关于 “” 的搜索结果, 共 2412 条
为啥我的 sparksql 加了 where 不管用呢?
by
 魏超
魏超
https://hainiubl.com/topics/619?
2018-05-23
⋅
3325
⋅
0
⋅
2
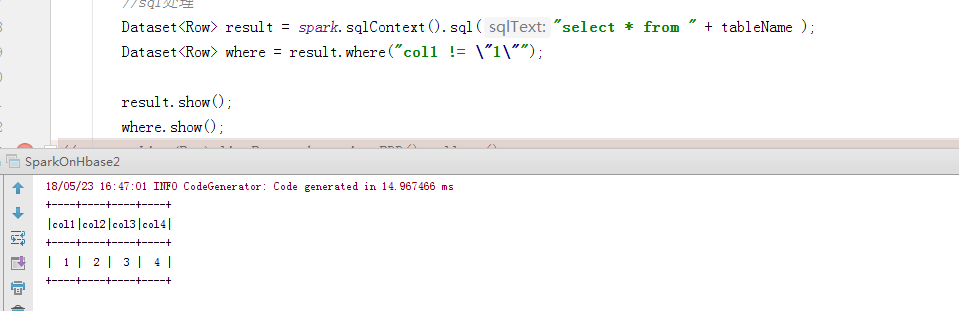麻烦问一下大神们,为什么 我加了where和未加的结果是一样的呢
Impala 需要与 Kudu 表结合使用吗?
by
 BigTester
BigTester
https://hainiubl.com/topics/624?
2018-05-24
⋅
4476
⋅
0
⋅
1
Kudu表有什么用?
Impala与Kudu表结合使用有什么好处?
storm 可不可以实时处理时间段的数据?
by
 韦晓阳
韦晓阳
https://hainiubl.com/topics/625?
2018-05-24
⋅
3382
⋅
0
⋅
6
storm可不可以实时处理时间段的数据?比如实时处理三分钟内的数据,我想到的是把这三分钟的数据缓存起来,处理好了再释放资源,这个缓存是怎么做的?有没有更好的办法
关于 hbase 的 scan 的问题?
by
魏超
https://hainiubl.com/topics/627?
2018-05-25
⋅
3951
⋅
0
⋅
4
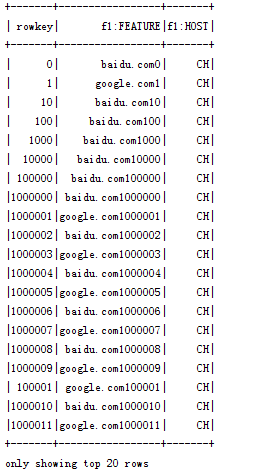
我用的hbase的scan的setstoprow方法,我想要的是rowkey<100012的结果 这完全不对是怎么回事,这个数据是自己造的。
互联网 + 便利店,零售业的新时代
by
 爱生活爱海牛部落
爱生活爱海牛部落
https://hainiubl.com/topics/628?
2018-05-25
⋅
3114
⋅
0
⋅
0
如今,市场环境日趋复杂,零售行业态势整体走低,在大数据的影响下,机遇与挑战并存。本文阐述零售行业现状,并从便利店着手分析现有问题,提供数据层面的解决方案。
2017年,在零售行业整体走低的情势下,便利店作为其中最有掘金潜力的分支,将有一大批资本涌入...
从万物互联到万数互联你做好准备了吗?
by
爱生活爱海牛部落
https://hainiubl.com/topics/629?
2018-05-28
⋅
3160
⋅
0
⋅
0
[一句话简介]:
2018年最时髦的技术,都跟LiánJi有关。一个是5G大连接,还有一个,就是区块链。一旦我们开始让万物互联,我们就无法忍受它们重新彼此孤立。一旦我们感受过什么叫做完整,我们就无法忍受彼此分离。
[开篇]:
从发明了德国活版印刷的古滕堡...
