关于 “” 的搜索结果, 共 2412 条
cloudera manager 安装出现权限问题?
by
 xiaojiaobin
xiaojiaobin
https://hainiubl.com/topics/667?
2018-06-20
⋅
3181
⋅
0
⋅
3
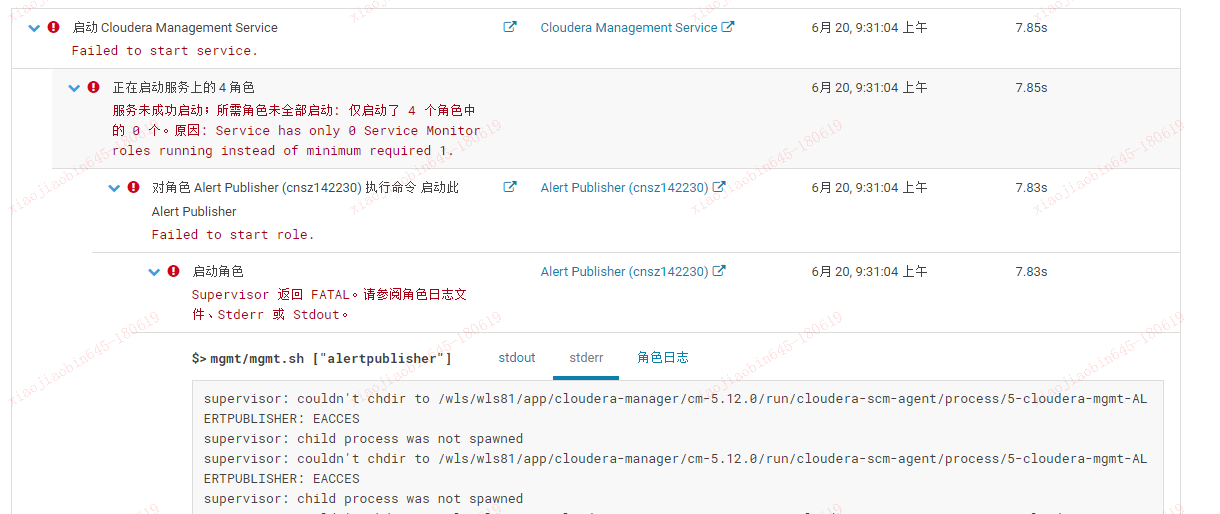
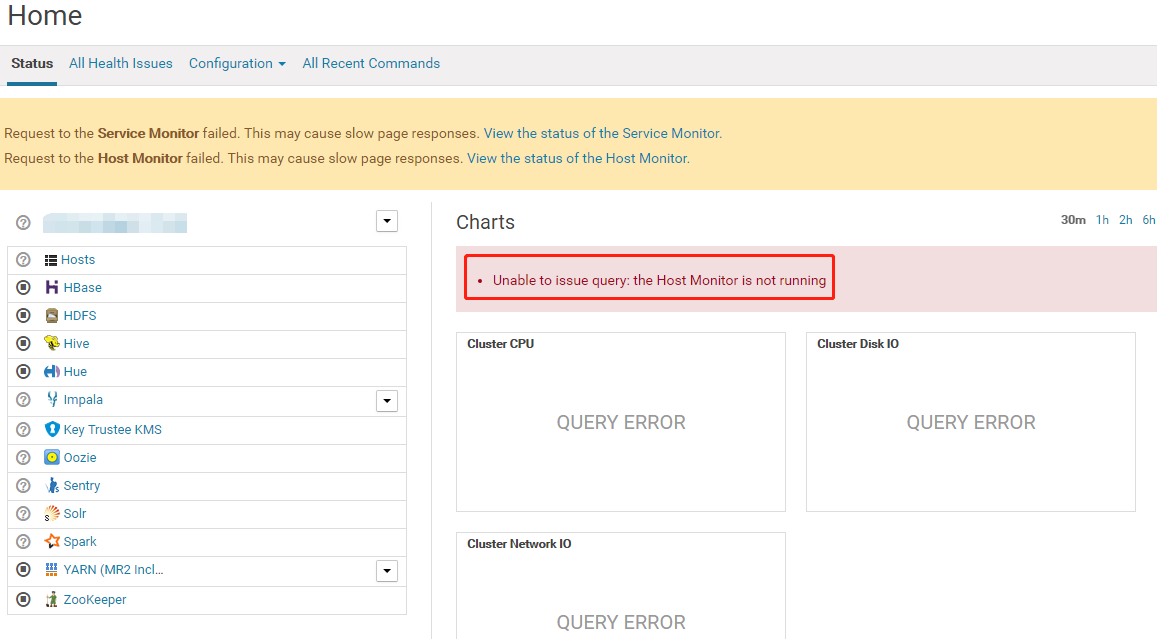
CDH 关闭 KMS 服务后重启无法监控到 host,应用也无法监控和管理,如何恢复监控?
