关于 “” 的搜索结果, 共 2411 条
请问一下 mvn clean package 报错怎么解决?
by
 如风
如风
https://hainiubl.com/topics/36220?
2019-03-18
⋅
4991
⋅
0
⋅
3
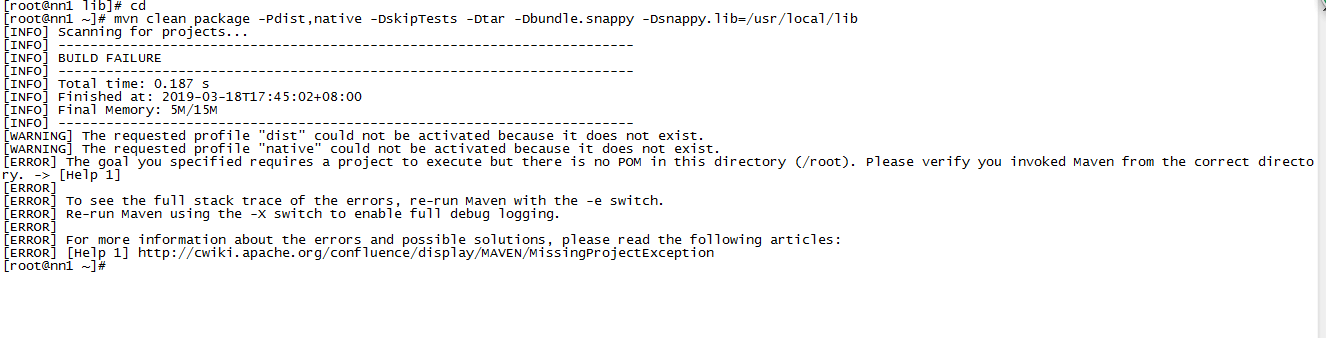
利用 CDH5.16.1 添加 hue 时提示 hue server 启动不起来?请大神解决
by
 好好学习
好好学习
https://hainiubl.com/topics/36221?
2019-03-20
⋅
4776
⋅
0
⋅
2
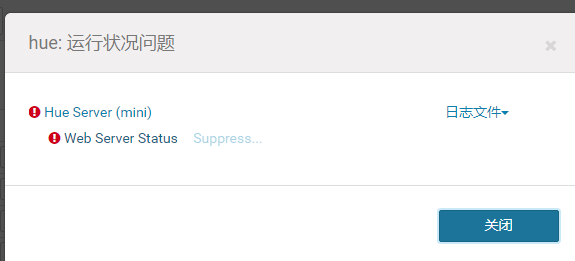
log显示
File "/www/cloudera/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3/lib/hue/build/env/lib/python2.7/s...
Notepad++ 中如何对 hadoop 文件进行修改保存?
by
如风
https://hainiubl.com/topics/36222?
2019-03-21
⋅
2938
⋅
0
⋅
1
编辑了一个权限777的文本,但每次点击保存之后,原来的文本没有变,只多了一个“???????”修改后的文件。
关于 zookeeper 在 hadoop 运用中的一个疑问?
by
如风
https://hainiubl.com/topics/36225?
2019-03-22
⋅
2776
⋅
0
⋅
1
因为zookeeper的一个作用是防止hadoop因为一个datanode挂掉而导致整个集群不能正常使用的问题,在海牛视频里面看到zookeeper集群是由nn1,nn2,s1,三个虚拟机组成的集群。而在hdfs环境搭建时,由nn1和nn2担任namenode的角色,所以有个小疑问,如果nn1的namenode节点挂...
Hadoop 默认 map 数是 2,块大小 128M,当文件 为 512M 是会有几个 map,有几个 map 并行?
by
 七里芬芳
七里芬芳
https://hainiubl.com/topics/36235?
2019-03-25
⋅
2576
⋅
0
⋅
1
Hadoop默认map数是2,块大小128M,当文件 为 512M是会有几个map,有几个map并行?
hadoop 环境搭建及开发的 jdk 版本问题?
by
七里芬芳
https://hainiubl.com/topics/36236?
2019-03-25
⋅
2493
⋅
0
⋅
1
各位大神好,我最近在自己的虚拟机上搭建hadoop环境,使用的hadoop版本是3.0alpha版本,要求jdk1.8,我在我的pc虚拟机中安装了jdk1.8。而我之前java项目开发,用的版本是1.7,这个低版本会对后续的hadoop有影响吗?
cloudera manager 的 server 提示 cloudera-scm-server dead but pid file exists?请大神解决
by
好好学习
https://hainiubl.com/topics/36237?
