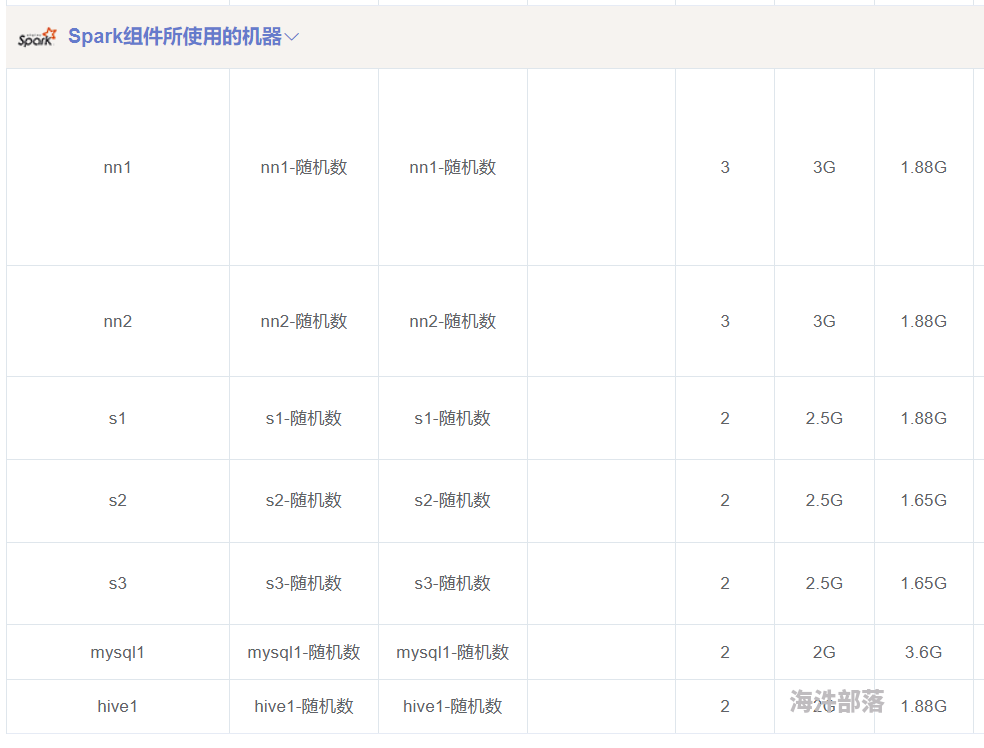
请问使用云平台Spark的默认配置可以支持百万级大数据的处理吗?数据集的原始记录大概250万条左右,中间经过连接操作可能达到500万条以上。如果不能的话,至少要选择多少核心+多少内存呀?
使用云平台 Spark 的默认配置可以支持百万级大数据的处理吗?
成为第一个点赞的人吧 
回复数量: 1
-

能,但是很慢,你至少需要30核 60G内存
作者:NEMOlv

NEMOlv 的其他话题
分类下其他主题
关注海汼部落