by
 歌唱祖国
歌唱祖国
https://hainiubl.com/topics/668?
2018-06-20
⋅
6107
⋅
0
⋅
1
查看event server的日志
```
2018-06-19 22:01:33,380 INFO com.cloudera.enterprise.ssl.SSLFactory: Using configured truststore for verification of server certificates in HTTPS...
sqoop 将 MySQL 表的数据导入到 hive 报错,怎么解决?
by
歌唱祖国
https://hainiubl.com/topics/669?
2018-06-20
⋅
3953
⋅
0
⋅
5
执行的脚本
```
$ sqoop import --hive-import --connect jdbc:mysql://localhost:3306/g?useSSL=false --username test --password test --table brand --fields-terminated-by '\t' --delete-target-dir --num-mappers 1 --hive-database zc --hive-table brand
`...
storm 通过 eclipse 实现数字累计,运行时报错 :java.lang.NoClassDefFoundError: org/apache/commons/lang/builder/HashCodeBuilder???
by
 hyf
hyf
https://hainiubl.com/topics/670?
2018-06-21
⋅
6198
⋅
0
⋅
1
在eclipse上编写storm本地程序,运行时报错,找不到类问题

下面是pom.xml,添加的主要是storm-core
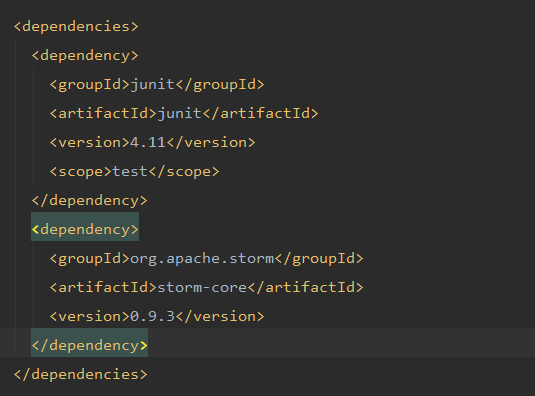
请...
threadlocal 和线程局部变量区别是什么?
by
 ling775000
ling775000
https://hainiubl.com/topics/671?
2018-06-24
⋅
3970
⋅
0
⋅
1
感觉他们的作用是一样的,想知道区别是什么?
java se 第 179 课中,简易卖票系统的问题?
by
 豆豆
豆豆
https://hainiubl.com/topics/708?