有 R 开发 storm 和 spark 的案例或者资料吗?
by
韦晓阳
https://hainiubl.com/topics/630?
2018-05-29
⋅
3200
⋅
0
⋅
2
有R开发storm和spark的案例或者资料吗?
HBase 数据为何在一台机器上?
by
魏超
https://hainiubl.com/topics/631?
2018-05-29
⋅
3373
⋅
1
⋅
1
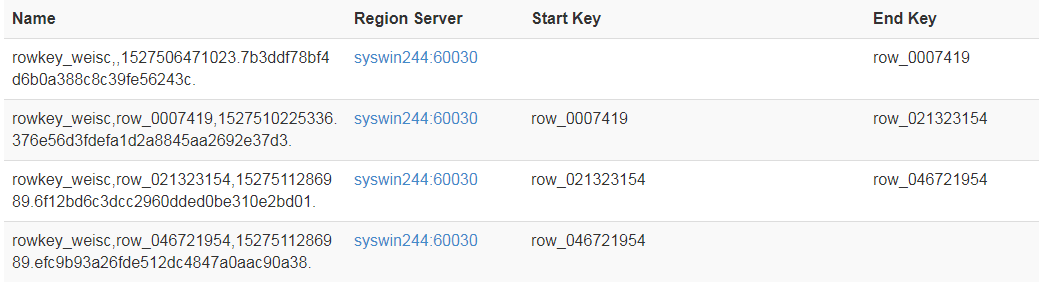
为何我的这个表的分为四个region 都在一台机器上,这个集群一共三台
本地 Java 程序提交任务到 spark 集群无法执行,也没有报错,这是为什么?
by
 tonly
tonly
https://hainiubl.com/topics/632?
2018-05-29
⋅
8044
⋅
0
⋅
16
本地连接虚拟机上的spark集群,一直出现这样的日志,好像一直在不停的分配重试task,然后又回收任务,就是不执行任务,也没有错误信息,请大牛帮忙解答一下,谢谢!
spark版本是2.3的,集群没有问题,在集群上执行Spark Pi测试都是正常的。
代码
。考虑到用redis,redis的list列表和有序集合存储形式都是有序的,但是不能两个或三个字段联合查询。hbase和hive可以实现,但是实时性有所欠缺,,,,所有很头痛,不知道有没有什么好的建议
“平台崩坏” 时代(三)来自管理学的商业建议
by
爱生活爱海牛部落
https://hainiubl.com/topics/643?
2018-06-04
⋅
3401
⋅
0
⋅
0
作者:Martin Reeves, Simon Levin, Kevin Whitaker
管理学版《商业启示录》
先发制人的创新对现有企业来说是一项挑战:短期投资者的压力会阻碍投资,过去的成功往往也会巩固当前的商业模式。但一些公司已设法不让自己陷入困境:大约10%的大型企业仍以两位数的速...
因 “数” 利导 让营销成功的 5 个关键原则
by
爱生活爱海牛部落
https://hainiubl.com/topics/646?
2018-06-06
⋅
3200
⋅
0
⋅
0
自从阿基米德发现了杠杆原理,人们就一直在追寻各种领域的“杠杆”,试图用“小输入”,创造“大输出”。在营销领域,当然也有这样的“杠杆”,那就是数据。不过,并不是每种分析方式都能创造大价值。
过去,人们利用马上、枕上、厕上这三大碎片化时间来创造文章;现在,车...
有 R 写 storm 拓扑的案例吗?
by
韦晓阳
https://hainiubl.com/topics/647?
2018-06-06
⋅
3145
⋅
0
⋅
2
有R写storm拓扑的案例吗?
JOELSPOLSKY:当 “码农” 成为 CEO
by
爱生活爱海牛部落
https://hainiubl.com/topics/649?
