关于 “” 的搜索结果, 共 2411 条
sqooporc 文件如何增量导出到 oracle 数据库?
by
 user10086
user10086
https://hainiubl.com/topics/75758?
2021-07-12
⋅
1868
⋅
0
⋅
1
现在是orc文件,使用了分区,按照id_key想增量更新到oracle数据库
之前练习的时候,发现text类型的文件可以增量导入到mysql,orc就报错,使用hcatalog提示空指针异常
有懂的大神吗?
Gauss db 如何做数据仓库?
by
 漂泊
漂泊
https://hainiubl.com/topics/75760?
2021-07-14
⋅
2551
⋅
0
⋅
1
`Gauss db 对表的分区能力这块总感觉不如hive,Gauss db创建分区表时需要先把分区创建好,这点很不如hive方便,请问这个缺陷,Gauss db 如何规避?`
`Gauss db 如何做数据仓库,有什么好的工具能将数据集成到Gauss db中呢?`
Hadoop 任务运行时卡住该怎么办?
by
 jackeywebst
jackeywebst
https://hainiubl.com/topics/75761?
2021-07-25
⋅
2020
⋅
0
⋅
2
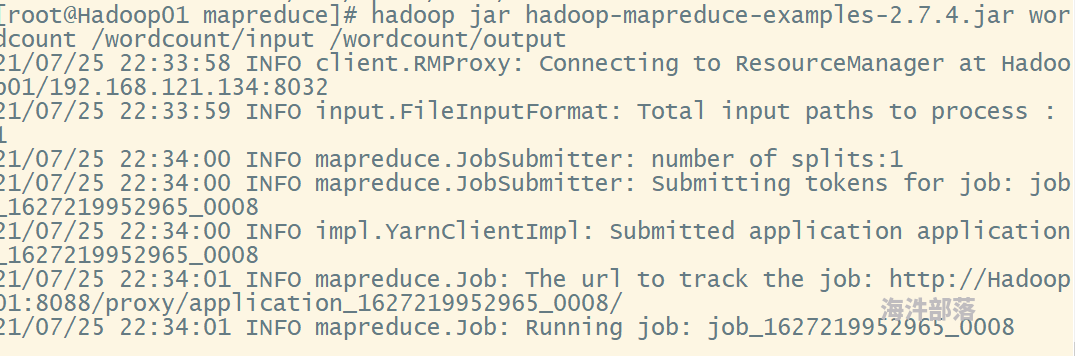
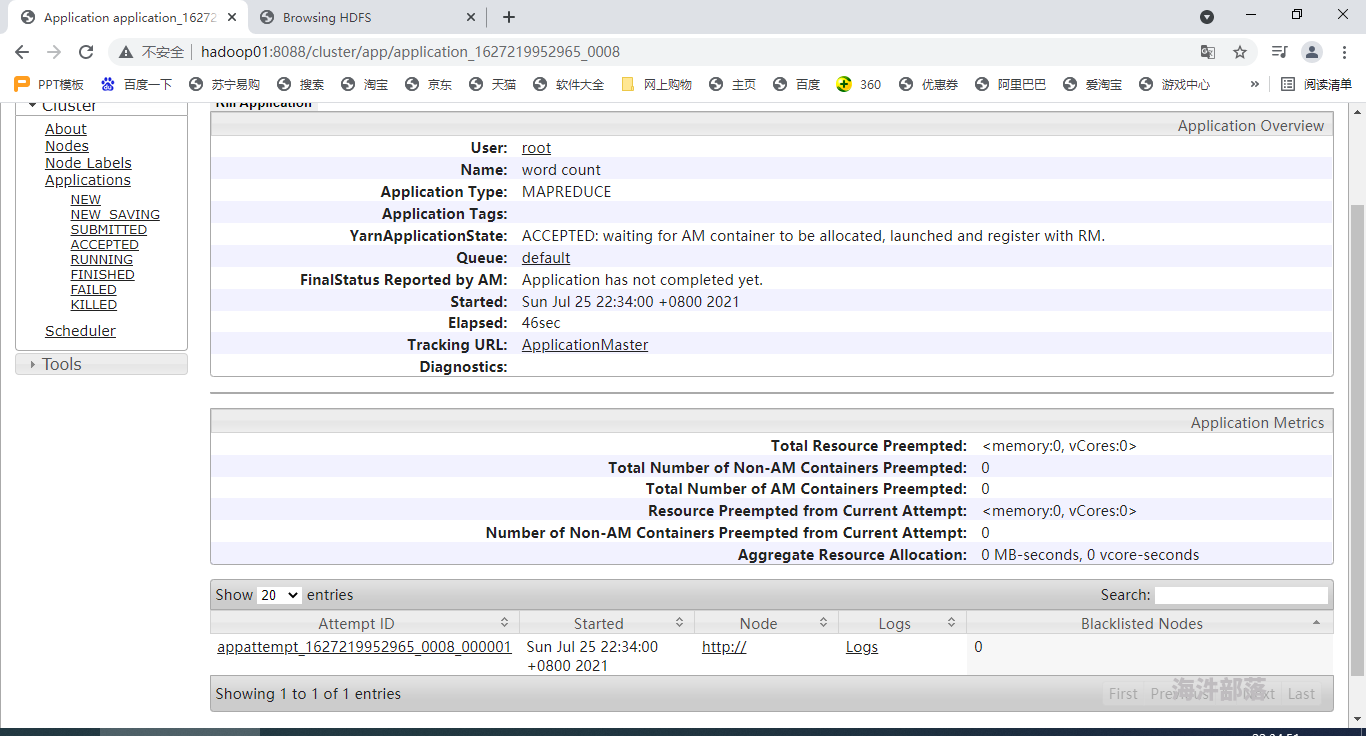
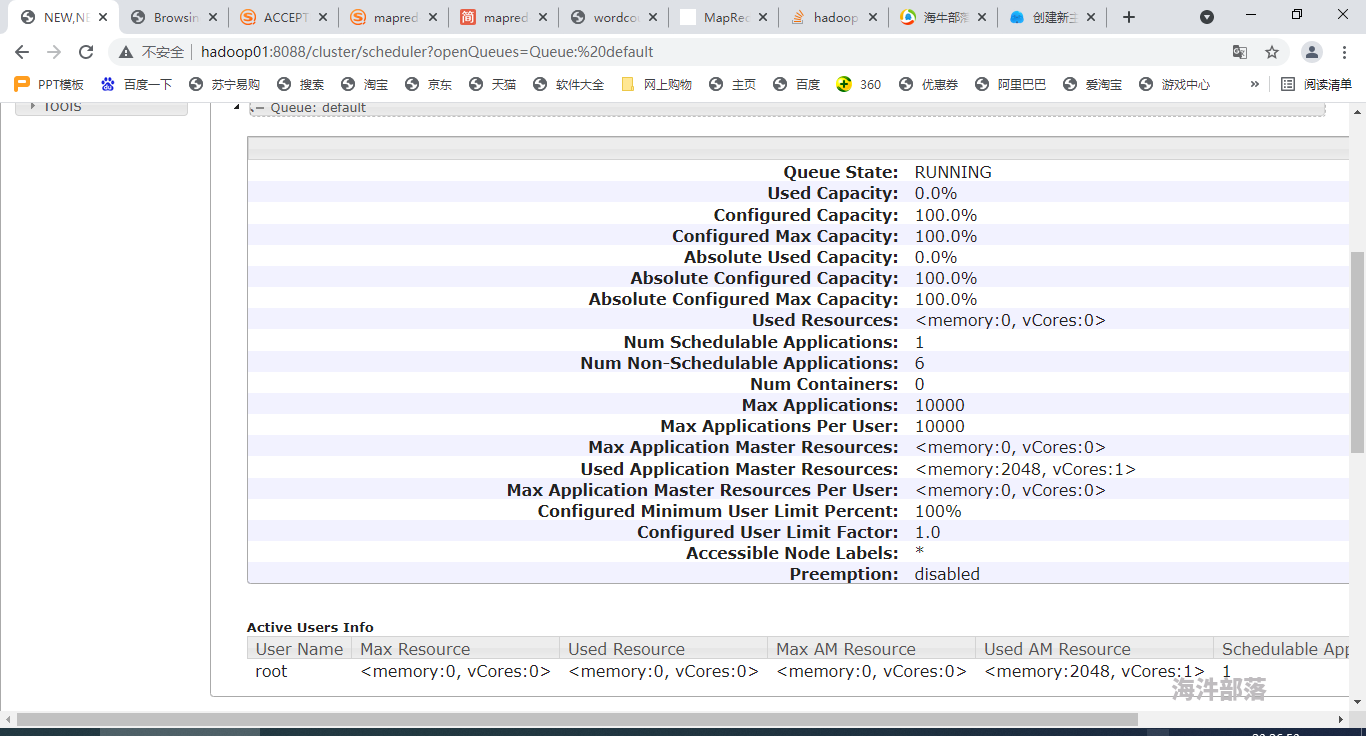
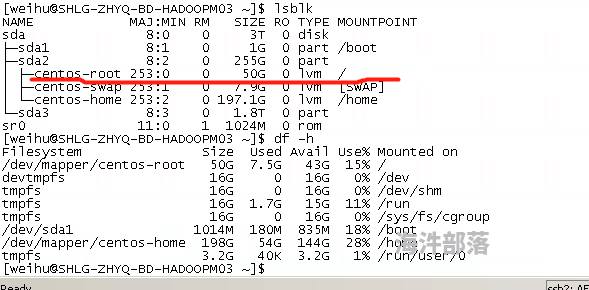
挂载点下面的目录如何创建以及扩容?
by
 树叶流年
树叶流年