2018-07-01
⋅
3390
⋅
0
⋅
1
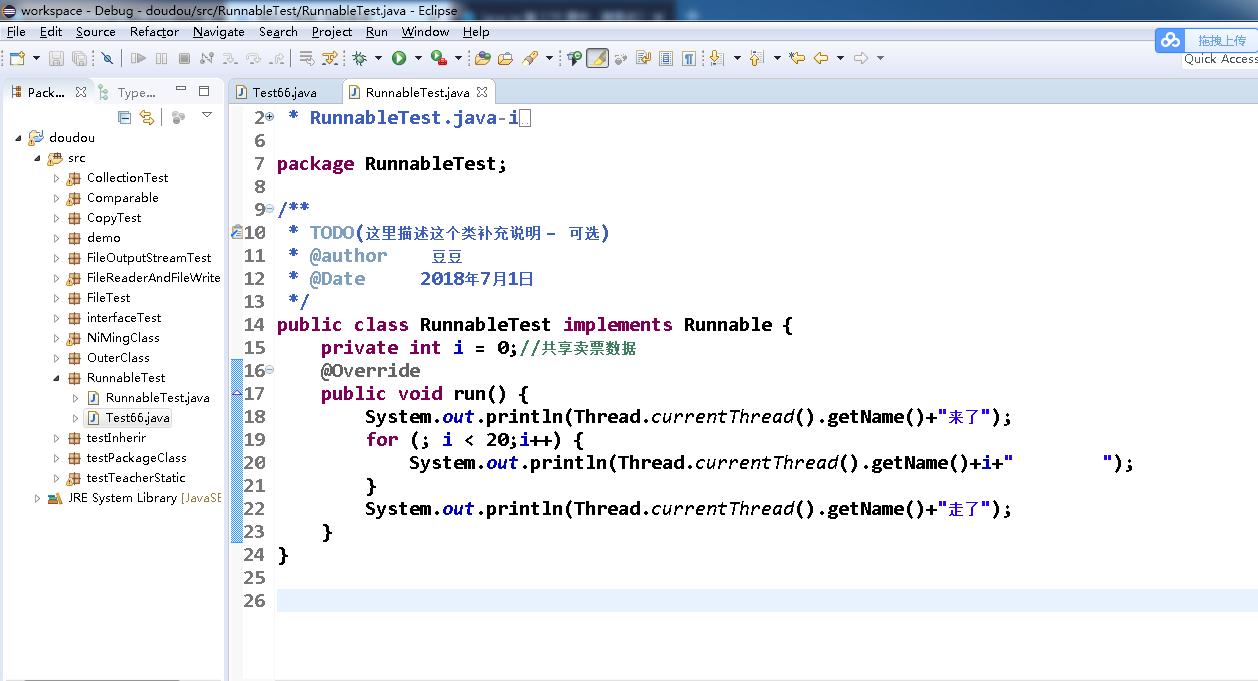
以上是票的库存,
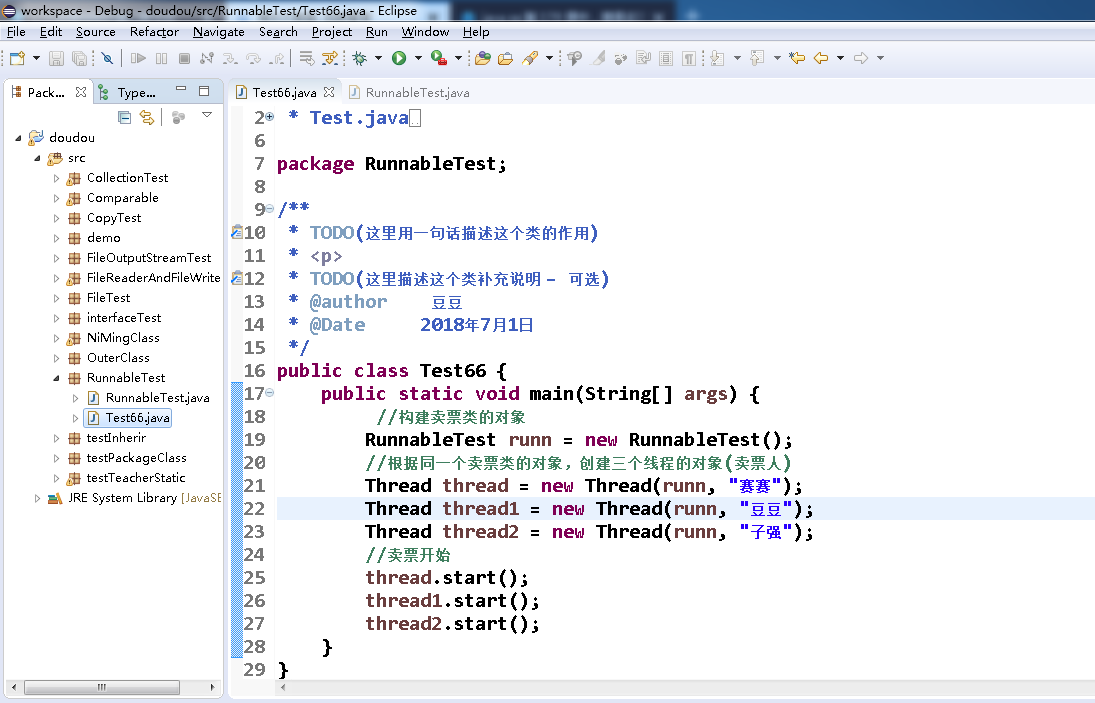
**老师好,是不是因为我没有按照视频里操作将 Eclipse调节成单核处理,导致运行结果为...
关于 spark 写 hbase 用 bulkload 方式的问题?
by
 魏超
魏超
https://hainiubl.com/topics/721?
2018-07-03
⋅
6101
⋅
0
⋅
2
各位大佬
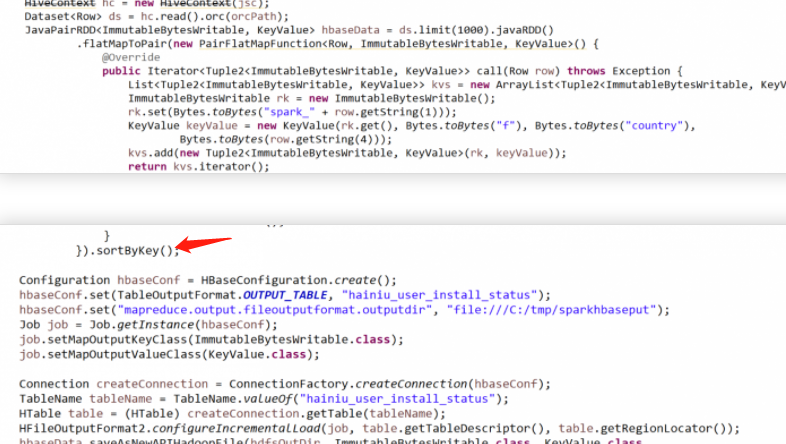
我报出错误如下
java.io.IOException: Added a key not lexically larger than previous. Current cell = 11000031219513/info:csd/1530512610263/Put/vlen=15/seqid=0, lastCe...
关于 spark 写 es 的问题?
by
魏超
https://hainiubl.com/topics/733?
2018-07-04
⋅
3212
⋅
0
⋅
1
我找了网上及es的官网都没有关于spark写es的字段级更新,都是行更新 ,请问各位大佬有什么方法吗,非常感谢!
hbase scala 在已经存在的表中添加列簇,保证以往数据正常的情况下,添加新的列簇?
by
小鱼a
https://hainiubl.com/topics/734?
2018-07-06
⋅
3591
⋅
0
⋅
3
以下代码不能实现我的需求,删除了我以往的所有列簇包括数据,然后添加新的。
只需要添加新的列簇,以往数据保证不动。青牛老师,救急求方案 T T
// 得到hbase的连接,主要是和zk发起连接请求
val connection = ConnectionFactory.createConnection(hbaseCo...
如何计算大数据平台系统需要的服务器数量,集群节点数及存储容量等硬件设备参数?
by
 小鱼
小鱼
https://hainiubl.com/topics/735?
2018-07-09
⋅
5757
⋅
0
⋅
1
如何计算大数据平台系统需要的服务器数量,集群节点数及存储容量等硬件设备参数?
请问 flume client 是一定要有的角色吗?
by
ling775000
https://hainiubl.com/topics/738?
2018-07-11
⋅
3558
⋅
0
⋅
1
我直接外部数据直接对接flume的agent,不走flume client可以吗?
海牛大数据 java 基础 第 11 讲.java 程序执行流程 疑问?
by
脆皮
https://hainiubl.com/topics/746?
