关于 “” 的搜索结果, 共 2411 条
为什么我写了删除 listbox 数据的代码,但第二次,点击查找按钮时,上一次的数据还在那里?
by
 陪你去看海
陪你去看海
https://hainiubl.com/topics/36337?
2019-04-30
⋅
2519
⋅
0
⋅
1
面向对象中的多态在 Python 中是否没有什么意义?
by
 Best
Best
https://hainiubl.com/topics/36338?
2019-04-30
⋅
2532
⋅
0
⋅
1
python中没有数据类型的概念。这是否意味着python中的多态是没有什么意义的?
用 sublim 写 python 为什么出来是?号?
by
 neo
neo
https://hainiubl.com/topics/36339?
2019-04-30
⋅
2424
⋅
0
⋅
1

python+cnn 实现手写数字识别时,测试结果如下,准确率特别低,而且基本没变,怎么解决?
by
 夜莺
夜莺
https://hainiubl.com/topics/36340?
2019-04-30
⋅
3729
⋅
0
⋅
1
以下是我的源代码和调试截图:

...
Hive 为什么每次启动都需要初始化元数据,不然会报错如下,怎么解决?
by
 七里芬芳
七里芬芳
https://hainiubl.com/topics/36341?
2019-05-06
⋅
3378
⋅
0
⋅
1
Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
如何测试 Spark 结点之间的网络流量?
by
 y514637059
y514637059
https://hainiubl.com/topics/36342?
2019-05-06
⋅
2256
⋅
0
⋅
1
有一个项目,要求减少Spark的结点(服务器)之间的流量,不知道有什么工具可以比较好的实现这点?
spark 读取 sql 文件并创建 Graphx 图如何操作?
by
 那些年后会有期
那些年后会有期
https://hainiubl.com/topics/36343?
2019-05-06
⋅
2604
⋅
0
⋅
1
利用IDEA读取sql文件并生成对应的图(利用sql中的数据产生图)。具体操作怎么做呢,大佬给解释解释
Spark 如何用在大型算法的项目中?
by
 雾走黄昏
雾走黄昏
https://hainiubl.com/topics/36344?
2019-05-06
⋅
2770
⋅
0
⋅
1
在大型算法项目中Spark除了做数据预处理和调用SparKMlib的算法库,还担任了什么角色?因为听别人说他们用Spark做算法写了几万行,但是如果只做这两个事情代码量不会大吧。希望Spark大神不吝赐教。
如何获取 kafka 某一 topic 中最新的 offset?
by
 天灬空
天灬空
https://hainiubl.com/topics/36345?
2019-05-06
⋅
3468
⋅
0
⋅
1
我想要读取topic中最新一条消息的offset,与当前消费者正在读取的offset比较,如果差值过大就舍弃中间的消息以保证实时性。
kafka high-level consumer的Java API有没有提供获取指定topic最新的offset的功能?
kafka 是否适合在 docker 中使用?单机集群是否有意义?
by
 矢量
矢量
https://hainiubl.com/topics/36346?
2019-05-06
⋅
3270
⋅
0
⋅
1
1、生产环境下,是否适合在docker中使用kafka cluster?
2、如果在一台服务器上启动多个kafaka server(或docker容器)来实现cluster,是否有意义?或者说,单机多实例的集群是否有意义,不单是kafka,zookeeper、tomcat这些呢?
请教!
kafka 使用 high API 如何确保不丢失消息,不重复发送,消息只读取一次?
by
 慧有未来
慧有未来
https://hainiubl.com/topics/36347?
2019-05-06
⋅
2450
⋅
0
⋅
1
虽然low api可以通过offset来实现,但是感觉好麻烦
用 python 怎么求概率密度函数的累积分布,并确定上下限分位点?
by
 海纳百川
海纳百川
https://hainiubl.com/topics/36349?
