关于 “” 的搜索结果, 共 2412 条
高速决策:大数据被遗落的第三个 “V”
by
 爱生活爱海牛部落
爱生活爱海牛部落
https://hainiubl.com/topics/577?
2018-05-03
⋅
3100
⋅
0
⋅
0
“如果你擅长纠正错误,那么错误的代价可能会比你想象的要低,而慢的代价肯定会很昂贵。” ——杰夫·贝佐斯 亚马逊董事会主席兼CEO
速度 被遗落的第三个V
当我们谈大数据的时候,我们究竟在谈什么?
可能是许多企业正在奋力实现自动化管理的数十亿行数据;也可能是不...
STANCE SOCKS:从加州仓库到明星脚下 一双袜子的奇幻旅程
by
爱生活爱海牛部落
https://hainiubl.com/topics/578?
2018-05-03
⋅
3384
⋅
0
⋅
0
Jeff Kearl,Stance Socks 联合创始人、董事长与CEO
Copua,Lithium,Omniture,Uber等企业的天使投资人
1998年毕业于美国杨百翰大学,市场营销专业
CEO语录
letter
“作为消费者,我们用理智购物,但由情绪驱动首次购买。”
关于STANCE SOCKS
rihanna-tulle-skirt...
数据挖掘
by
 Andy123
Andy123
https://hainiubl.com/topics/579?
2023-07-10
⋅
6308
⋅
0
⋅
0
工作地点:上海
知名大型互联网公司招聘,咨询联系人,宋经理:18186157390(微信同号,有更多招聘会在朋友圈发布,欢迎大数据大牛添加),邮箱:3393881095@qq.com,欢迎咨询!
薪资范畴:30-50万年薪,具体面议!
工作职责:
1. 负责通过算法实现,来提升业务效...
公司里一般是用什么方案和工具来监控 kafka 集群,实现报警监控及集群状态监控?
by
朱威
https://hainiubl.com/topics/580?
2018-05-04
⋅
3985
⋅
0
⋅
1
实现报警监控及集群状态监控
kafka 报 java.net.SocketTimeoutException 会是哪方面的原因?
by
朱威
https://hainiubl.com/topics/585?
2018-05-07
⋅
5166
⋅
0
⋅
4
请教各位大佬,
使用 Hive 读写 Elasticsearch 中的数据,发现读取数据报错????
by
 liwei131313
liwei131313
https://hainiubl.com/topics/587?
2018-05-07
⋅
5603
⋅
0
⋅
1
在hive创建的基于ES的外部表,发现查询外部表报错,如下所示:
hive> select * from t_push_es_khsx;
OK
Exception in thread "main" java.lang.Error: Multiple ES-Hadoop versions detected in the classpath; please use only one
jar:file:/opt/cloudera/parcel...
用黑窗口编译 JAVA 文件 初期需要用到什么软件呢?
by
 白丶痴
白丶痴
https://hainiubl.com/topics/589?
2018-05-08
⋅
3087
⋅
1
⋅
5
用黑窗口编译JAVA文件 初期需要用到什么软件呢?
关于海牛部落的 QQ 群我可以加入吗? 新人请教!
by
白丶痴
https://hainiubl.com/topics/590?
2018-05-08
⋅
2905
⋅
1
⋅
2
网页右面的QQ群 咱们不是培训班的可以加入吗? (比如:我本人在自学 准备毕业后转学Java 跟进大数据专业入行 所以我想先自我了解自己适不适合这个行业 有些基础问题不好意思一个个提出想通过讨论组之类的团体提出解决 像我这种 我们海牛部落有专门的QQ 微信群吗?)...
请问 BI 开发工程师是做什么的?
by
 ling775000
ling775000
https://hainiubl.com/topics/591?
2018-05-08
⋅
4112
⋅
0
⋅
4
他和ETL工程师做的一样吗?
您好 可以分享一个 jdk 程序安装包吗?
by
白丶痴
https://hainiubl.com/topics/592?
2018-05-08
⋅
3107
⋅
1
⋅
2
您好 可以分享一个jdk程序安装包吗
数据量在亿级以上,hbase 与 MongoDB 的选择?
by
 小鱼
小鱼
https://hainiubl.com/topics/594?
2018-05-10
⋅
5139
⋅
0
⋅
1
数据类型:数据的内容主要是一些记录数据(结构化的)、图片数据、影像数据、特殊文件格式,文本数据(json),这些数据都需要包括。
应用场景:主要是一些简单的查询和统计。这些数据很多都是C端用户数据,读的频率相对会高一些。
项目中使用 sparksql 调用 hive 报错?
by
 魏超
魏超
https://hainiubl.com/topics/595?
