关于 “” 的搜索结果, 共 2412 条
hadoop_op1.zip 缺失?
by
 Cq806228809
Cq806228809
https://hainiubl.com/topics/876?
2018-09-09
⋅
3120
⋅
0
⋅
3
请问,老师能帮忙解决一下吗?
问题章节:海牛部落 Hadoop 系列教程(二):批量操作多台服务器
4. 批量执行与批量分发脚本使用#
首先切换到hadoop用户
ssh到别一台机器上执行命令全,例子:ssh hadoop@s1.hadoop hostname
scp一个文件到别一台机器上,例子:scp /...
使用 yum 源安装 gcc 出现如下错误如何解决?请大神指点
by
 好好学习
好好学习
https://hainiubl.com/topics/877?
2018-09-10
⋅
9071
⋅
0
⋅
1
[root@mini ~]# yum -y install gcc
已加载插件:fastestmirror, langpacks
Loading mirror speeds from cached hostfile
正在解决依赖关系
--> 正在检查事务
---> 软件包 gcc.x86_64.0.4.8.5-4.el7 将被 安装
--> 正在处理依赖关系 cpp = 4.8.5-4.el7,它被软件...
视频中的课件跟资料库的帖子不是一个老师吗?
by
 poponely
poponely
https://hainiubl.com/topics/890?
2018-09-12
⋅
2752
⋅
0
⋅
1
牛油们,腾讯课堂的视频里面的课件在部落或者百度云有吗?好像跟资料库里面的帖子不一样呢。刚来求教。
大数据 spark,hadoop 和虚拟化技术 cloudstack,openstack 哪一个更有发展前景?
by
 zhuantou
zhuantou
https://hainiubl.com/topics/892?
2018-09-12
⋅
2701
⋅
0
⋅
1
hadoop已经发现比较久,我是一个初学者,我现在纠结应该走哪一个方向,我想从OpenStack,spark选一个,请高手指点。如果高手有其他观点,请指教。
java 学习到哪个阶段才可以学习大数据 docker spark 等?
by
zhuantou
https://hainiubl.com/topics/893?
2018-09-12
⋅
2860
⋅
0
⋅
1
现在在实习 以后想往 大数据方向靠拢 请问各位有经验的 java要学习到什么阶段才能更好的去学习有关大数据相关的知识
请问 Hadoop/Java 技术开发主要是做什么的?
by
zhuantou
https://hainiubl.com/topics/894?
2018-09-13
⋅
2749
⋅
0
⋅
1
最近拿到秒针系统的校招offer,给的岗位是Hadoop/Java技术开发,不知道具体是做什么的,之前做Java web比较多,但是赶紧如果走技术路线的话,大数据比较长久,希望各位给给建议
Scala 在大数据处理方面有何优势?
by
zhuantou
https://hainiubl.com/topics/895?
2018-09-13
⋅
2678
⋅
0
⋅
1
Scala 在大数据处理方面有何优势?
大数据开发(spark,scala)能做什么?Scala 在大数据处理方面有何优势?
by
zhuantou
https://hainiubl.com/topics/898?
2018-09-18
⋅
3061
⋅
0
⋅
1
大数据开发(spark,scala)能做什么?Scala 在大数据处理方面有何优势?
MapReduce 应该优化哪些配置?
by
 shishuai19910217
shishuai19910217
https://hainiubl.com/topics/899?
2018-09-18
⋅
3170
⋅
0
⋅
1
MapReduce应该优化哪些配置?
hadoop2.x 中的 mapreduce.map.memory.mb 和 mapred.child.java.opts 应该设置多大才合适?应遵循什么设置规则?
by
shishuai19910217
https://hainiubl.com/topics/900?
2018-09-18
⋅
4608
⋅
0
⋅
1
hadoop2.x中的mapreduce.map.memory.mb和mapred.child.java.opts 应该设置多大才合适?应遵循什么设置规则?
hadoop lzo 如何安装 ?最好有个文档谢谢
by
shishuai19910217
https://hainiubl.com/topics/901?
2018-09-18
⋅
3307
⋅
0
⋅
1
hadoop lzo 如何安装 ?
hbase 分布式集群 所有的请求都集中在一个 regionserver 节点上是怎么回事?
by
shishuai19910217
https://hainiubl.com/topics/904?