2018-07-17
⋅
4315
⋅
1
⋅
2
视频17分20秒处 为程序执行流程排序 编号8开始是不是 有问题呀
8g 内存配置 hadoop+hive 够用吗?搭建的时候需要注意哪些问题?
by
小鱼
https://hainiubl.com/topics/747?
2018-07-17
⋅
4671
⋅
0
⋅
2
8g内存配置hadoop+hive够用吗?搭建的时候需要注意哪些问题?
主机 Master 的空间问题?请大神解决
by
好好学习
https://hainiubl.com/topics/749?
2018-07-17
⋅
3682
⋅
0
⋅
4
问题描述:一共三台虚拟机,主机启动hadoop集群时提示空间已满,无法启动主机,只能启动两台从机,如何清理主机的空间或者给主机扩容呢?主机的空间跟打开前设置的内存大小有关系吗?

storm 的 spout 分发数据失败?
by
 韦晓阳
韦晓阳
https://hainiubl.com/topics/750?
2018-07-18
⋅
3322
⋅
0
⋅
1
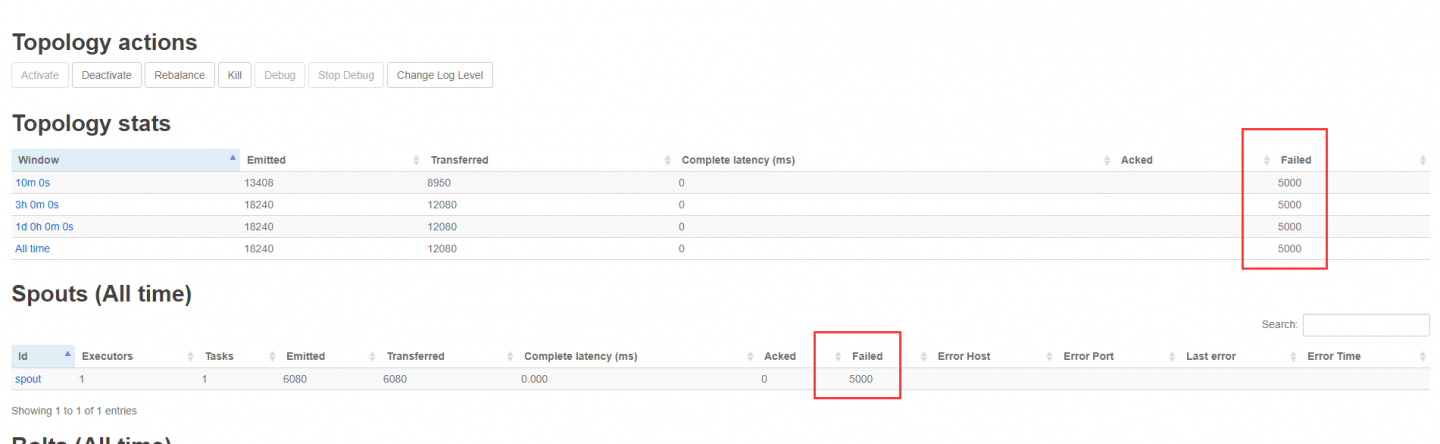
之前怀疑是业务逻辑问题,后来把业务逻辑全部注释了,没问题任何的逻辑,但还是分发失败。集群配置zk、topic、zkRoot都检查了,没问题。本地模式运行日志也没有抱任何错,,,,是第一层sp...
关于 HTML?
by
 陌上花开
陌上花开
https://hainiubl.com/topics/752?
2018-07-23
⋅
3160
⋅
0
⋅
1
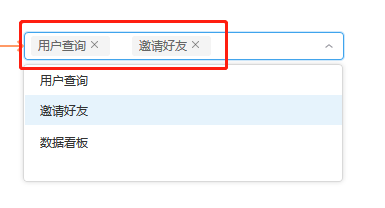
如图,这样的多选框怎么实现?
spark-sql 操作 hive 遇到的坑?
by
好好学习
https://hainiubl.com/topics/753?