2018-06-07
⋅
3349
⋅
1
⋅
0
JOELSPOLSKY:当“码农”成为CEO
Joel Spolsky,世界闻名的软件开发流程专家, IT技术问答网站“Stack
Overflow”的联合创始人。还可能是世界上首个且最成功的“网红技术博主”,其博客“Joel谈软件”被译成30多种语言并结集出书。在知乎上,经常有人讨论“如何优雅地使用S...
请问 Linux 里全选的快捷键是什么呢?
by
 ling775000
ling775000
https://hainiubl.com/topics/651?
2018-06-08
⋅
5436
⋅
0
⋅
3
网上看了下,是按Esc 然后 dG,这个dG是什么意思? vi进去的文本全选快捷键是?
java Web 页面数据导出 excle?
by
 陌上花开
陌上花开
https://hainiubl.com/topics/652?
2018-06-09
⋅
3814
⋅
0
⋅
2
页面:
<div class="form-input col-md-1">
<a href="javascript:download();" class="btn large primary-bg radius-all-4" id="download"
name="search" title="下载">
<span class="button-content"...
oracle日志数据采用什么技术处理?
by
 迪乔
迪乔
https://hainiubl.com/topics/653?
2018-06-09
⋅
2876
⋅
0
⋅
1
现状:应用是负责订单流程管理,同时还要将一些数据实时同步给外围系统,同时需要提供查询和统计报表的功能,这些模块在一起会影响订单的流转,数据库Oracle压力较大。
需求:现在想要将数据同步和查询报表的功能单独作为一个应用,数据采集通过OGG+KAFKA,然后应用读...
关于 storm 用 IDEA 打包遇到的编译问题?请大神解决
by
好好学习
https://hainiubl.com/topics/654?
2018-06-09
⋅
3682
⋅
0
⋅
1
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.1:compile (default-compile) on project stormwordcount: Compilation failure
[ERROR] No compiler is provided in this environment. Perhaps you are running on a JRE rather t...
Spark 可用异构编程系统哪些更适用?
by
 小鱼
小鱼
https://hainiubl.com/topics/655?
2018-06-11
⋅
3331
⋅
0
⋅
1
适用于spark的异构编程系统,如SparkCL,或者本人所使用的Aparapi等
关于 JS?
by
陌上花开
https://hainiubl.com/topics/657?
2018-06-11
⋅
3103
⋅
0
⋅
1
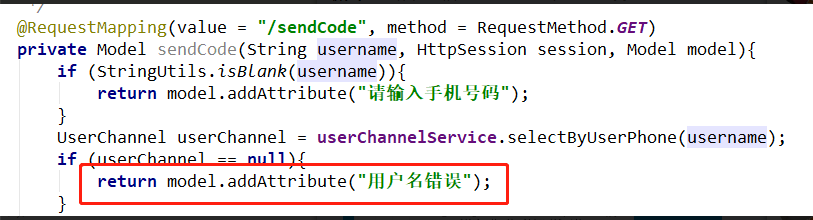
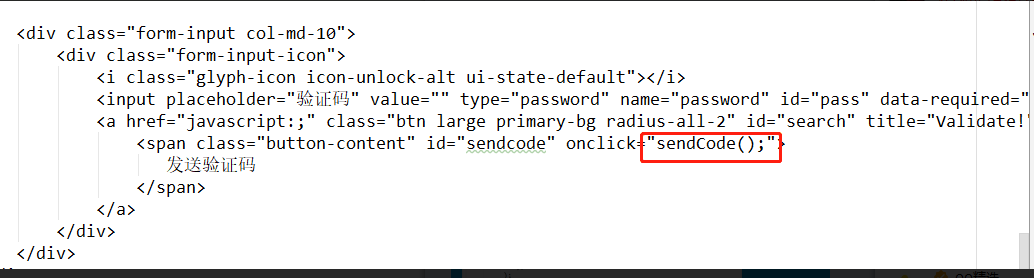

后台验证的数据信息,怎么在...