2018-05-10
⋅
3488
⋅
0
⋅
3
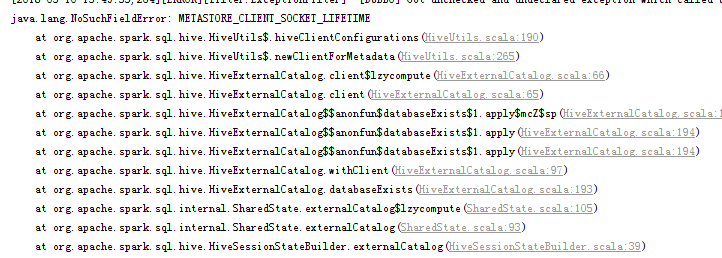
麻烦问一下各位大神,我在项目中sparksql调用hive时发生这个错误是怎么回事,而且单独写的main函数里正常通过!
spark phoenix 读取 hbase 数据量非常大的情况下怎么处理?
by
 陌上花开
陌上花开
https://hainiubl.com/topics/596?
2018-05-11
⋅
5128
⋅
0
⋅
3
val user = sqlContext.load(
"org.apache.phoenix.spark",
Map("table" -> "user", "zkUrl" -> "192.168.159.129:2181")
).rdd.map(x => {
val userName = x.getAs("userName").toString
val gender = x.getAs("gender").toString
(...
《2018 中国企业服务生态发展报告》发布企业服务迎来五个新现象
by
爱生活爱海牛部落
https://hainiubl.com/topics/598?
2018-05-11
⋅
3173
⋅
0
⋅
0
昨天下午,2018年“中国软件生态大会暨第十一届中国软件渠道大会(天津站)”在喜来登大酒店举办。数据观作为起步于天津的国产自主新一代商业分析平台,有幸受邀参加。会上,主办方发布了《2018中国企业服务生态发展研究报告》,特记录如下,与君共享。
《2018中国企...
2018年 真正的 “客户体验” 分析指南
by
爱生活爱海牛部落
https://hainiubl.com/topics/599?
2018-05-14
⋅
2831
⋅
0
⋅
0
[摘要]:
哲学家说,生存即体验。我们的生活就是由一个个或好或坏的体验组成,体验的舞台由各种品牌搭建,谁的声光色让我们高潮,我们就买谁。“以客户为中心”的时代,“客户体验”是一个太过迷人的概念。
那么,2018年CX(客户体验的英文缩写,下文均以CX代指)的最...
flume spooldir 处理大量文件报错如何解决?
by
小鱼
https://hainiubl.com/topics/600?
2018-05-15
⋅
3775
⋅
0
⋅
1
我 flume 用spooldir source监控目录抽取文件,随便建一个监控目录用作测试完全没问题,但实际启动时,要抽取文件的目录里已经存在10万多个小文件,总大小100多个G,这些文件个数还会源源不断的扩大,才启动就报错GC overhead limit exceeded;
于是我在网上各种查资...
喝过 COSTA,打过 CS,却不知道它们成功的企管秘诀?
by
爱生活爱海牛部落
https://hainiubl.com/topics/601?
2018-05-15
⋅
3050
⋅
0
⋅
0
麦肯锡一篇文章警示说:今天对于企业来说已经不是信息时代,而是敏捷时代;稀缺资源不再是信息,而是注意力。尤其对于决策层来说,注意力的碎片化,导致即使你的数据无可挑剔,决策也有可能延迟,甚至失误!幸运的是,《半条命》、《cs》缔造者Valve、英国最大制药公...
关于 sparkstreaming 实时日志去重,怎么实现俩个 Dstream 去重?
by
小鱼
https://hainiubl.com/topics/603?
2018-05-16
⋅
6246
⋅
0
⋅
1
现在是基于spark streaming 窗口的操作,10s 第一个批次传入数据
zhu01,bei01,20180516144035
zhu02,bei02,20180516144130
zhu03,bei03,20180516144235
20s 第二个批次
zhu01,bei01,20180516144035
zhu04,bei04,20180516144240
zhu05,bei05,201805...
采集服务 C# 怎么往 kafka 里面扔数据,有案例吗?
by
 韦晓阳
韦晓阳
https://hainiubl.com/topics/605?
2018-05-17
⋅
3408
⋅
0
⋅
2
采集服务C#怎么往kafka里面扔数据,有案例吗
数据分析告诉你超市货物摆放暗藏的商机
by
爱生活爱海牛部落
https://hainiubl.com/topics/606?
2018-05-17
⋅
3414
⋅
0
⋅
0
超市货物的摆放是一门很深的学问,要在运用人体工程学的基础上,考虑货架的上中下位置,考虑人的走向和视线,产品与货架如何有机结合,产品与产品如何组合摆放等等。但验证成效的方法却非常简单,只要通过实际销售业绩的变化进行检测。
通过可视化分析,可以发现这些...