2018-07-23
⋅
5348
⋅
0
⋅
2
问题描述:spark-sql操作hive-----启动spark-sql时创建表student没问题,hive可以showtables显示student表,但执行load data inpath "hdfs://master:9000/person.txt" into table student;时提示FAILED: SemanticException [Error 10028]: Line 1:17 Path is not legal...
python,用 requests 库和正则表达式爬取猫眼电影 Top100,运行结果居然是一对中括号 【 】?
by
 正在探索的小白瑶
正在探索的小白瑶
https://hainiubl.com/topics/769?
2018-07-25
⋅
3809
⋅
0
⋅
6
如图,本人今年才开始接触python,请各位大佬帮帮忙,我这个女生头发都要掉完了,因为这个问题食不下咽,哎,拜托各位大佬了!!!!
运行结果是一对中括号,可是我觉得自己的正则表达式没有写错啊。。。。好无语啊!!!要疯了
```
import requests
from reque...
大数据 spark,hadoop 和虚拟化技术 cloudstack,openstack 哪一个更有发展前景?
by
小鱼
https://hainiubl.com/topics/776?
2018-07-26
⋅
4705
⋅
0
⋅
1
hadoop已经发现比较久,我是一个初学者,我现在纠结应该走哪一个方向,我想从OpenStack,spark选一个,请高手指点。如果高手有其他观点,请指教。
spark 可以批量处理 shp 类型文件么?该如何操作?
by
小鱼
https://hainiubl.com/topics/777?
2018-07-26
⋅
4506
⋅
0
⋅
1
spark可以批量处理shp类型文件么?该如何操作?
StreamID 在集群上不识别?
by
韦晓阳
https://hainiubl.com/topics/803?
2018-07-31
⋅
3538
⋅
0
⋅
0
一个bolt根据业务需求,需要多个 collector.emit("min",new Values(valuet.toString())); min是StreamID,在本地模式下运行正常,但是进群模式不识别这个StreamID?
Cloudera 配置 HA,配置 Yarn?
by
物联网小小行
https://hainiubl.com/topics/822?
2018-08-02
⋅
3427
⋅
0
⋅
2
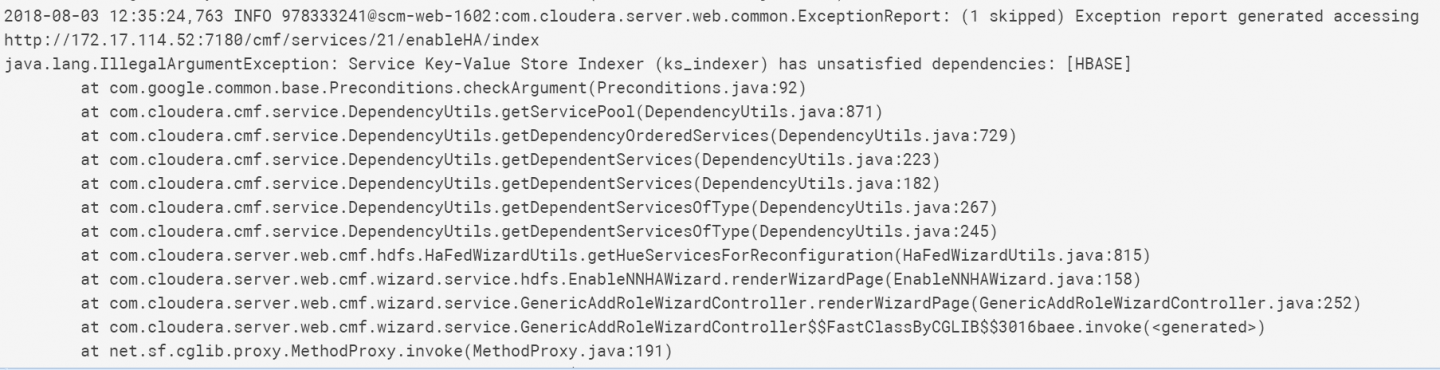