从 “砌墙” 到敲代码,看土木工程专业如何转型大数据开发
by
 海牛龙龙
海牛龙龙
https://hainiubl.com/topics/658?
2018-06-12
⋅
6107
⋅
1
⋅
2
土木工程听起来是多么的高大上,梦想着自己将来会成为一名工程师,能够指点江山。但理想很丰满,现实很骨感。毕业后拿着一张含金量并不高的大专毕业证进入到了土木工程领域,可以想象,我每天就是在“砌墙”与“搬砖”之间徘徊,所以不管别人想法如何,我决定换一种活法。...
关于匿名内部类的问题?
by
 豆豆
豆豆
https://hainiubl.com/topics/659?
2018-06-12
⋅
2944
⋅
0
⋅
2
你好,我看了花牛老师的java基础,在112节课匿名内部类中,我这样写运行后没有结果,是因为在匿名内部类中不接受返回值吗?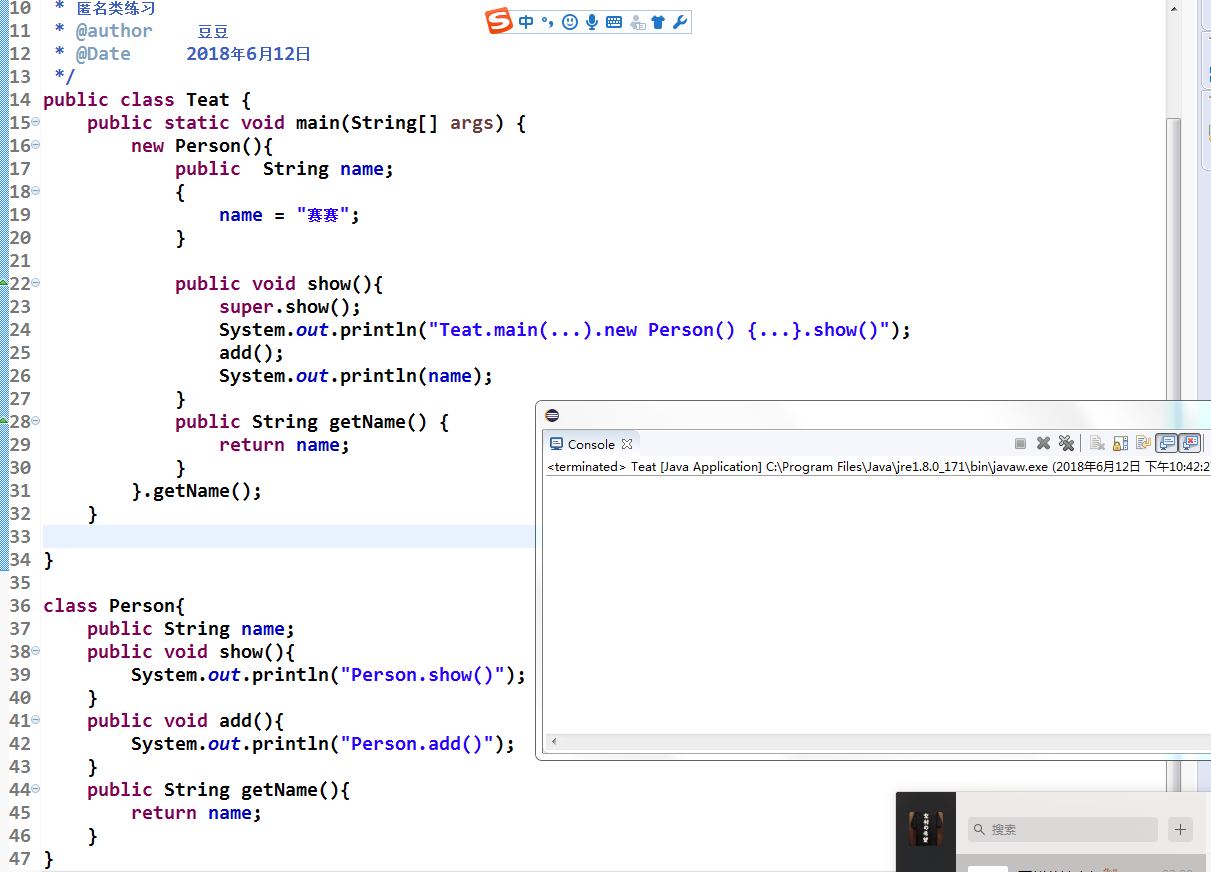
关于 HTML 页面菜单栏根据权限隐藏?
