关于 “” 的搜索结果, 共 2411 条
广州&杭州 大数据开发工程师 招聘
by
 外向或闪灵
外向或闪灵
https://hainiubl.com/topics/76374?
2023-09-18
⋅
1177
⋅
1
⋅
0
**招聘要求**
1. 本科毕业3年起,计算机类或相关专业,3年以上大数据项目开发经验。
2. 熟悉linux系统及相关命令,能熟练编写hell脚本完成日常系统运维等工作。
3. 熟悉Hadoop.Hbase.Flink.Spark.zookeeper等技术,并有过实际项目经验,能定位和解决这些组件使用...
北京 大数据&云计算运维 15k-18k
by
外向或闪灵
https://hainiubl.com/topics/76376?
2023-09-19
⋅
1207
⋅
1
⋅
0
**岗位描述:**
1. 负责用户专有云集群的维护、管理、故障排除等日常工作,确保系统的正常稳定运行;
2. 负责用户资源开通、帐号开通、提供产品使用指引;
3. 负责监控云集群健康状态,定时巡检并做好记录,按时发送日报周报;
4. 负责专有云集群各故障处理,及...
上海 初级大数据开发工程师 11-12K
by
外向或闪灵
https://hainiubl.com/topics/76377?
2023-09-19
⋅
1357
⋅
1
⋅
0
**招聘要求:**
1. 全日制统招本科,学信网可查,2年及以上相关经验,计算机相关专业优先;
2. 熟悉使用SQL开发语言;
3. 精通Oracle等关系型数据库;
4. 精通HBASE Hive等大数据平台数据库系统。
感兴趣的同学请在下方跟帖报名!
老学员推荐 北京 数据开发、数据处理岗位 13-20K
by
外向或闪灵
https://hainiubl.com/topics/76378?
2023-09-21
⋅
1231
⋅
1
⋅
0
**工作职责:**
1. 参与数据中台建设;
2. 参与项目数据处理及服务器、数据运维及相关文档整理;
3. 根据产品、项目需求,参与数据库设计及数据处理流程优化。
**岗位要求:**
1. 计算机及其它相关专业;4年以上工作经验。
2. 熟悉Java,熟练常用的设计模式,数...
hive count (distinct) over (partition by) 去重问题?
by
 Auroral
Auroral
https://hainiubl.com/topics/76380?
2023-10-03
⋅
1275
⋅
1
⋅
0
原表内容如下:
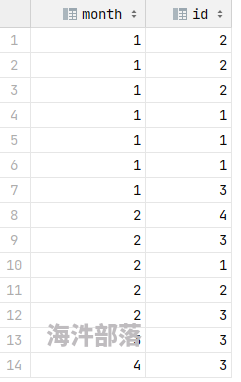
sql和结果如下:
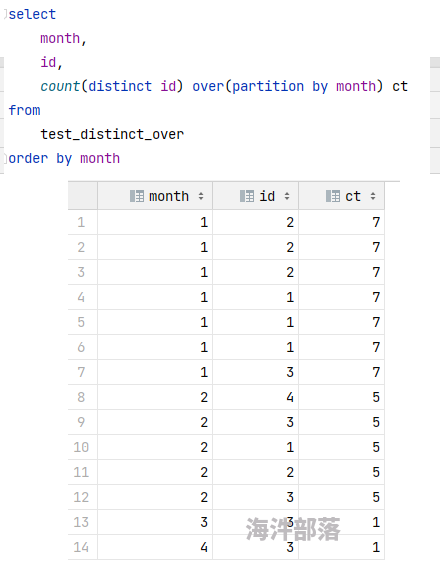
为什么去重失效了
通过 Spark ThriftServer 查询 Hive 效率太慢,有没有优化办法?
by
 KeepFire
KeepFire
https://hainiubl.com/topics/76381?
2023-10-04
⋅
1705
⋅
2
⋅
3
Hive的单分区量级5亿条左右,使用Spark的ThriftServer执行SQL
```
SELECT * FROM table_name WHERE `date` = '2023-10-02' AND `when`> 1696176000 AND `when` < 1696262340 AND pre_id > 10000 order by `when` desc limit 500
```
因为想做分页查询,排序使得查询...
老学员推荐 北京 数据仓库研发 储存研发 运维开发工程师 985/211 优先
by
外向或闪灵
https://hainiubl.com/topics/76382?
2023-10-10
⋅
1470
⋅
0
⋅
0
具体岗位职责和要求:
运维开发工程师:
【工作职责】
1. 负责公司内外部系统的搭建,日常管理及运维
2. 负责 DevOps 平台,基础设施,自动化平台的开发和维护
【任职要求】
1. 熟练掌握 linux 运维工具,熟悉数据库运维
2. 熟悉 ansible 等自动化运维工具优先
3....
HDFS 写数据时,DataNode 为什么是串行写?
by
 Jane
Jane
https://hainiubl.com/topics/76383?
2023-10-11
⋅
1489
⋅
2
⋅
2
HDFS写数据时,DataNode为什么是串行写?
