关于 “” 的搜索结果, 共 2411 条
hbase 为什么要搭建集群?我不能在 hadoop 集群里做做一个 hbase 吗?
by
 卢本伟牛X
卢本伟牛X
https://hainiubl.com/topics/36073?
2019-03-07
⋅
2611
⋅
0
⋅
1
如题
请问大家有这三个脚本的压缩包吗?
by
 如风
如风
https://hainiubl.com/topics/36074?
2019-03-07
⋅
2642
⋅
0
⋅
1
 有的话可以分享一下吗
如何对基数大的海量数据进行快速聚合分析,需要啥技术?
by
卢本伟牛X
https://hainiubl.com/topics/36075?
2019-03-07
⋅
2362
⋅
0
⋅
1
mysql某张日志表有一亿多条数据,每天大概三四百万的数据增量,现在要对这张表进行数据统计。在不受限于任何方向的技术方案的情况下进行技术改造,用啥技术能最大提高分析的性能,实时性差异不能超过10分钟
hadoop(hdfs/yarn/mr)2.x 源码应该如何入手比较好?
by
 张凌天
张凌天
https://hainiubl.com/topics/36077?
2019-03-07
⋅
2735
⋅
0
⋅
1
五年运维狗,想从源码层面更了解底层,感觉要精通大数据,需要代码能力,不管是排错还是优化,甚至以后有机会做数据分析应用
spark submit 运行正常,但是 oozie 提交 spark on yarn 会报错怎么办?
by
 听说
听说
https://hainiubl.com/topics/36078?
2019-03-07
⋅
2126
⋅
0
⋅
1
报找不到一些类的方法的错,但是我的oozie的share lib更新过了,全新的spark的jar
掌握 hadoop 等大数据开发技术,但是不太懂数据挖掘算法,在找大数据工作时受限制大吗?
by
听说
https://hainiubl.com/topics/36079?
2019-03-07
⋅
2646
⋅
0
⋅
1
1 本人研二计算机专业,2020年毕业,女生。想自学hadoop,在校招之前可能没法学到数据挖掘算法,这样可以找大数据开发的职位吗?想去大公司,会不会因为我不会数据挖掘算法就不太接受我。
2 由于导师约束没法实习,应聘大数据开发工程师却没有实习的情况下,该如何准...
为什么 MapReduce 中 context.write () 有时候不执行或者没有数据?
by
 十年
十年
https://hainiubl.com/topics/36080?
2019-03-07
⋅
2653
⋅
0
⋅
1
为什么MapReduce中context.write()有时候不执行或者没有数据?
HDFS 源码阅读时,文件类的疑问?
by
十年
https://hainiubl.com/topics/36081?
2019-03-07
⋅
2690
⋅
0
⋅
2
org.apache.hadoop.fs.FileSystem
org.apache.hadoop.fs.FileContext
org.apache.hadoop.fs.AbstractFileSystem
这几个类有什么联系啊?
我看hbase貌似在使用HDFS的时候是使用FileSystem的子类,那另外2个类又说是对外暴露接口,到底是怎么对外暴露呢?
flink f DataStream 怎样做到每隔 30 秒入一次库?
by
 shishuai19910217
shishuai19910217
https://hainiubl.com/topics/36082?
2019-03-07
⋅
3510
⋅
0
⋅
1
需求 :使用flink 从kafka 实时读取数据 然后写入到es里面
想实现 每隔30秒之后 数据积累一定量之后批量写入es 应该怎么做?(不能在读取kafka源的时候加时间限制 因为我需要实时的读到数据还要做其他的操作,必须是读取之后每过30秒入一次es)
为什么只有 root 用户可以 SSH 连接,普通用户不行?
by
如风
https://hainiubl.com/topics/36083?
2019-03-08
⋅
3882
⋅
0
⋅
1
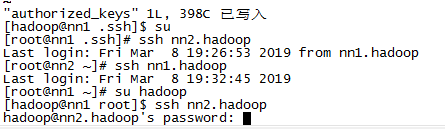
flink apply 方法中为什么不能使用 lambda?
by
shishuai19910217
https://hainiubl.com/topics/36084?
2019-03-09
⋅
5138
⋅
0
⋅
1
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//连接socket获取输入的数据
DataStreamSource<String> text = env.socketTextStream("127.0.0.1", 4700);
text.map(action->{
ret...
spark 读取 hive 的问题?
by
 魏超
魏超
https://hainiubl.com/topics/36086?
2019-03-11
⋅
2857
⋅
0
⋅
2
麻烦问一下 spark读取hive表时 是default库是可以的,读取没有问题 读取相同ip的其他库就会出现这个问题 是怎么回事 跪谢了
![Uploading file...]()
请问谁有海牛教学视频里面的 hosts_op 脚本可以分享一下吗?
by
如风
https://hainiubl.com/topics/36087?