by
陌上花开
https://hainiubl.com/topics/660?
2018-06-13
⋅
3970
⋅
0
⋅
5
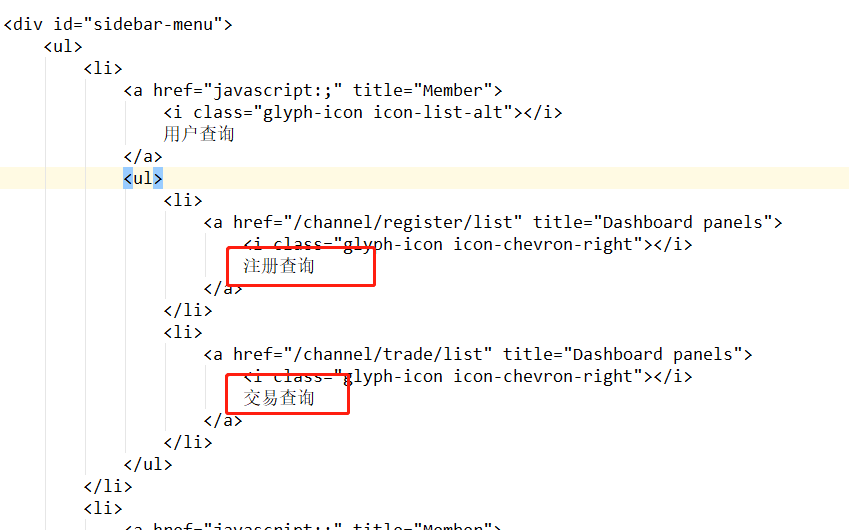
如何根据不同的权限,展示不同的菜单?
Python 的 map 和 reduce 和 Hadoop 的 MapReduce 有什么关系?
by
小鱼
https://hainiubl.com/topics/661?
2018-06-15
⋅
3768
⋅
0
⋅
1
Python 的 map 和 reduce 和 Hadoop 的 MapReduce 有什么关系?
Spark 比 Hadoop 的优势有这么大吗?
by
小鱼
https://hainiubl.com/topics/662?
2018-06-15
⋅
3540
⋅
0
⋅
1
刚接触Spark,论文中提到内存计算。但是经常用到的Shuffle过程仍然把中间数据放到硬盘中。实际在测试中,利用Shark(Spark on Hive)比Hive真没提高多少效率(没有经过很多优化)。现在持有Spark取代Hadoop观点的人越来越多了,Spark的确有这么光明吗?
做大数据必须掌握 R 或者 pyhon 吗?
by
小鱼
https://hainiubl.com/topics/663?
2018-06-15
⋅
4276
⋅
0
⋅
1
感觉pyhon用的更多一些,R语言次之,还有各种各样新出来的语言,当然,我用的还是R,觉得和pyhon也是相通的。
Spark 的 mllib 机器学习包推荐算法如何用 Python 在 Spark 上实现?
by
小鱼
https://hainiubl.com/topics/664?
2018-06-15
⋅
4610
⋅
0
⋅
1
最近有需求,需要使用python在Spark平台上重新实现mllib包中的协同过滤推荐算法,不知道有没有大神做过这方面的研究?直接阅读scala源码然后照着搬,还是有其他什么好的路径?