关于 “” 的搜索结果, 共 2411 条
云平台运维工程师 南京 15k
by
 外向或闪灵
外向或闪灵
https://hainiubl.com/topics/76408?
2023-11-30
⋅
1223
⋅
0
⋅
0
职责:
1. 监控云平台的运行,确保系统的稳定性和性能,及时发现并解决问题
2. 参与SOC安全监控工作,监测潜在的安全风险和威胁。
3. 进行网络监控,检查网络流量和性能问题,协助解决网络故障。
4. 接收、记录和跟踪客户工单,确保及时解决客户问题
5. 提供高质量...
[公开课直播预告] kafka 的多种认证方式和信道加密(12月7日)
by
 青牛
青牛
https://hainiubl.com/topics/76409?
2023-12-01
⋅
1271
⋅
0
⋅
0
## **kafka作为实时场景中必不可少的组件之一,实时任务在接入kafka的时候你知道如何进行安全认证吗??在数据传输的时候你知道如何进行信道加密吗?**
> 本次直播课内容如下
### **1. kafka之安全认证方式**
### **2. kafka之授权管理和信道加密**
> 您可...
systemctl 启动报错?
by
 dinging88
dinging88
https://hainiubl.com/topics/76410?
2023-12-08
⋅
1261
⋅
2
⋅
3
systemctl start mysqld报错如下
Failed to get D-Bus connection: Operation not permitted
[公开课直播预告] CDH 集群扩容(12月14日)
by
青牛
https://hainiubl.com/topics/76411?
2023-12-08
⋅
1529
⋅
1
⋅
11
## **CDH是一个大数据平台,简化和加速了大数据处理分析的部署和管理。已经入职的你,领导让你进行CDH集群扩容,你该怎么办?不用懵逼,跟随本次直播课,轻松学会CDH节点扩容部署。**
> 本次直播课内容如下
### **1. 掌握CDH搭建流程**
### **2. 轻松学会CDH扩容...
大数据开发工程师 北京 14-20K·13 薪
by
外向或闪灵
https://hainiubl.com/topics/76412?
2023-12-08
⋅
1181
⋅
0
⋅
0
岗位职责:
1. 熟悉整个大数据的完整处理流程(数据的采集.清洗.预处理.存储.分析挖掘.机器学习和数据可视化等),有完整的大数据项目设计.开发及部署经验;
2. 熟悉大数据相关组件,了解各组件的原理,并能够根据实际问题分析原因,具备较强的解决问题的能力;
3. 具...
大数据开发工程师 18-30k 北京
by
外向或闪灵
https://hainiubl.com/topics/76414?
2023-12-08
⋅
1202
⋅
0
⋅
0
团队伙伴友善团结、氛围好
公司近地铁,步行5分钟左右
1. 薪资范围:18k-30k,具体面议
2. 劳动保障:签订正规劳动合同,入职即可享受五险一金
3. 工作时间:(弹性工作制)早上9:30上班,中午12:00-13:30午休,下午18:30下班
4. 休假福利:周六日双休,法定节假...
大数据开发工程师 13-25k*13 薪 北京
by
外向或闪灵
https://hainiubl.com/topics/76415?
2023-12-08
⋅
1118
⋅
0
⋅
0
岗位职责:
1. 技术开发:技术研究、技术选型、环境部署、技术验证、技术培训
2. 产品开发:开发大数据基础平台支撑各类产品的研发工作
3. 项目实施:架构设计、大数据接入、接口服务、计算、数据处理
4. 日常运维:算法提炼、知识库、工具库、培训
5. 售前支持:...
大数据运维工程师 15-20k 北京
by
外向或闪灵
https://hainiubl.com/topics/76416?
2023-12-08
⋅
1154
⋅
0
⋅
0
岗位职责:
1. 管理公司大数据集群,提供高可用、高性能大数据集群系统,并保障系统稳定运行,包括但不限于Hadoop、Kafka、Redis 、HBase 、Zookeeper、Hdfs、Hive、Spark、Storm、Tidb等系统;
2. 负责大数据集群性能监控与优化,故障处理,数据备份及灾难恢复。
3....
大数据运维工程师 10-15k 南京
by
外向或闪灵
https://hainiubl.com/topics/76417?
2023-12-11
⋅
1286
⋅
0
⋅
2
岗位职责:
1. 负责Hadoop平台搭建,运维,管理,故障处理。
2. 负责保障大数据平台的高效运转、提升系统稳定性和安全性。
3. 对平台的Hadoop,Hbase,Kafka,Hive等进行优化。
4. 建立Hadoop集群管理和维护规范,包括版本管理和变更记录等。
岗位要求:
1. 有...