2019-03-11
⋅
2791
⋅
0
⋅
1
spark 当中,被 cache 的 RDD 的引用是否可以存到 HashMap 里?
by
 七里芬芳
七里芬芳
https://hainiubl.com/topics/36088?
2019-03-12
⋅
2522
⋅
0
⋅
1
这是稍微简化了的一个代码片段,这个函数每次要根据 dayid 调用 getList, 本质上是去 hive 里读取对应的 partition 然后做后续计算. 但是这个函数可能在一个 job 中以相同的 dayid 被调用多次(也可能是其他 dayid). 所以为了让被 cache 的 rdd 被重复使用,我想把 dayid&r...
为什么 hadoop 的 shuffle 阶段需要对数据进行排序?
by
七里芬芳
https://hainiubl.com/topics/36089?
2019-03-12
⋅
3011
⋅
0
⋅
1
hadoop的shuffle阶段排序的作用是什么呢?
在spark中的shuffle是不需要进行排序的,同样地在hadoop中不进行排序也能对数据进行分组,如果在业务上不需要排序,那么是否可以去掉hadoop中的排序呢?
'module' object has no attribute 'open_client'怎样解决?
by
卢本伟牛X
https://hainiubl.com/topics/36091?
2019-03-12
⋅
2562
⋅
0
⋅
1
python34出现了上述提示,不知道怎么解决啊,还请大佬相助,多谢多谢!
heidisql 导入 CSV 文件后,为何数据都是 null 呢?
by
卢本伟牛X
https://hainiubl.com/topics/36092?
2019-03-12
⋅
3895
⋅
0
⋅
1
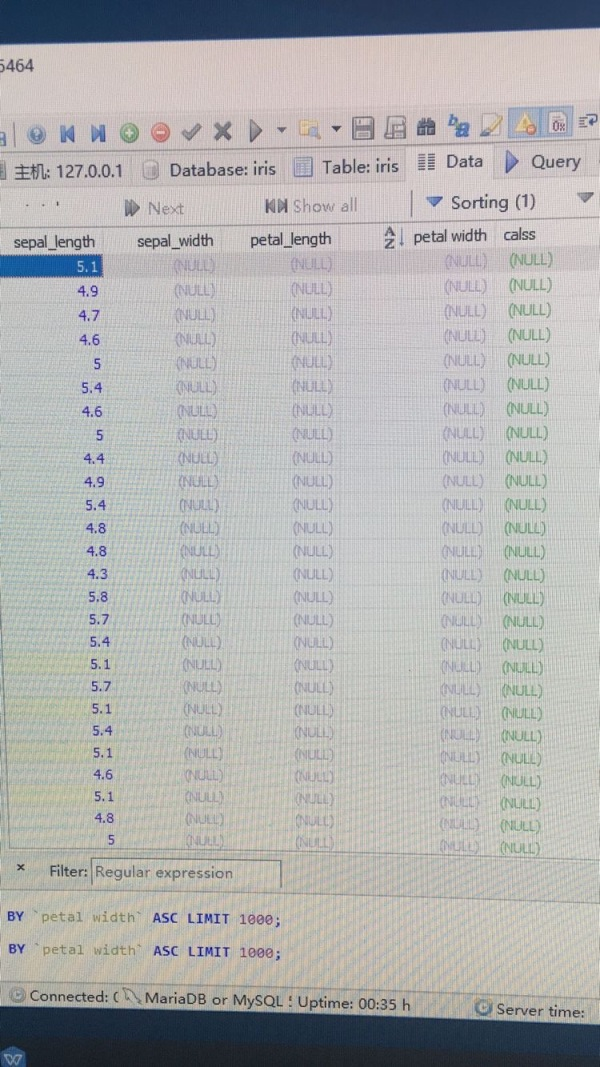
是不能用wps的Excel导入数据吗?
Fuzzy C-means 与 Gaussian Mixture Model 聚类的区别?修改
by
七里芬芳
https://hainiubl.com/topics/36093?
2019-03-13
⋅
2703
⋅
0
⋅
1
模糊C均值聚类与高斯混合模型都是对K-means算法的延伸,且两者都属于软划分,即每个样例以一定的概率(比例)属于每一类,那这两者究竟有何区别呢?或者说各自的优势在哪里?
Spark SQL 如何管理 select 权限,貌似任何用户都可以查询任何一张表?
by
七里芬芳
https://hainiubl.com/topics/36094?