2019-03-25
⋅
7073
⋅
0
⋅
3
上周五CDH集群运行好好的,各个组件运行良好,今天周一早晨来之后发现挂掉了,启动cm的server一会儿后就挂掉,提示cloudera-scm-server dead but pid file exists,通过cloudera-scm-server.log日志提示:
ERROR ParcelUpdateService:com.cloudera.parcel.components...
python 怎么设置 cuda 的随机数种子 curand?
by
七里芬芳
https://hainiubl.com/topics/36238?
2019-03-26
⋅
3252
⋅
0
⋅
1
比如用tensorflow之类的深度学习库时,都会用到cuda来初始化tensor,如果不设置curand,每次运行初始化的结果都会不同,所以这里要怎么写?
hadoop streaming 中 reduce 程序如何将结果保存在一个文件中输出?
by
七里芬芳
https://hainiubl.com/topics/36239?
2019-03-26
⋅
2709
⋅
0
⋅
1
想问一下,我写了mapper程序,然后reduce"cat"这样子写,这样得到的结果分布在很多文件夹中(因为程序就是在不同的零碎文件中查找目标string出现的次数),每个文件中保存了各自文件中string出现的次数,但是我的目标是把所有文件中string出现的次数相加放到一个文件输...
Hadoop 下 reduce 处理量最大是 1G 如果 order by 全局排序的文件超过 1G,系统如何处理?
by
七里芬芳
https://hainiubl.com/topics/36240?
2019-03-26
⋅
3071
⋅
0
⋅
1
Hadoop下reduce处理量最大是1G如果order by 全局排序的文件超过1G,系统如何处理?
关系数据修改后如何刷新 Hadoop 平台数据?
by
七里芬芳
https://hainiubl.com/topics/36241?
2019-03-26
⋅
3153
⋅
0
⋅
1
大家把关系数据库海量数据增量抽到Hadoop平台是存储在哪里(比如hdfs hive HBASE等)?关系数据修改后如何刷新Hadoop平台数据的?
大的文件拆分后,怎样用 Hadoop 进行高效的处理这些小文件?以及怎样让各个节点尽可能的负载均衡?
by
七里芬芳
https://hainiubl.com/topics/36242?
2019-03-26
⋅
2662
⋅
0
⋅
1
大的文件拆分后,怎样用Hadoop进行高效的处理这些小文件?以及怎样让各个节点尽可能的负载均衡?
spark 开发词频统计应用,最后数据保存到 Hadoop 下的 data 文件里?
by
七里芬芳
https://hainiubl.com/topics/36243?
2019-03-26
⋅
2856
⋅
0
⋅
1
spark开发词频统计应用,最后数据保存到Hadoop下的data文件里,用Hadoop查看保存的data文件里面有好几个文档,数据究竟在哪个文档里
Spark 是一种内存计算引擎,为什么他还要依赖 HDFS 这种文件系统呢?
by
七里芬芳
https://hainiubl.com/topics/36244?
2019-03-27
⋅
3030
⋅
0
⋅
1
Spark是一种内存计算引擎,为什么他还要依赖HDFS这种文件系统呢?
spark 如何实现一个快速的 RDD 中所有的元素相互计算?
by
七里芬芳
https://hainiubl.com/topics/36245?
2019-03-27
⋅
3307
⋅
0
⋅
1
在spark集群中需要实现每个元素与其他元素进行计算,比如
rdd = sc.parallelize(Array('a', 'b', 'c', 'd')),
那么需要相互计算的元素对为
(a, b), (a, c), (a, d), (b, c), (b, d), (c, d)
我知道可以先进行cartesian,然后filter一下,但是对于数据量特别大的...
如何解决 Spark 大规模数据运行情况下,速度越来越慢的情况?
by
七里芬芳
https://hainiubl.com/topics/36246?