https://hainiubl.com/topics/75762?
2021-07-29
⋅
2271
⋅
0
⋅
2
请教各位老师,1.图片的centos-root是如何创建的,以及它的空间50G是怎么配置的?2.现在有剩余空间,想给centos-root扩容,怎么操作?以及操作过程会对原数据产生影响吗?谢谢
企业级 NGINX 配置 1
by
 123456789987654321
123456789987654321
https://hainiubl.com/topics/75763?
2021-07-31
⋅
2428
⋅
1
⋅
2
# 一、重装和升级
在实际业务场景中,需要使用软件新版本的功能、特性。就需要对原有软件进行升级或者重装操作。
> 旧statble 稳定版 1.14
>
> stable 稳定版 1.16
>
> mainline 主线版本 最新的 1.17
## 1、信号参数
Kill 命令 传输信号给进程 N...
企业级 NGINX 配置 2
by
123456789987654321
https://hainiubl.com/topics/75764?
2021-07-31
⋅
2482
⋅
1
⋅
2
# 企业级Nginx使用-day2
# 一、第三方模块使用
Nginx官方没有的功能,开源开发者定制开发一些功能,把代码公布出来,可以通过**编译加载第三方模块**的方式,**使用新的功能**。
第三方模块网址:https://www.nginx.com/resources/wiki/modules
##1、编...
海牛商城 TOMCAT 企业级部署使用
by
123456789987654321
https://hainiubl.com/topics/75765?
2021-07-31