2019-03-13
⋅
2417
⋅
0
⋅
1
Spark SQL如何管理select权限,貌似任何用户都可以查询任何一张表?
spark streaming 任务如何切分,是按照 duration 切分么?
by
七里芬芳
https://hainiubl.com/topics/36095?
2019-03-13
⋅
2493
⋅
0
⋅
1
spark streaming任务如何切分,是按照duration切分么?
Spark 中的 CNN 如何实现分布式计算的?
by
七里芬芳
https://hainiubl.com/topics/36096?
2019-03-13
⋅
3374
⋅
0
⋅
1
之前有在caffe上做过点CNN,现由于项目需要,想用spark库中的CNN(据说已支持),但有个疑问。之前研究CNN的时候因为神经网络各层之间互联感觉不可能在分布式计算平台实现,所以想问Spark上是怎么实现对这些神经网络算法的分布式计算的呢?O(∩_∩)O谢谢
spark 中 mllib 是如何将某些机器算法做到分布式并行计算的?
by
七里芬芳
https://hainiubl.com/topics/36098?
2019-03-14
⋅
3024
⋅
0
⋅
1
如某些算法单次计算依赖全局数据,这个应该做不到分布式并行计算?
一个算法能否并行计算的前提是这个:每个工作节点上的rdd都是已经被切分的数据片,可隔离并行计算? 如果是这样,那分布式机器学习算法的范畴是否比较小?应该也存在的解决方式吧?
spark 伪分布式模式的性能怎么样? 能否替换传统数据处理里的某些场景?
by
七里芬芳
https://hainiubl.com/topics/36099?
2019-03-14
⋅
2598
⋅
0
⋅
1
spark伪分布式模式的性能怎么样? 能否替换传统数据处理里的某些场景?
Linux 平台完全分布模式下 Hadoop 实例 wordcount 在 eclipse 编写运行权限问题?
by
七里芬芳
https://hainiubl.com/topics/36100?
2019-03-14
⋅
2333
⋅
0
⋅
1
Linux平台完全分布模式下Hadoop实例wordcount在eclipse编写运行权限问题:
Exception in thread "main" java.io.IOException: 权限不够
at java.io.UnixFileSystem.createFileExclusively(Native Method)
at java.io.File.createTempFile(File.java:1879)
at org.ap...
怎样用 kmeans 对类似 00101001110011001...这样的一连串序列进行聚类?
by
七里芬芳
https://hainiubl.com/topics/36209?
2019-03-18
⋅
2485
⋅
0
⋅
1
目的是算有多少个1,一个1代表一个人,但是0-1变化段有阶跃,所以用kmeans算法处理,目的是算有多少个1,希望有人回答一下,感谢~~
Spark updateStageByKey 产生的大量 checkpoint 小文件在 hdfs 上怎么处理?
by
卢本伟牛X
https://hainiubl.com/topics/36214?
2019-03-18
⋅
4068
⋅
0
⋅
1
Spark Streaming实时分析
HDFS 全部文件的元数据是存储在 namenode 节点的硬盘还是内存?
by
卢本伟牛X
https://hainiubl.com/topics/36215?
2019-03-18
⋅
3852
⋅
0
⋅
1
HDFS全部文件的元数据是存储在namenode节点的硬盘还是内存?
为什么 Python 中无法输出 2.00?
by
听说
https://hainiubl.com/topics/36216?
2019-03-18
⋅
2534
⋅
0
⋅
1
为什么Python中无法输出2.00?
vs code Python debug 代码能 debug 到源码吗,如何设置?
by
听说
https://hainiubl.com/topics/36217?
2019-03-18
⋅
2616
⋅
0
⋅
1
vs code Python debug代码能debug到源码吗,如何设置?
请问如何提升 java GZIPOutputStream 压缩速度?
by
张凌天
https://hainiubl.com/topics/36219?
2019-03-18
⋅
3174
⋅
0
⋅
1
代码如下
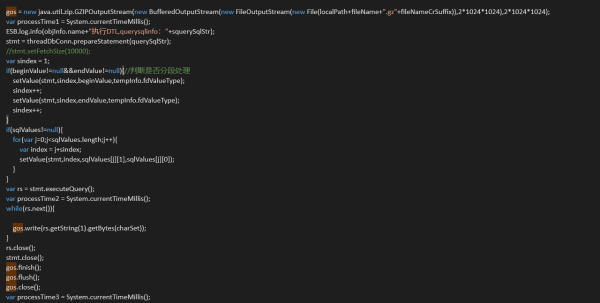
业务为查询库内数据压缩为gz压缩包,然后上传。现在速度很慢,已经尝试优化sql,sql查询速度提升了7倍还是无法满足需求,如何提升gz压缩速度呢?