2019-05-06
⋅
6123
⋅
0
⋅
1
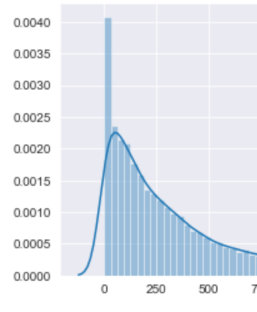
用Scikit-learn库中的Kernel Density Estimation去作出概率密度分布之后,得到了相应的分布曲线,但是怎么去求取这个曲线的累积分布呢?再有,怎么确定上下限α分位点?
在编辑 jieba.analyse.set_stop_words 的停用词库时,能否用正则表达式?
by
 良子
良子
https://hainiubl.com/topics/36350?
2019-05-06
⋅
4390
⋅
0
⋅
1
例如想停用带有 “集” 字的词,在.txt里添加 “[\u4e00-\u9fa5]集” 并没有用,是本就无此功能还是我语法的问题,语言: python,IDE: pycharm,系统:macOS(10.13.6)
请教各位,安装 pip3 时报错缺少 ctypes 模块,该怎么办?
by
 星期八
星期八
https://hainiubl.com/topics/36351?
2019-05-06
⋅
4219
⋅
0
⋅
1
我在Linux上安装pip3时,已经安装了libffi-devel,但是在执行python3 setup.py build时仍然报错缺少_ctypes模块,想问问各位还怎么破
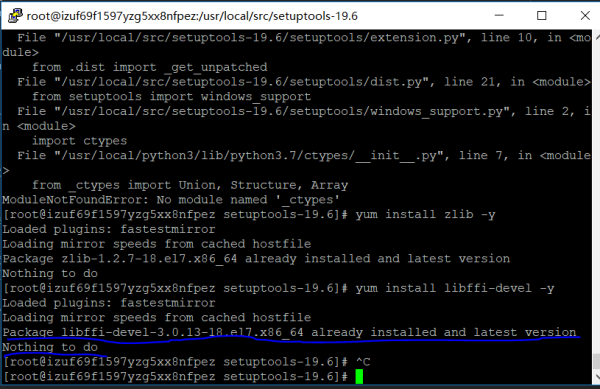
上图提示已经安装libffi-devel
 liuye
liuye
https://hainiubl.com/topics/36352?
2019-05-06
⋅
2420
⋅
0
⋅
1
请问如果有红橙黄三种颜色,然后进行独热编码,如果一个样本点有红黄两种性质,该怎么编码?
python 里为什么要有虚拟子类?
by
 大地
大地
https://hainiubl.com/topics/36353?
2019-05-06
⋅
3510
⋅
0
⋅
1
我理解了虚拟子类和真实子类之间的区别,可是为什么python里需要虚拟子类呢?有哪些环境下 是非要虚拟子类才能解决,而真实子类解决不了的呢?
numpy 中如何快速索引单个元素?
by
 妞妞
妞妞
https://hainiubl.com/topics/36354?
2019-05-06
⋅
2638
⋅
0
⋅
2
比如现在我有 a = np.array([[1,2,3],[4,5,6],[7,8,9]])
然后我有另一个数组 b = np.array([0,2,0]) 即为每行中我想取的那一列
如何快速得到c = [1,8,3]?
或者一个W x H x C的RGB图像I,现在我有一个W x H的矩阵m,里面的值为0,1或2,即为 个行列中我想取的...
Python 当中 slice 和 split 有什么区别,分别怎么使用?
by
 Wiley
Wiley
https://hainiubl.com/topics/36355?
2019-05-06
⋅
2898
⋅
0
⋅
1
Python当中slice和split有什么区别,分别怎么使用?
Spyder 调试环境如何查看函数调用堆栈?
by
 Phyllis2016
Phyllis2016
https://hainiubl.com/topics/36356?
2019-05-06
⋅
3363
⋅
0
⋅
1
Spyder调试环境如何查看函数调用堆栈?
怎么评价:computer only know what you tell them?
by
 高文超
高文超
https://hainiubl.com/topics/36357?
2019-05-06
⋅
2294
⋅
0
⋅
1
这个是不是和人类的本质都是复读机有一样的妙处呢?喵喵喵?
hive 使用 group by order by 之后与 MySQL 查询出来的数据不一致?
by
 好好学习
好好学习
https://hainiubl.com/topics/36391?