2019-03-27
⋅
4739
⋅
0
⋅
1
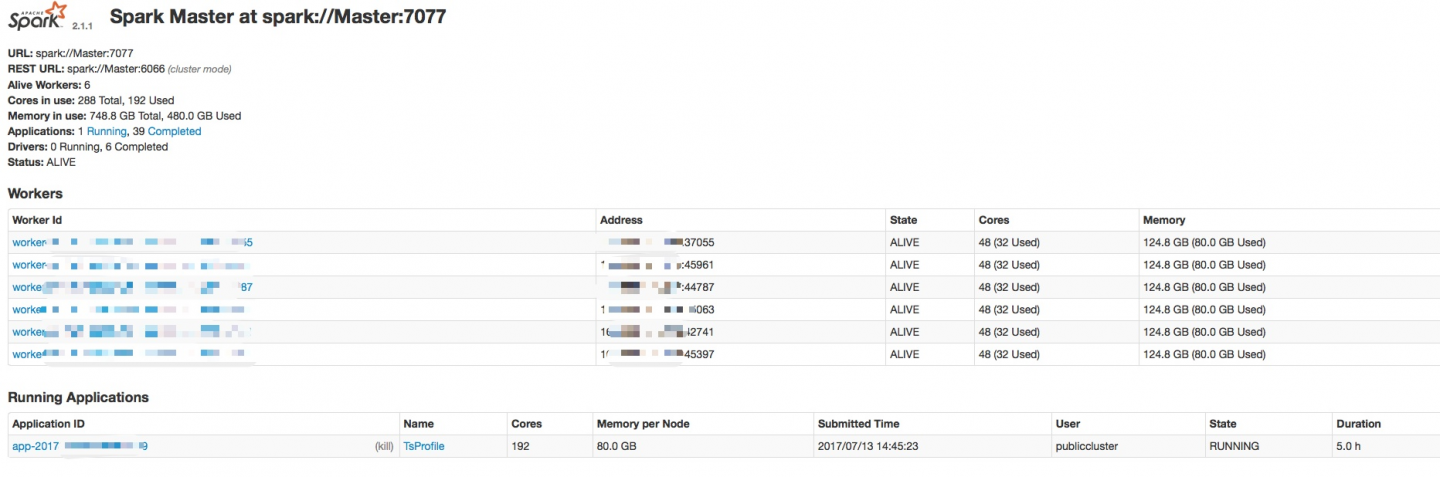
现在问题是分批利用集群处理数据:
按照理论来说,同一个任务流程,每批的处理时间应该相同,但是现在问题是,第1批是时间很快,大概5分钟能处理完,运行一段时间后,到第30多批后,运...
SparkStreaming 消费 kafka 数据,怎样解决大量初始化数据的问题?
by
七里芬芳
https://hainiubl.com/topics/36247?
2019-03-27
⋅
3064
⋅
0
⋅
1
目前遇到一个问题,SparkStreaming消费Kafka数据的时候,当有大量初始化数据,并且这些数据涉及大量任务,那么这初始化的大量任务的执行会阻塞实时从Kafka发送过来的任务(因为当前任务的执行优化的还不够快,所以当初始化发送好几万的任务的时候造成非常明显的阻塞),...
Kafka-spark-kafka-spark 架构有什么优势吗,为何两次使用 kafka?
by
七里芬芳
https://hainiubl.com/topics/36250?
2019-03-29
⋅
4872
⋅
0
⋅
1
看到一篇文章说,直接kafka到spark到mysql出现了数据重复的问题,然后在spark后再加一个kafka,解决了数据重复问题,为什么呢??
python 怎么去获取 Kafka 的 topic?
by
 刘世兴
刘世兴
https://hainiubl.com/topics/36251?
2019-03-29
⋅
5611
⋅
0
⋅
1
python2.7怎么获取Kafka的topic?
kafka 消费异常消息后后面的消息都处理不了了吗?
by
 许宁
许宁
https://hainiubl.com/topics/36252?
2019-03-29
⋅
6571
⋅
0
⋅
1
1.kafka其中一条消息异常,导致后面无法消费,这种情况怎么处理,可否像其他消息一样乱序重试,已查阅kafka无重试队列这个概念。
2.kafka消息丢失是怎么回事,acks设置为-1还会有消息丢失吗,问题点在哪里?
3.既要有大吞吐量,又要可靠性,这种情况用哪个消息队...
kafka spring 如何发送的消息,他自己管理 zookeeper 吗?
by
七里芬芳
https://hainiubl.com/topics/36253?
2019-03-29
⋅
4361
⋅
0
⋅
1
我想发送消息给kafka,现在用的是spring for kafka框架,在代码里我是用KafkaTemplate发送给kafka的,配置里写的是kafka.bootstrap-servers=192.168.130.73:9092当然可以在多加,我知道zookeeper是默认来管理kafka节点的,我现在不太明白kafkatemplate发送的时候他是自动...
kafka 的本地 Producer 如何向远程 Kafka 服务器读入数据?
by
 y514637059
y514637059
https://hainiubl.com/topics/36254?
2019-03-29
⋅
5243
⋅
0
⋅
1
producer和 kafka集群不在同一个局域网内,怎么通过这个producer向这个卡卡集群写入数据
CDH 集群环境安全问题如何解决?
by
好好学习
https://hainiubl.com/topics/36255?
2019-03-29
⋅
6128
⋅
1
⋅
1
最近公司搭建了CDH生产环境,考虑到数据安全,
1、具体应该做哪方面的工作?
2、有没有类似的文档可以提供呢?
3、启用kerberos认证会不会后面操作代码比较麻烦?
4、基于sentry的角色权限控制加入后代码操作是不是比较麻烦?
5、在CDH平台中如何设置hdfs的静态、...
有没有大佬知道,pygame 中 get_busy () 函数怎样才会返回一个 1?
by
 刘明
刘明
https://hainiubl.com/topics/36256?