⋅
2644
⋅
2
⋅
0
# Tomcat
# 一、Tomcat介绍
## 1、简介
Tomcat是Apache 软件基金会(Apache Software Foundation)的Jakarta 项目中的一个核心项目,由Apache、Sun 和其他一些公司及个人共同开...
地表最强列式存储数据库 Doris 完整版
by
123456789987654321
https://hainiubl.com/topics/75766?
2021-08-11
⋅
2621
⋅
1
⋅
0
# 大数据技术之Doris
## Doris简介
### 1.1 Doris介绍
```shell
Apache Doris最早诞生于2008年,最初只为解决百度凤巢报表的专用系统。在08年那个时候数据存储和计算成熟的开源产品非常少,Hbase的导入性能只有大约2000条/秒,在这种不能满足业务的背景下,do...
hive 安装连接不到 MySQL 数据库?
by
 岁月流年
岁月流年
https://hainiubl.com/topics/75767?
2021-08-12
⋅
2912
⋅
1
⋅
15
hive启动 会报错
**hive (default)> show databases;
FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.RuntimeExcepti on: Unable to instantiate org.apache.hadoop.hive.ql.metadata.Sessio...
最简单高效的 JSON 转 CSV
by
 leeston9
leeston9
https://hainiubl.com/topics/75768?