2018-09-19
⋅
4454
⋅
0
⋅
5
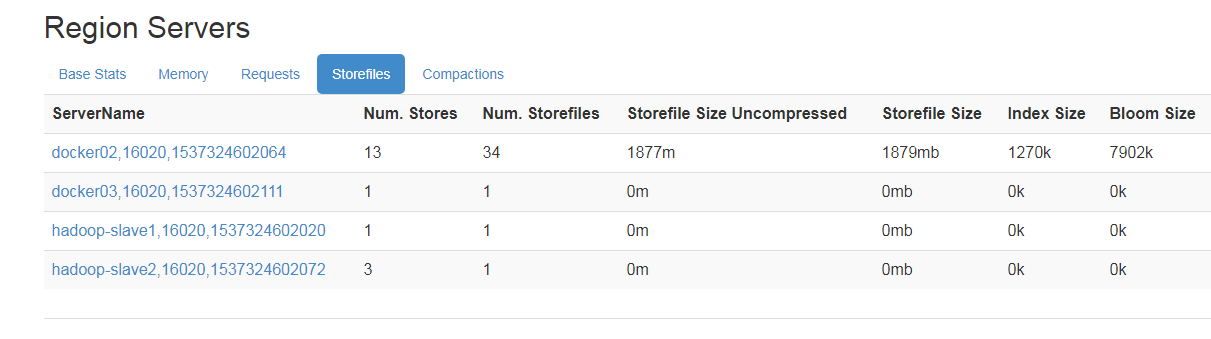
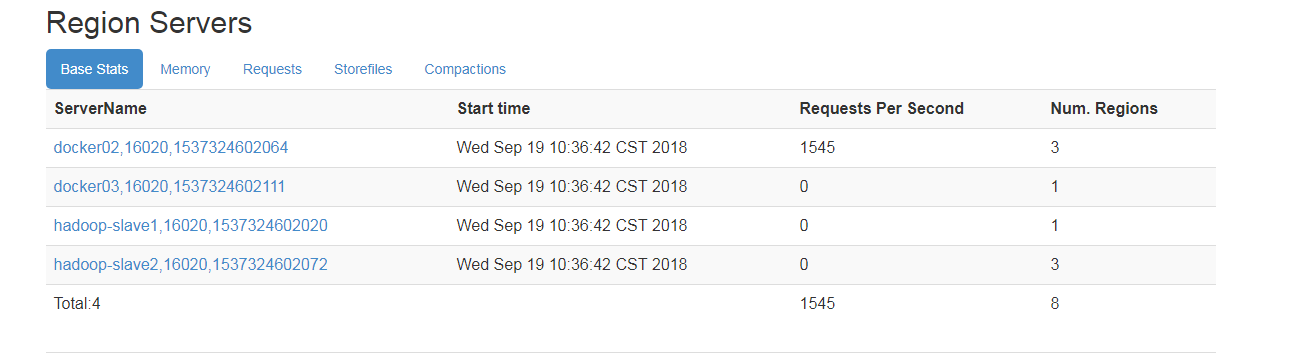
批量操作服务器中缺失资源:hadoop_op1.zip?
by
 DHAKJL
DHAKJL
https://hainiubl.com/topics/905?
2018-09-26
⋅
2829
⋅
0
⋅
1
rt
The import org.apache.hadoop.mapreduce.Job cannot be resolved?
by
Cq806228809
https://hainiubl.com/topics/906?
2018-09-28
⋅
8305
⋅
0
⋅
4
请问,老师这个应该怎么解决?
问题:Windows 开发 wordcount 在敲写job代码:
Job job = new Job(getConf(),"wordcount");
时,红线报错提示:
Job cannot be resolved to a type
'Job cannot be resolved to a type
The import org.apache.hadoop.mapreduce.Job can...
急求 spark 视频教程?
by
shishuai19910217
https://hainiubl.com/topics/907?
2018-09-29
⋅
2666
⋅
0
⋅
2
急求spark视频教程
CDH 如何配置才能使得集群资源利用率达到最高?
by
 歌唱祖国
歌唱祖国
https://hainiubl.com/topics/908?
2018-10-07
⋅
4915
⋅
0
⋅
1
CDH5.14.4有9个datanode,每个datanode的资源为4cores/28GB,但是每次跑hive,spark看到内存都没有利用完,比如利用了33cores但是内存仅仅使用到15GB。
1.请问该在CDH上如何配置yarn才会尽最大程度利用完集群的资源?
2.还有有时发现共启动1个container,但是内存也是...
hive 查询经过压缩后有 100GB 的.gz 格式的文件数据,使用 select * from 能够查询出来,为何不能做计算?
by
歌唱祖国
https://hainiubl.com/topics/909?
2018-10-07
⋅
6819
⋅
1
⋅
6
老师您好,我在生产上遇到一个这样一个情况,我们有46亿的数据,有1TB的大小,占用hdfs就是3个多TB了,我们采用gz格式将数据进行压缩,建立hive表,将数据load into到hive表了。表数据能够使用select * from table能查询出数据,但是在对表进行计算时(select count(1))...
CDH Spark 程序调优 spark.yarn.executor.memoryOverhead 该如何配置呢?
by
歌唱祖国
https://hainiubl.com/topics/939?
2018-10-10
⋅
9015
⋅
0
⋅
1
老师好,我遇到一个问题如图所示
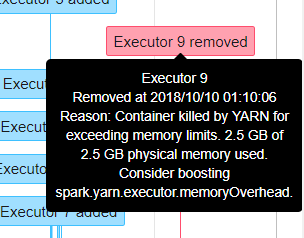
1.CDH Spark程序调优spark.yarn.executor.memoryOverhead该如何配置呢?主要是参考什么参数的值?