YARN
by
 DER
DER
https://hainiubl.com/topics/76384?
2023-10-12
⋅
1788
⋅
1
⋅
0
# YARN
## 1.yarn的概述
大数据的组成部分两个,分别是分布式存储和分布式计算
hdfs解决的部分是分布式存储
yarn解决的是分布式计算,但是在hadoop1.x版本中的时候是没有yarn的,后续为了灵活和负载均衡的操作才出现了yarn资源管理平台
**问题1:什么是资源**
 湛蓝枫铃
湛蓝枫铃
https://hainiubl.com/topics/76385?
2023-10-13
⋅
1569
⋅
1
⋅
2
在实际工作中多少数据量需要用到大数据平台?怎么评估需要多少台机器呢,比如我3台8核CPU,16G内存的机器,大概可以支持多少数据量
大数据开发负责人 北京 30-50k*12 薪
by
外向或闪灵
https://hainiubl.com/topics/76387?
2023-10-23
⋅
1384
⋅
0
⋅
0
**简历筛选要求:**
33岁以内,5年以上工作经验,第一学历是统招本科,计算机相关专业
**岗位职责: **
1. 负责大数据团队的建设和管理;
2. 负责公司数据仓库和数据离线/在线处理系统的架构设计和开发、维护
3. 为其它业务提供数据支持服务,构建并完善数据链...
[公开课直播预告] 太神了,有了《海汼部落云平台》玩转数仓如此简单(10月27日)
by
 青牛
青牛
https://hainiubl.com/topics/76388?
2023-10-25
⋅
7218
⋅
6
⋅
64
## 天那太难了,挑灯熬夜背了一堆八股文,面试还要追着问我具体实现过程,我该怎么办?
> 别急通过本次公开课你至少能动手练起以下几个大数据组件:
### 1. ETL工具:kettle实现日志ETL
### 2. flume:收集日志数据到大数据平台
### 3. sqoop:收集mysql数据到...
[公开课直播预告] 多 Hadoop 集群间如何做数据迁移(11月1日)
by
青牛
https://hainiubl.com/topics/76389?
2023-10-30
⋅
1382
⋅
1
⋅
1
## 在公司特别是大厂,你可能会碰到这样的情况,原有的Hadoop集群空间不足要么扩容要么做数据迁移。
> 就拿常见的数据迁移的办法有下面几种:
### 1. 网络隧道拷贝
### 2. 单OP机多Hadoop集群操作
### 3. Hadoop集群间完成分布式拷贝
> 您可以跟着本次公开课...
[公开课直播预告] 亿级 HBase 数据迁移解决方案(11月4日)
by
青牛
https://hainiubl.com/topics/76390?
2023-11-02
⋅
1447
⋅
0
⋅
0
## HBase是个好东西,能应对大数据场景下数据秒查的场景,但是使用不得当就会遇到各种坑,比如在做海量数据迁移的时候,如果操作不正确就会遇到双库崩溃的场景,那该怎么办?通过本次公开课你将学到最终的解决方案。
> 就拿HBase常见的数据迁移的办法有下面几种:...
使用 GPT+SQL 开发=SQLGPT 解放数据开发工程师代码开发的繁琐程度
by
 sfguo
sfguo
https://hainiubl.com/topics/76392?
2023-11-03
⋅
1814
⋅
0
⋅
0
## GPT + SQL开发:
> 实现根据语言提问生成你想要的结果,省去亲自写sql查询的过程。
### 前期背景
LangChain:由语言模型LLMs驱动的应用程序框架,它允许用户围绕大型语言模型快速构建应用程序和管道。
可以直接与 OpenAI 的 ChatGPT 模型以及 Hugging Face 集...
Hbase 数据迁移
by
DER
https://hainiubl.com/topics/76393?
2023-11-03
⋅
1952
⋅
0
⋅
1
# Hbase数据迁移
在生产和工作环境中,我们有时候会遇见集群的升级,集群的冷热备份,公司多集群间数据转移的问题,这个时候hbase作为在大数据环境中主流的存储数据库,是首当其冲需要解决的问题,那么以下我们通过三种方式实现两个集群间的数据的迁移。
## 1.回顾...
[公开课直播预告] MySQL 数据同步与高可用架构设计(11月9日)
by
青牛
https://hainiubl.com/topics/76394?
2023-11-05
⋅
1452
⋅
0
⋅
0
## 在大数据组件中经常能看到Mysql的身影,它常用于存储各组件的元数据,在使用这些组件时虽然不用直接操作它,但是如果它坏了那也算得上生产大事故了,那怎么保证Mysql的安全性呢?
> 常见的Mysql高可用方式有以下几种:
### 1. 轻松搞定mysql数据灾备
### 2....
车联网安全书籍?
by
Gloria
https://hainiubl.com/topics/76395?
2023-11-06
⋅
1293
⋅
0
⋅
0
家人们,作为一个新能源汽车行业网络安全小白,目前在研读《智能汽车网络安全权威指南》,感觉很通透,还有没有类似的书籍推荐呀?