2021-08-14
⋅
2871
⋅
0
⋅
2
json 转csv 可解放大量的ETL工作,但带数组的json需要特别处理,我使用的亚马逊redshift时已经解决了基本所有的json数据类型预处理,我是通过通用配置表配合json预处理框架实现的.这里不多介绍,只讲一下如果将一堆json数据转为csv数据,如下是只需给定json的jsonpath结...
用 hive2 通过 sentry 控制用户的读写权限?
by
岁月流年
https://hainiubl.com/topics/75769?
2021-08-23
⋅
2404
⋅
1
⋅
3
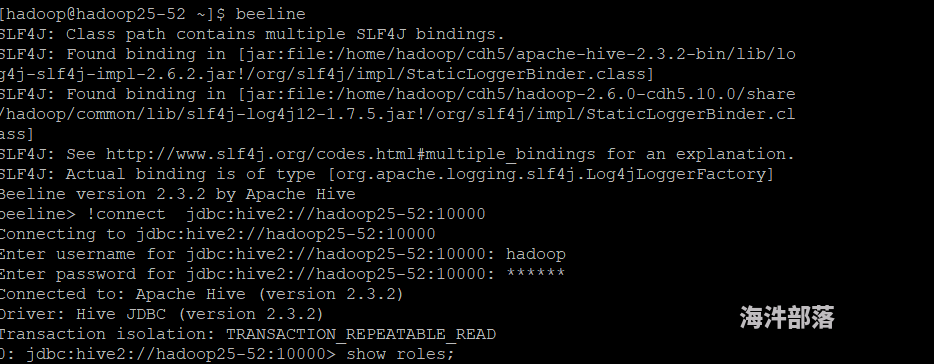
**我想勤问一下 通过sentry 来控制hive2 对用户 的权限控制 ,从网上查询都是创建角色 但是我通过beeline 执行show relos; 会出现报错 **
 张浩
张浩
https://hainiubl.com/topics/75776?
2021-08-24
⋅
3176
⋅
0
⋅
2
comone是一个列, 代码:functions.expr("case when " + comone.contains("a") + " then 'YES' else 'NO' end ");
编译后 comone.contains("a") 变成 contains(COMONE,"a"),而不是bollean类型。如何才能返回bollean类型?
本地跑 MR,配置都是为集群的,突然连不上?
by
 LH
LH
https://hainiubl.com/topics/75778?
2021-08-26
⋅
1966
⋅
0
⋅
2
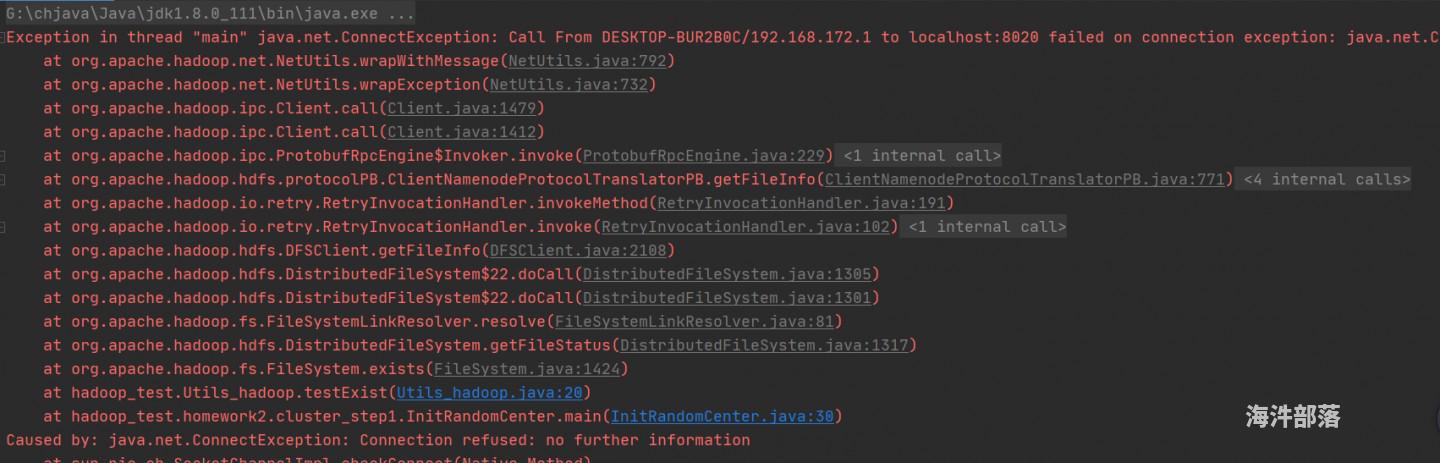
本地跑MR说连接不上
sparksql-广播变量?