数据驱动成本控制——农民工的土豪出行
by
爱生活爱海牛部落
https://hainiubl.com/topics/609?
2018-05-18
⋅
3318
⋅
0
⋅
0
本案例中,某软件公司的公司文化一直以“高科技农民工 ”为自豪,尚俭戒奢,但是在机票数据分析中,却发现飞机出行十分“土豪”,深入分析原因后,改进了管理措施,从而降低公司整体飞机出行成本16%。该分析涉及的关键数据包括1370张机票的价格、订票张数、起飞日期、一天...
Hbase 如何用 javaAPI 列出列族及字段名?
by
魏超
https://hainiubl.com/topics/610?
2018-05-21
⋅
4588
⋅
0
⋅
8
如题 麻烦了,各位大神我看tableDescriptor.getColumnFamilies()是列族名 没有对应的列名。
提问关于 5 分钟数据存储的问题?
by
 ruiqi
ruiqi
https://hainiubl.com/topics/611?
2018-05-21
⋅
3501
⋅
0
⋅
6
想问下。我们现在有个需求。是处理5分钟的计算程序,在java中实现,现在发现设计方案是放在map中,但是5分钟的数据量 都有好几十G 基本上维持在60G,这样的话我们程序配置的是128的内存老年代直接拿去70G剩下的在执行其他的成程序操作内存就不够用了。想请问下这个大家有...
后台程序如何调用 hive?
by
BigTester
https://hainiubl.com/topics/612?
2018-05-21
⋅
3301
⋅
0
⋅
5
实际开发中java代码是直接连接hive还是连接mysql,数据通过sqoop与hive同步?
Llama 角色存在,但没有设置 YARN 依赖关系?
by
BigTester
https://hainiubl.com/topics/613?
2018-05-21
⋅
5467
⋅
0
⋅
2
Impala: YARN Service for Resource Management
Llama 角色存在,但没有设置 YARN 依赖关系。Llama 角色在没有 YARN 依赖关系的情况下,无法启动。
Impala: Llama has been removed from CDH 5.10 and higher versions. Use the Disable YARN and Impala Integrate...
高效办公时,Excel 难以做到的,而数据观可以做到的事
by
爱生活爱海牛部落
https://hainiubl.com/topics/614?
2018-05-21
⋅
3423
⋅
0
⋅
0
在处理数据和分析数据方面,Excel往往是人们的首选。虽然Excel很强大,但是在某些方面,它也有些力所不能,
面我们就来看下,在高效办公时,那些Excel难以做到,而数据观可以为之补充的地方。
Excel难以快速处理百万行级别数据
当您Excel表中的数据达到百万行级...
求问 CoGroupRDD 求 dependencies 原理是什么?
by
小鱼
https://hainiubl.com/topics/615?
2018-05-23
⋅
3454
⋅
0
⋅
1
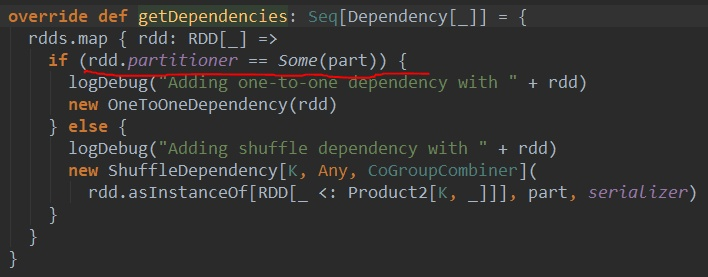
求问CoGroupRDD求dependencies的方法中:为什么当父rdd的partitioner与此rdd的partitioner一样就是窄依赖?
通过 HIVE 往 Elasticsearch 的外部表插入数据报错???
by
liwei131313
https://hainiubl.com/topics/616?
2018-05-23
⋅
7590
⋅
0
⋅
1
Error: java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata.HiveException: Hive Runtime Error while processing row {"khh":"350000011120","jyl":0,"rjzzc":0,"zcjlr":0,"yk":0}
at org.apache.hadoop.hive.ql.exec.mr.ExecMapper.map(ExecMapper.ja...
“大数据” 到底是信仰还是迷信?
by
爱生活爱海牛部落
https://hainiubl.com/topics/618?
2018-05-23
⋅
3258
⋅
0
⋅
0
大数据会告诉你下一步发生的事情——这本身就是一句谎言。
每天都有各种各样关于“大数据”的神话诞生。把层出不穷的融资新闻做个词云,“平台”、“共享”、“智能”等关键词一定字号最大、位置最中。然而,大数据并非“包治百病”,与其毫无戒心地迷信,不如重新思考以下五个...