大数据现在用 python 学好一点,还是用 Java 学?
by
 被遗忘的十七
被遗忘的十七
https://hainiubl.com/topics/76396?
2023-11-07
⋅
1300
⋅
0
⋅
5
纯萌新什么都不明白
大数据运维&高级运维 薪资 17-18k 广州
by
外向或闪灵
https://hainiubl.com/topics/76397?
2023-11-09
⋅
1241
⋅
1
⋅
0
**招聘要求:**
1. 全日制大专以上学历,5年以上运维经验;
2. 精通Linux/Unix,会编写shell/Python/Go等脚本
3. 熟悉Prometheus/Zabbix等监控管理工具,熟悉自动化运维,熟练使用Ansible/puppet/SaltStack其中至少一项工具
4. 熟悉k8s,Nginx,Redis;熟悉MySQL、O...
数仓开发 上海浦东新区 12k
by
外向或闪灵
https://hainiubl.com/topics/76398?
2023-11-09
⋅
1472
⋅
0
⋅
0
**岗位要求:**
1. 统本3年经验, 有完整的BI项目经验;
2. 熟悉主流ETL开发工具和报表开发工具
3. 熟练finebi或者Smartbi开发报表。
感兴趣的同学请在下方跟帖报名!
大数据开发工程师 11-12k*12 薪 北京
by
外向或闪灵
https://hainiubl.com/topics/76399?
2023-11-10
⋅
1217
⋅
0
⋅
0
**岗位职责**
1. 负责业务部门提交需求的分析,实现对数据的统计、分析,保证数据质量;
2. 负责数据仓库、数据集市等业务模型的设计;
3. 负责数据处理过程的调优,突发事件的处理与分析;
**任职要求**
1. 本科以上学历,3年以上数仓建模或数据开发经验。
2....
[公开课直播预告] Hive 高可用架构如何设计?(11月15日)
by
青牛
https://hainiubl.com/topics/76400?
2023-11-10
⋅
1456
⋅
0
⋅
0
## Hive是非常常用的一个数仓工具之一,在使用Hive的时候经常会遇到hiveServer2服务和metastore服务出现问题无法连接的问题,项目经理让你优化,一脸懵!!!那么如何实现hiveServer2和metastore的HA部署呢?
> 本次直播课内容如下:
### 1.轻松掌握hive本地部署...
大数据毕业设计选题推荐?
by
 xiangruiH
xiangruiH
https://hainiubl.com/topics/76401?
2023-11-15
⋅
1260
⋅
0
⋅
0
最近毕业设计选题,请问有哪些好的选题推荐。我的想法是用hadoop做数据存储,然后对存储的数据进行分析挖掘(机器学习)最后再在网页上展示。
[公开课直播预告] Flume 多节点海量数据采集解决方案(11月23日)
by
青牛
https://hainiubl.com/topics/76402?
2023-11-16
⋅
1364
⋅
0
⋅
0
## **flume是在大数据生态圈中比较重要的一个日志采集工具,但是对于多种source,channel,sink等使用你熟悉吗,尤其在复杂业务场景中的多个flume联合搭配使用你会吗?那么如何在不同的场景中实现flume的灵活使用呢?**
> 本次直播课内容如下
### **1. 实现自定义f...
大数据开发工程师 13-20k 武汉
by
外向或闪灵
https://hainiubl.com/topics/76403?
2023-11-17
⋅
1256
⋅
0
⋅
0
**岗位职责:**
1. 负责基于spark,flink的离线/实时数据计算和维护
2. 负责大规模业务,日志等数据的收集、清洗、入库、分析等工作
3. 负责数据治理,接口开发等工作, 提升数据易用性及数据质量
4. 理解并合理抽象业务需求,发挥数据价值,与业务团队紧密合作
5. 大...
[公开课直播预告] kafka 新特性和动态扩容(11月 30日)
by
青牛
https://hainiubl.com/topics/76405?
2023-11-24
⋅
1382
⋅
0
⋅
0
## **kafka是在大数据中的非常重要的一个组件,对于实时任务来说是必不可少的,无论从性能和设计上来说都是无与伦比的,那么你知道kafka的kraft集群的吗,那么你知道在海量数据的场景中如何实现动态均衡和节点动态上下线吗??**
> 本次直播课内容如下
### **1. ka...
镜像文件如何与我本地 IP 互通?
by
洋洋洋
https://hainiubl.com/topics/76406?
2023-11-27
⋅
1192
⋅
0
⋅
1
镜像文件如何与我本地IP互通?
datanode 挂了?
by
yjx
https://hainiubl.com/topics/76407?
2023-11-28
⋅
1205
⋅
0
⋅
2
hdfs在写的过程中datanode挂了怎么处理?
看网上说首先 Pipeline数据流管道会被关闭,ACK queue中的packets会被添加到data queue的前面以确保不会发生packets数据包的丢失。
我这里有两个问题
第一个是ACK queue在哪里,有的说在pipeline第一个datanode上,有的说在...