by
 志欲遒
志欲遒
https://hainiubl.com/topics/75779?
2021-08-30
⋅
2018
⋅
0
⋅
1
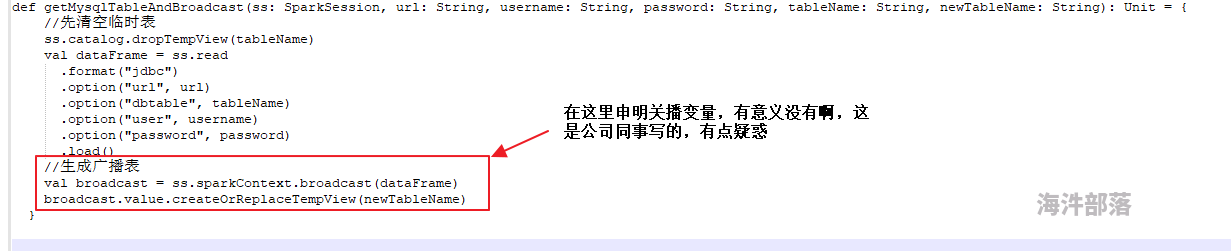
哪位大佬能否帮解答一下,感谢感谢
spark 写入 Excel 问题 ?
by
张浩
https://hainiubl.com/topics/75780?
2021-09-02
⋅
3012
⋅
0
⋅
1
shadeio.poi.ss.formula.FormulaParseException: Specified named range 'BIG' does not exist in the current workbook.
hive?
by
志欲遒
https://hainiubl.com/topics/75781?
2021-09-09
⋅
2326
⋅
0
⋅
3
在hive 中连续两次使用ctrl+c命令,结果发现hive直接连不上了,是要重启hive吗?哪位大佬解答一下啊
CDH6.3.2 安装,报错:Src file /opt/cloudera/parcels/.flood/CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel/CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel does not exist,各位大佬怎么解决?
by
Jack.Wang
https://hainiubl.com/topics/75782?
2021-09-11
⋅
4889
⋅
0
⋅
6
下午,按照cdh6.3.2的安装视频和文档,一步步安装到步骤parcel安装,下载分发后,在解压时,只有worker-1节点报错:Src file /opt/cloudera/parcels/.flood/CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel/CDH-6.3.2-1.cdh6.3.2.p0.1605554-el7.parcel does not exist!...
flink key by 后的 process 不执行?
by
张浩
https://hainiubl.com/topics/75783?
2021-09-13
⋅
2998
⋅
0
⋅
5
DataStreamSource scanJobStreamSource = KafkaUtil.getStreamSource(env, prop.getProperty("bootstrap.servers"), prop.getProperty("group.id"),"kuai2", new PoJoDeserializationSchema(ScanInfo.class,false));
scanJobStreamSource.map(new ScanInfoJobMapfunc...
flink 读 kafka 数据源后,算子并行度不一致,导致不能输出?
by
张浩
https://hainiubl.com/topics/75784?
2021-09-15
⋅
3067
⋅
0
⋅
7
本测试仅有kafkasource->map->print,三种算子。
1.将source/map/print的并行度均设为2,即kafkasource(2)->map(2)->print(2)。由于并行度一致,flink会将以上3个subtask合并为一个subtask放在slot里,共有2个subtask。
图1.1为并行度一致时代码输出结果
![file]...
flink:keyedprocessfuction 添加 state 后,报 Recovery is suppressed by FixedDelayRestartBackoffTimeStrategy/failureRateRestart?
by
张浩
https://hainiubl.com/topics/75785?