大数据运维工程师 14-25k 北京
by
外向或闪灵
https://hainiubl.com/topics/76418?
2023-12-11
⋅
1308
⋅
0
⋅
0
工作职责 :
1. 负责大数据底层基础架构平台的运维、规划、部署、管理、扩容和优化等,保障服务的稳定性和可用性,发现并解决性能瓶颈等;
2. 深入理解hadoop生态组件原理,为其持续优化提供建设性意见,负责组件HDFS、Yarn、Flink、Hive、Presto、Spark、Zookeeper...
大数据开发工程师 13-15k 安徽芜湖
by
外向或闪灵
https://hainiubl.com/topics/76419?
2023-12-15
⋅
1372
⋅
0
⋅
0
**岗位描述:**
1. 负责用户专有云集群的维护、管理、故障排除等日常工作,确保系统的正常稳定运行;
2. 负责用户资源开通、帐号开通、提供产品使用指引;
3. 负责监控云集群健康状态,定时巡检并做好记录,按时发送日报周报;
4. 负责专有云集群各故障处理,及时通...
[公开课直播预告] 可视化数据大屏设计(12月21日)
by
青牛
https://hainiubl.com/topics/76420?
2023-12-16
⋅
2847
⋅
0
⋅
18
## **当我们在做数据开发过程中,无论数据体量是否庞大,都不可避免地会出现数据可视化的需求,跟着本次直播课学会怎么最终将数据炫酷的展示出来,使数据处理真正做到闭环**
> 本次直播课内容如下
### **1. 掌握FineReport常用图表及其功能**
### **2. 轻松学会...
[B 站公开课] 玩转数仓如此简单
by
青牛
https://hainiubl.com/topics/76421?
2023-12-19
⋅
1438
⋅
0
⋅
0
公开课回放地址:https://www.bilibili.com/video/BV1wG411Y7dd
# 酷牛商城商品点击率
# 1.数据源准备
## 1.1 酷牛商城启动
启动酷牛商城镜像
地址:http://cloud.hainiubl.com/#/privateImageDetail?id=14167&imageType=private
添加共有镜像kettl...
[B 站公开课] 多 Hadoop 集群间如何做数据迁移
by
青牛
https://hainiubl.com/topics/76422?
2023-12-19
⋅
1741
⋅
0
⋅
0
公开课回放地址:https://www.bilibili.com/video/BV14j411W7g3
# hadoop数据迁移
Hadoop 是一个分布式计算平台,提供了数据存储和数据计算的功能。
当有机房下线,数据容灾,机房搬迁等应用场景时。就需要将原来hadoop集群中的数据迁移到新的集群中时,就需要考...
[B 站公开课] 亿级 HBase 数据迁移解决方案
by
青牛
https://hainiubl.com/topics/76423?
2023-12-19
⋅
2128
⋅
0
⋅
0
公开课回放地址:https://www.bilibili.com/video/BV1eN4y1b7CU
# Hbase数据迁移
在生产和工作环境中,我们有时候会遇见集群的升级,集群的冷热备份,公司多集群间数据转移的问题,这个时候hbase作为在大数据环境中主流的存储数据库,是首当其冲需要解决的问题,那...
[B 站公开课] MySQL 数据同步与高可用架构设计
by
青牛
https://hainiubl.com/topics/76424?
2023-12-19
⋅
1867
⋅
0
⋅
0
公开课回放地址:https://www.bilibili.com/video/BV1eN4y1b7Ub
# MySQL 数据同步与高可用架构设计
# msyql实现主从同步
## 1.为什么要同步
1,业务量越来越大,一台机器可以接收的请求是有限的。并且单台机器的I/O也是有瓶颈的,此时做多库的存储,降低磁盘I...
[B 站公开课] Hive 高可用架构如何设计?
by
青牛
https://hainiubl.com/topics/76425?
2023-12-19
⋅
1899
⋅
0
⋅
0
公开课回放地址:https://www.bilibili.com/video/BV1FQ4y137nx
# 1.hive介绍

Hive是一个**基于**Hadoop的开源数据仓库工具,用于存储和处理海量结构化数据。它...
[B 站公开课] Flume 多节点海量数据采集解决方案
by
青牛
https://hainiubl.com/topics/76426?