刚搭建好集群,打算配置HA报了这个错误
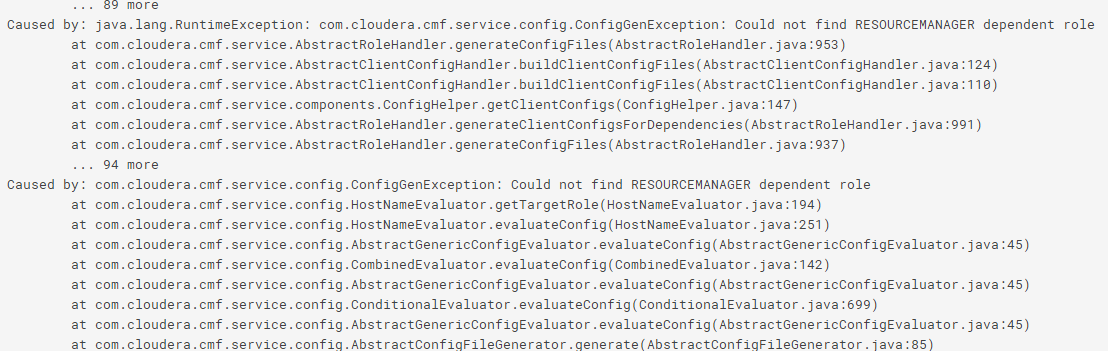
另外Cloudera如何配置Yarn?
hdfs 块的问题?
by
物联网小小行
https://hainiubl.com/topics/823?
2018-08-03
⋅
4875
⋅
0
⋅
1
我建立三个DataNode节点,然后上传几个文件后报了这个错误,我默认副本数是3份.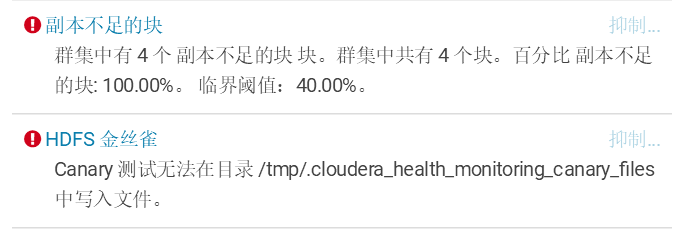
重启namenode后报这个错误Canary 测试无法在目录 /tmp/.cloudera_health_monitoring_canary_files 中写入文件
hive 执行命令问题?
by
物联网小小行
https://hainiubl.com/topics/842?
2018-08-08
⋅
3562
⋅
0
⋅
2
我执行select count(*) from table1;
然后就报这个错误了:

hive是在cloudera集群上的
IDEA 导入 spark 源码阅读 出错 ?
by
 赵三岁
赵三岁
https://hainiubl.com/topics/843?
2018-08-09
⋅
4105
⋅
0
⋅
3
用idea 导入 spark2.02 的源码 sbt 一直不动 急死我了 刚结束spark 菜鸟一个 请大神指导一下 是我哪里配置错了

;
为什么输出却是
_吗
TensorFlow 和 spark 的 ml 以及 python 的 scikit-learn 三者的区别是什么?
by
小鱼
https://hainiubl.com/topics/873?
2018-08-24
⋅
6334
⋅
0
⋅
1
TensorFlow和spark的ml以及python的机器学习库scikit-learn 三者的区别与联系是什么?
为什么TensorFlow 是机器学习框架,而后面两个习惯被人称为机器学习库?
spark count () 统计数据条数为什么每次运行结果都不同?
by
 水墨之风
水墨之风
https://hainiubl.com/topics/874?
2018-08-25
⋅
8481
⋅
0
⋅
2
**使用count统计条数时每次都不一样,而且与真实数据条数对不上,感觉有数据丢失,不知道为什么?**
```
val spa1=MongoSpark.load(ss, ReadConfig(Map("collection" -> “”), Some(ReadConfig(ss))))
val spa2=spa1.select("hyid", "phone", "name", "regtime", "use...