋅
2393
⋅
0
⋅
1
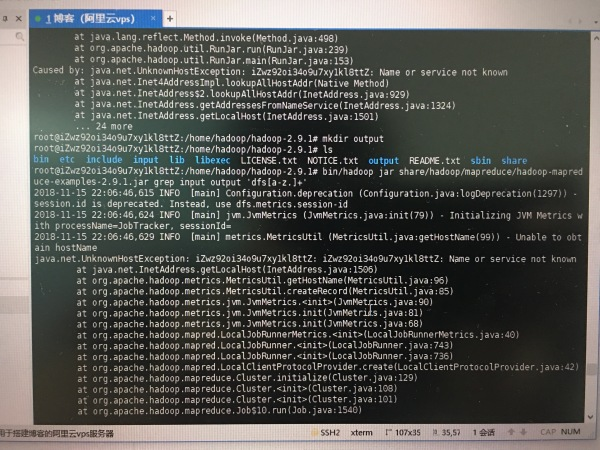
我测试单机模式时,input和output文件夹都创建好了,然后把etc/hadoop文件夹下的xml拷贝到了input里,然后执行了如图的命令,但报错了,哪位大佬能教教我?
hive 里面两种 sql 写法的区别?
by
十年
https://hainiubl.com/topics/36056?
2019-02-20
⋅
2606
⋅
0
⋅
1
hive里面select * from table与from table select * 这两种写法有什么区别呢?
想输出 ASCII 的图形,用变量 i 里面的数字所指定的图案,怎么办?
by
 螺旋的邂逅
螺旋的邂逅
https://hainiubl.com/topics/36061?
2019-02-28
⋅
3140
⋅
0
⋅
1

我写的代码是不对的,不知道怎么修改
大数据启动 ambari 失败?
by
卢本伟牛X
https://hainiubl.com/topics/36072?
2019-03-07
⋅
2328
⋅
0
⋅
1
今天在做大数据平台的时候启动ambari-Server时候遇到了这个error,我分为两个节点,一个master一个slave1,同样的步骤,我在master节点启动时遇错,在slave1节点成功启动,找了两天不知道问题在哪,两台机器的MySQL和JAVA -version都是正确且成功显示的,平台是先电大数...