2019-03-29
⋅
5499
⋅
0
⋅
1
不管我音乐有没有开始播放,这函数返回值都是0,按理来说,不应该是音乐播放过程中,返回1,音乐放完了,就返回0,这么理解不对吗?
pygame 的图片为什么加载不出来?
by
 小强飞飞飞
小强飞飞飞
https://hainiubl.com/topics/36258?
2019-03-29
⋅
5859
⋅
0
⋅
1
代码如下:
# Unit aaa: Pygame Hello Wall Ball Game version 1
import pygame, sys
pygame.init()
size = width, height = 600, 400
speed = [1, 1]
BLACK = 0, 0, 0
screen = pygame.display.set_mode(size)
pygame.d...
pygame1.9.4 往后没有 movie 模块了,怎么实现添加视频?
by
 不疯何以成佛
不疯何以成佛
https://hainiubl.com/topics/36259?
2019-03-29
⋅
4827
⋅
0
⋅
0
原来的代码可以实现,但是单位电脑安不了,64位1.9.3就没有movie模块,win32的1.9.3就有,而最新的1.9.4或1.9.5都没有,怎么解决,大神们没有在游戏里添加酷炫的视频吗,,不想转化成图片逐帧,
Python 的 for in 循环能嵌套使用?
by
 星际旅行
星际旅行
https://hainiubl.com/topics/36260?
2019-03-29
⋅
5413
⋅
0
⋅
1
Python的for in循环能嵌套使用?
Pandas 读取 Excel 中指定单元格后再取 dataFrame 怎么做?
by
 张文海
张文海
https://hainiubl.com/topics/36261?
2019-03-29
⋅
6877
⋅
0
⋅
1
如题,我想要从Excel表中先获取B2单元格的日期,再读取下面的数据。
我目前先读取一次DataFrame获取全表内容指定返回日期
然后再skiprows=5提取下面的DataFrame
有没有什么方法,先提取一次全表的DataFrame,读取日期后,再忽略掉这个DataFrame的前四行,并且...
yarn 提交任务之后一直处于 pending 状态怎么解决?
by
如风
https://hainiubl.com/topics/36263?
2019-04-02
⋅
11378
⋅
0
⋅
1
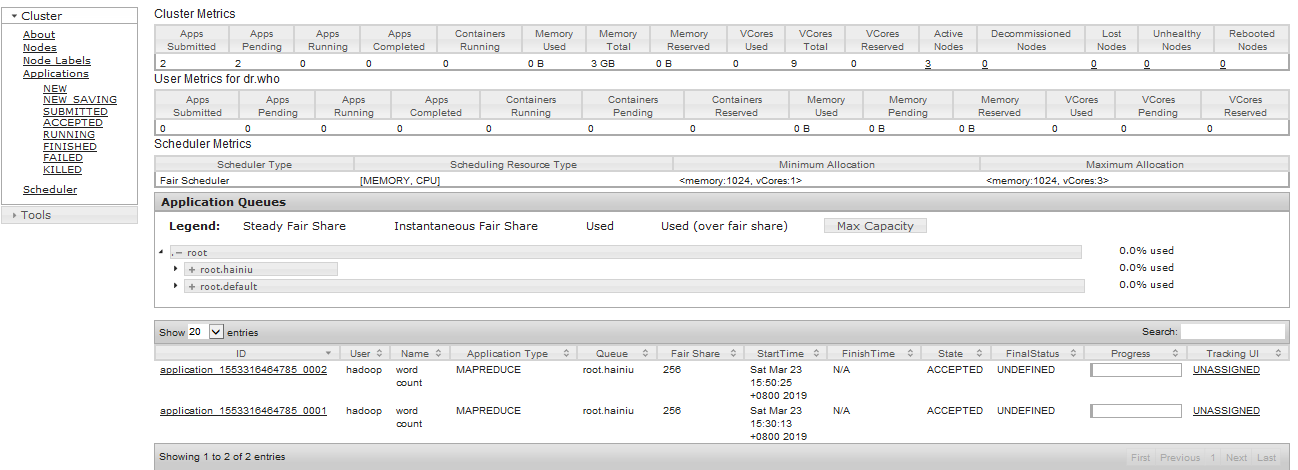

Tracking UI 处于UNASSIGNED状态
 夜雨微风
夜雨微风
https://hainiubl.com/topics/36265?
2019-04-03
⋅
5375
⋅
0
⋅
1
spring boot集成阿里云的kafka消息服务。由于阿里云的服务是使用了ssl的,所以配置kafka的时候引入了jks证书文件。在IDE中调试运行一切正常。但是当打成jar包后,无论将jks文件放到任何地方,都读取不到(报文件不存在错误)。第一次遇到这种问题,请大神不吝赐教。