2.yarn.nodemanager.resource.memory-mb,spark.execu...
spark Dataset.createTempView 作用是什么?
by
shishuai19910217
https://hainiubl.com/topics/941?
2018-10-11
⋅
6064
⋅
0
⋅
1
DataFrameReader reader = sparkSession.read().format("jdbc")
.option("url", "jdbc:mysql://192.168.10.212:3306/orm")
.option("dbtable", "tf_f_project")
.option("user", "koala")
.option("password", "koala")...
idea 的 log4j 出现很诡异的错误,求解决?
by
好好学习
https://hainiubl.com/topics/942?
2018-10-11
⋅
5194
⋅
0
⋅
1
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/log4j/Level
at org.apache.spark.internal.Logging$class.initializeLogging(Logging.scala:111)
at org.apache.spark.internal.Logging$class.initializeLogIfNecessary(Logging.scala:10...
storm topology 作业的监控和告警,有什么好的方案?
by
 韦晓阳
韦晓阳
https://hainiubl.com/topics/943?
2018-10-11
⋅
3313
⋅
0
⋅
1
storm topology作业的监控和告警,有什么好的方案?
执行命令 yum install -y gcc gcc-c++ pcre-devel zlib-devel 出现如下错误?求大佬解决
by
好好学习
https://hainiubl.com/topics/944?
2018-10-12
⋅
11435
⋅
0
⋅
2
执行命令 yum install -y gcc gcc-c++ pcre-devel zlib-devel 出现如下提示
[root@mini librdkafka]# yum install -y gcc gcc-c++ pcre-devel zlib-devel
已加载插件:fastestmirror, langpacks
Loading mirror speeds from cached hostfile
软件包 gcc-4.8.5-4.el7...
为什么 mapreduce 压缩失效?
by
 菜鸟程序狗
菜鸟程序狗
https://hainiubl.com/topics/14179?
2018-10-18
⋅
3227
⋅
0
⋅
2
mapreduce中设置了
job.setOutputFormatClass(SequenceFileOutputFormat.class);
SequenceFileOutputFormat.setCompressOutput(job, true);
SequenceFileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
SequenceFileOutputFormat.setOutputC...
Python3 操作 hive,pip 安装 sasl 失败,已经安装 gcc,请问如何能够完成第三方库的安装?
by
歌唱祖国
https://hainiubl.com/topics/14181?
2018-10-18
⋅
9233
⋅
0
⋅
2
如题,Python3操作hive,pip安装sasl失败,已经安装gcc,请问如何能够完成第三方库的安装?
已经成功使用一下命令安装,但是甚至yum install gcc在pip install sasl时还是会出现报错。请问老师有什么办法能够fix这个问题吗?
yum install cyrus-sasl-lib.x86_64
yum...
cdh 集群 python3 用 pyhive 操作 hive,请问如何能够实现呢?
by
歌唱祖国
https://hainiubl.com/topics/14182?
2018-10-18
⋅
4762
⋅
0
⋅
4
老师好,我的Hive是在cdh上面的,hive用户名是cdhtest,密码是123123,请问我该怎样才能用pyhive查询hive的数据?
```
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# hive util with hive server2
from pyhive import hive
conn = hive.Connection(host='10...
测试工具 TeraSort 如何支持可压缩??
by
菜鸟程序狗
https://hainiubl.com/topics/14183?
2018-10-19
⋅
3610
⋅
0
⋅
1
想把Hadoop的测试工具terasort改成可压缩的格式,
TeraGen类添加了
FileOutputFormat.setCompressOutput(job, true);
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
job.setOutputFormatClass(TeraOutputFormat.class);...
spark jobserver 需要另外安装的吗,该怎么安装,它的作用是什么?
by
歌唱祖国
https://hainiubl.com/topics/14185?
2018-10-23
⋅
4060
⋅
0
⋅
2
老师,我看了论坛上面关于spark的内容,没有讲到spark jobserver,它的作用是什么?spark jobserver需要另外安装的吗,该怎么安装,该如何开启,提交作业的方式有哪些?
sparksql 读取 kafka 报错?
by
菜鸟程序狗
https://hainiubl.com/topics/14195?
2018-10-23
⋅
3921
⋅
0
⋅
2
SparkSession spark = SparkSession
.builder()
.appName("VideoStreamProcessor")
.master(prop.getProperty("spark.master.url"))
.getOrCreate();
Dataset<Row> ds = spark.readStream().format("kafka")
.option(...
JavaDStream 转为 JavaRDD?
by
菜鸟程序狗
https://hainiubl.com/topics/14217?
2018-10-29
⋅
4371
⋅
0
⋅
2
JavaDStream如何转为JavaRDD?最好可以给个例子
flume 收集的数据是否有序?
by
韦晓阳
https://hainiubl.com/topics/14219?
2018-10-30
⋅
3833
⋅
0
⋅
2
flume单实例和集群收集的数据是否有序?flume往两个kafka丢数据,怎么flume所在的kafka集群能接收到数据,另一个kafka集群接收不到数据,,,都是内网,网段都一样,,,是不是ssh的原因啊?
flume.conf
---------------------------------------------------------...