2019-05-07
⋅
3835
⋅
0
⋅
2
SELECT cat_name,com_prov,count(*) from itjuzi_company_detail GROUP BY cat_name,com_prov ORDER BY cat_name,com_prov;
同样的语句放在hive/impala MySQL中执行查询结果如下:

 浮华
浮华
https://hainiubl.com/topics/36394?
2019-05-07
⋅
2290
⋅
0
⋅
1
我从Spark SQL中读取了dataFrame
我该怎样去寻找 or 映射它们的特征?
数据格式如图(想通过后面的属性预测销量)

谢谢大佬们了 困扰了好长时间了
官网上例子都是给定好的格式直...
为什么进程缺少 namenode,datanode,secondarynamenode?
by
 0123
0123
https://hainiubl.com/topics/36395?
2019-05-07
⋅
3125
⋅
0
⋅
1
Hadoop配置文件已经设置好,但是启动后namenode,datanode,secondarynamenode都没有(来自一名刚开始学的新手小白的发问~)
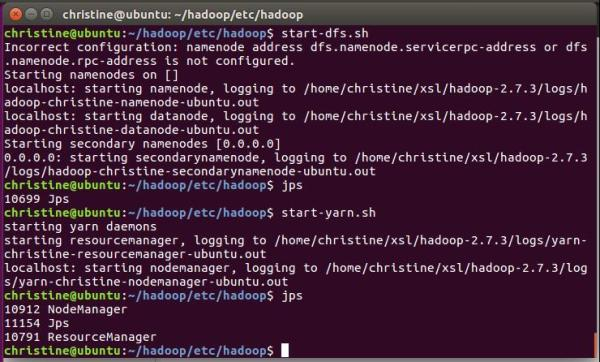
搭建 Hadoop 集群和 hbase 集群时,Hadoop2.9.2 和 habase 哪一个版本相匹配?
by
 萌萌小可怜
萌萌小可怜
https://hainiubl.com/topics/36396?
2019-05-07
⋅
3671
⋅
0
⋅
1
Hadoop2.9.2和hbase哪一个版本相同,又和哪一个zookeeper版本对应?
Hive 为什么每次启动都需要初始化元数据,不然会报错如下,怎么解决?
by
 我是小小美食家
我是小小美食家
https://hainiubl.com/topics/36397?
2019-05-07
⋅
3490
⋅
0
⋅
1
Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
HIVE 中如何将一个分区表的某些字段插入另一个分区表的各个分区?
by
 liyuexin
liyuexin
https://hainiubl.com/topics/36398?
2019-05-07
⋅
3395
⋅
0
⋅
1
hello,各位:
需求背景是这样的:
有一个母表A(其中有字段若干)
现在要将母表A中的a,b,c三个字段插入映射表b。
请问如何实现?
Spark 中如何正确使用多线程保存数据到 Hive?
by
 许宁
许宁
https://hainiubl.com/topics/36401?
2019-05-07
⋅
2664
⋅
0
⋅
1
在使用多线程处理多个单笔复杂数据时,在保存到Hive的过程中线程BLOCK了,Spark中如何正确使用多线程保存数据到Hive中?
机器学习的回归分析相比于传统的分析方法精度有没有提高?
by
 静刚
静刚
https://hainiubl.com/topics/36402?
2019-05-08
⋅
2602
⋅
0
⋅
1
想到这个问题 问问大佬们
如何实际使用 mimikittenz 在 PowerShell 运行并读出数据?
by
 落
落
https://hainiubl.com/topics/36403?
2019-05-08
⋅
2903
⋅
0
⋅
1
安全测试,学习。
请问 Spark 如何利用 GPU 资源计算?
by
 雨
雨
https://hainiubl.com/topics/36404?
2019-05-08
⋅
2511
⋅
0
⋅
1
要做毕设,要优化一个算法(不是机器学习相关的),这个算法本来只是利用Spark平台,导师建议把Spark和GPU结合起来,让Spark调用GPU资源进行计算,但是最近几天查了很多资料,方法似乎有很多,但是感觉可行的太少,目前情况是这样的:
原来这个算法是用python的pyspa...