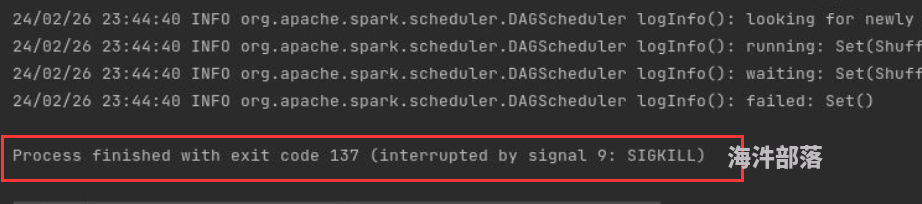
Spark RDD 编程中的电影表练习,spark使用的是local模式,在临时桌面上内存不足,请问应该如何修改,使得该任务成功运行。
以下是电影表练习需求
需求 存在这样一个表 movies电影表 movie_id movie_name movie_types 存在一个评分表 user_id movie_id score timestamp 腾讯视频或者是爱奇艺 看过这个电影的人喜欢什么 问题1 每个用户最喜欢哪个类型的电影[按照观看量] 问题2 每个类型中评分最高的前三个电影[平均分] 问题3 给每个用户推荐最喜欢的类型的前三个电影

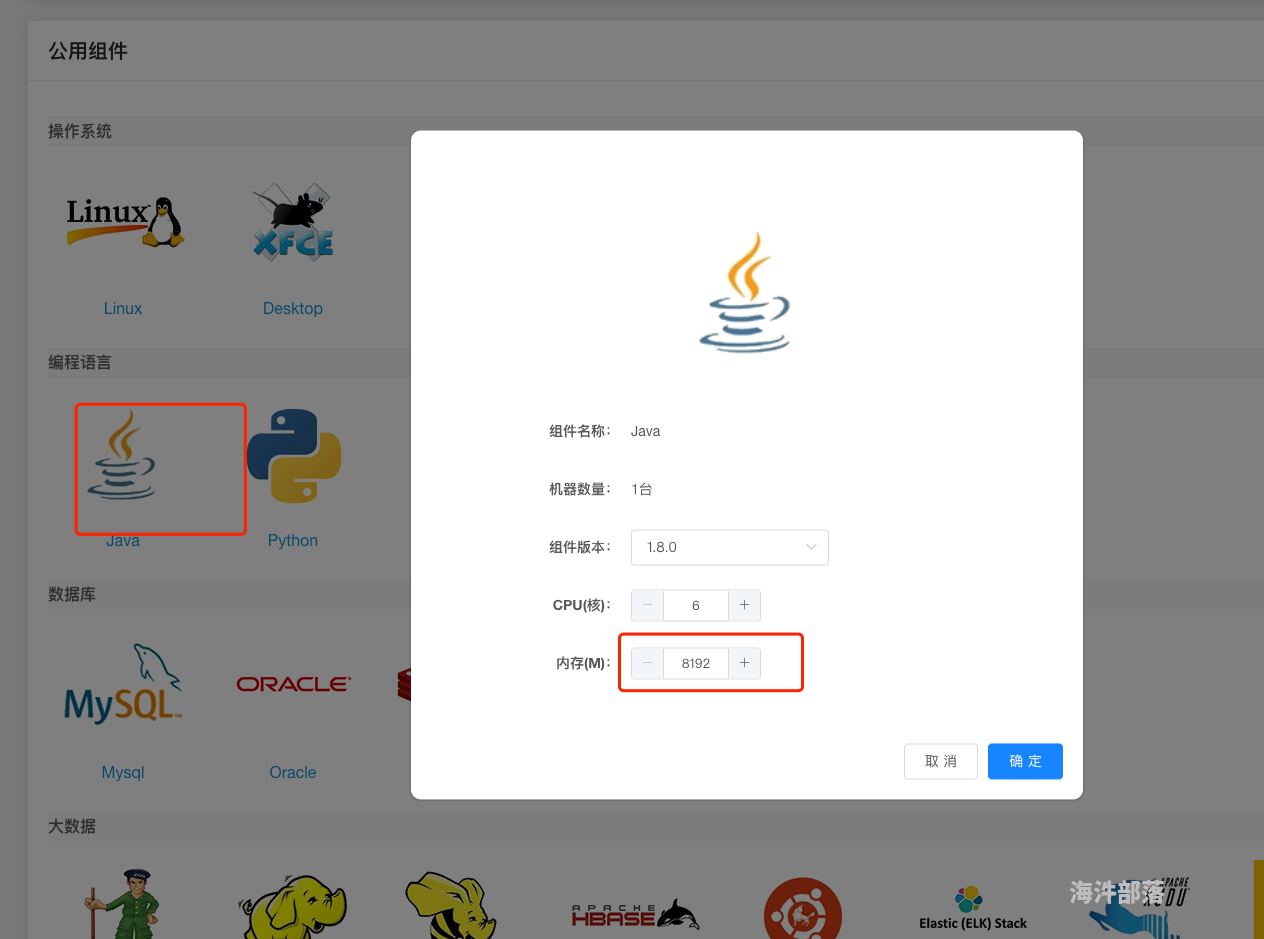
 如图所示集群运行的很慢,10分钟都没有出结果。正式桌面要达到视频中的速度需要多少CPU+多少内存呀
如图所示集群运行的很慢,10分钟都没有出结果。正式桌面要达到视频中的速度需要多少CPU+多少内存呀