2023-12-19
⋅
2478
⋅
0
⋅
0
公开课回放地址:https://www.bilibili.com/video/BV1iC4y1g7eM
# Flume 多节点海量数据采集解决方案
Flume是一种可配置、高可用的数据采集工具,主要用于采集来自各种流媒体的数据(Web服务器的日志数据等)并传输到集中式数据存储区域。
Flume 支持在日志系统...
[B 站公开课] Kafka 新特性和动态扩容
by
青牛
https://hainiubl.com/topics/76427?
2023-12-19
⋅
2337
⋅
1
⋅
1
公开课回放地址:https://www.bilibili.com/video/BV1He411C7hP
# kafka新特性和动态扩容
## 1.kafka是什么
Kafka是由LinkedIn开发的一个分布式的<font color='red'>消息队列</font>。它是一款开源的、轻量级的、分布式、可分区和具有复制备份的(Replicated)...
[B 站公开课] Kafka 的多种认证方式和信道加密
by
青牛
https://hainiubl.com/topics/76428?
2023-12-19
⋅
2919
⋅
1
⋅
0
公开课回放地址:https://www.bilibili.com/video/BV1yQ4y1g7MW
# kafka的权限设置
## Kafka 认证机制
> 自 0.9.0.0 版本开始,Kafka 正式引入了认证机制,用于实现基础的安全用户认证,这是将 Kafka 上云或进行多租户管理的必要步骤。截止到 2.3 版本,Kafka 支...
[B 站公开课] CDH 集群扩容
by
青牛
https://hainiubl.com/topics/76429?
2023-12-19
⋅
2591
⋅
1
⋅
0
公开课回放地址:https://www.bilibili.com/video/BV11p4y1o7Yc
# 背景
为什么要扩容?
1. 存储容量不足:当集群的存储空间接近或达到最大容量时,可能需要扩容
2. 计算资源不足:当集群中的计算资源(如CPU、内存)不足以应对负载增加时,需要进行扩容以提供更...
南京鼓楼区南瑞路 8号招 3年以上的大数据开发 1 名,薪资 12-18
by
外向或闪灵
https://hainiubl.com/topics/76430?
2023-12-19
⋅
1333
⋅
0
⋅
0
**任职要求:**
1. 本科及以上学历,计算机相关专业;
2. 3年以上大数据开发经验,熟悉Hadoop、Spark、Flink、Kafka等大数据技术;
3. 熟悉常用的数据存储和处理技术,如HDFS、HBase、Hive等
4. 熟练掌握Java或Scala开发语言,熟悉常用的数据结构和算法;
5. 具有分...
[B 站公开课] 可视化数据大屏设计
by
青牛
https://hainiubl.com/topics/76431?
2023-12-21
⋅
2435
⋅
0
⋅
0
公开课回放地址:https://www.bilibili.com/video/BV1yc411k7qQ
# 1.FineReport介绍
## 1.1 FineReport概述
FineReport 是**帆软**自主研发的企业级 Web 报表工具,用于报表制作,分析和展示的工具,用户通过使用 FineReport 可以轻松的构建出灵活的数据分析和...
公开课回放
by
青牛
https://hainiubl.com/topics/76432?
2023-12-22
⋅
3398
⋅
1
⋅
1
1. [玩转数仓如此简单](http://www.hainiubl.com/topics/76421)
2. [多 Hadoop 集群间如何做数据迁移](http://www.hainiubl.com/topics/76422)
3. [亿级 HBase 数据迁移解决方案](http://www.hainiubl.com/topics/76423)
4. [MySQL 数据同步与高可用架构设计](http:/...
大数据开发工程师 15-25K·13 薪 广州-惠州
by
外向或闪灵
https://hainiubl.com/topics/76433?
2024-01-11
⋅
1252
⋅
0
⋅
0
**招聘要求:**
1. 负责大数据平台、数据仓库、数据集市各数据层级的ETL开发。
2. 负责数据可视化分析报表开发。
3. 负责数据仓库平台核心系统及附属工具的运维工作及数据问题处理,协助DBA解决平台系统性能优化问题。
**任职要求:**
1. 全日制高等教育及以上...
大数据运维工程师 15-30K·14 薪 北京
by
外向或闪灵
https://hainiubl.com/topics/76434?
2024-01-11
⋅
1396
⋅
0
⋅
0
**岗位职责:**
1. 负责公司大数据业务集群(Hadoop/Hbase/Hive/Yarn/Spark/Flink/Kafka等)的建设与运维保障工作,保障服务的稳定性和可用性;
2. 深入研究大数据业务相关运维技术,持续优化集群服务架构,探索新的大数据运维技术及发展方向;
3. 负责和参与自动化运...
ETL 武汉合肥 8-13K
by
外向或闪灵
https://hainiubl.com/topics/76435?
2024-01-11
⋅
1254
⋅
0
⋅
0
**岗位职责:**
1. 负责产品的数据迁移及部分功能的二次开发;
2. 负责产品的线上技术支持,包括安装部署、产品答疑及问题分析排查等;
3. 积极响应、解决及收集现场实施人员的疑问及建议;
4. 协助领导完成其他技术支持相关工作。
**任职要求:**
1. 熟悉SQL...
大数据开发工程师 25-35K(北京)
by
外向或闪灵
https://hainiubl.com/topics/76436?
2024-01-25
⋅
1372
⋅
0
⋅
0
**岗位职责:**
1. 参与公司实时数据应用业务的落地;
2. 负责实时数据的开发、维护及统一性建设;
3. 负责标签系统、变量体系、知识图谱等系统的迭代.深入业务,为业务数据赋能;
4. 参与公司实时数据体系建设,保障实时体系数据的准确性、一致性、稳定性;
**任...
大数据运维工程师 15-20K 北京
by
外向或闪灵
https://hainiubl.com/topics/76437?
2024-01-25
⋅
1400
⋅
1
⋅
0
**岗位职责:**
1. 管理公司大数据集群,提供高可用、高性能大数据集群系统,并保障系统稳定运行,包括但不限于Hadoop、Kafka、Redis 、HBase 、Zookeeper、Hdfs、Hive、Spark、Storm、Tidb等系统;
2. 负责大数据集群性能监控与优化,故障处理,数据备份及灾难恢复。...
使用云平台 Spark 的默认配置可以支持百万级大数据的处理吗?
by
 NEMOlv
NEMOlv
https://hainiubl.com/topics/76439?
2024-02-22
⋅
1379
⋅
0
⋅
1
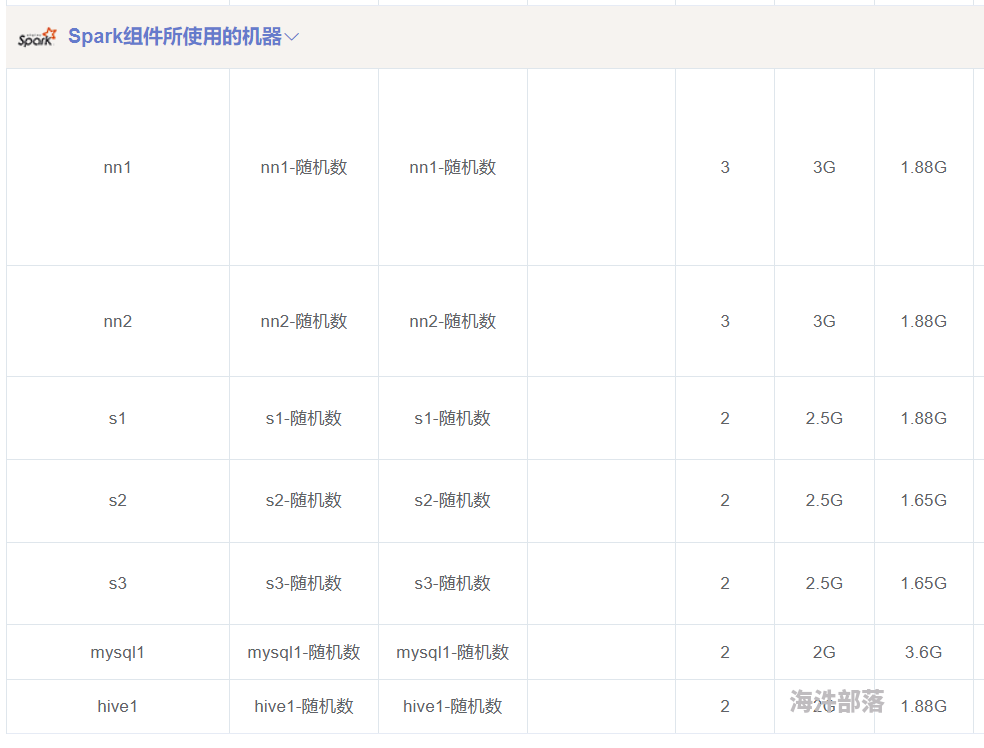
请问使用云平台Spark的默认配置可以支持百万级大数据的处理吗?数据集的原始记录大概250万条左右,中间经过连接操作可能达到500万条以上。如果不能的话,至少要选择多少核心+多少内存呀?