2021-09-16
⋅
8607
⋅
0
⋅
3
```
public class JobCodeKeyProcessFunction extends KeyedProcessFunction<String,ScanWrapInfo, JobInfo> {
private static Jedis jedis = null;
private static ValueState<Double> weight = null;
private static ValueState<Double> volume = nul...
HBase 存一条大于 memstore 的数据怎么存?
by
 揽月
揽月
https://hainiubl.com/topics/75786?
2021-09-22
⋅
1908
⋅
1
⋅
1
memstore只有128m,有一条130m的数据怎么存进去?
spark 中如何修改 datafraem 中的一列?
by
 wind
wind
https://hainiubl.com/topics/75787?
2021-09-27
⋅
2011
⋅
0
⋅
2
图一: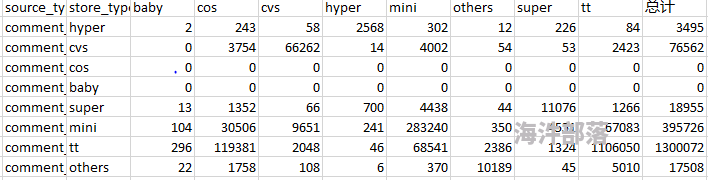
例如:用cos列除以总计列得到如下结果
图二: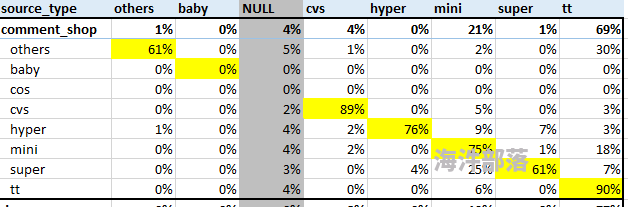
已经有如图一的DF,该使用什么方式来做呢?
flink keyby 之后,不同的 key 分到了同一个子任务中。如果我要基于 keyState 的值进行累加,该如何处理这种情况呢?
by
张浩
https://hainiubl.com/topics/75788?
2021-09-27
⋅
2795
⋅
0
⋅
2

sparksql 学习笔记
by
123456789987654321
https://hainiubl.com/topics/75789?
2021-10-06
⋅
1943
⋅
0
⋅
0
# spark thriftserver
### 1.启动服务
```shell
#启动thriftserver服务 如果报端口被占用,说明有人已经启动过
/usr/local/spark/sbin/start-thriftserver.sh --master yarn --queue hainiu
#启动beelie, 连接 op.hadoop 的thriftserver 服务
/usr/local/...
sparkstreaming 学习笔记
by
123456789987654321
https://hainiubl.com/topics/75790?
2021-10-06
⋅
1874
⋅
0
⋅
0
# spark Streaming
### 1.DStream 无状态转换操作
#### OLDDStream -> NEWDStream(当前批次和历史数据无关)
| 转换 | 描述 |
| -------------------------------- | --...
Flink 学习笔记
by
123456789987654321
https://hainiubl.com/topics/75791?
2021-10-06
⋅
2508
⋅
0
⋅
0
# Flink
## 启动
### 1.在yarn上启动jobManager
指定dirver端找到多个依赖的jar包
```shell
flink run -m yarn-cluster -yt /home/hadoop/spark_news_jars -yjm 1024 -ytm 1024 -yn 2 -ys 3 -yqu root.hainiu -ynm hainiuFlinkStreamingWordCount \
$(ll...
kylin 运行 build 报错?
by
树叶流年
https://hainiubl.com/topics/75792?
2021-10-11
⋅
2329
⋅
0
⋅
2
kylin启动正常,导入官网数据业务正常,执行kylin的build报错
报错信息:Caused by: org.apache.kylin.job.exception.ExecuteException: java.io.IOException: OS command error exit with return code: 4, error message: Cannot find hadoop installation: $HADOOP_H...
用 Java poi 给 Excel 加颜色,本地测试通过了,在集群上运行出现 java.lang.IllegalArgumentException: InputStream of class class org.apache.commons.compress.archivers.zip.ZipArchiveInputStream is not implementing InputStreamStatistics?
by
wind
https://hainiubl.com/topics/75793?
2021-10-20
⋅
3676
⋅
0
⋅
1
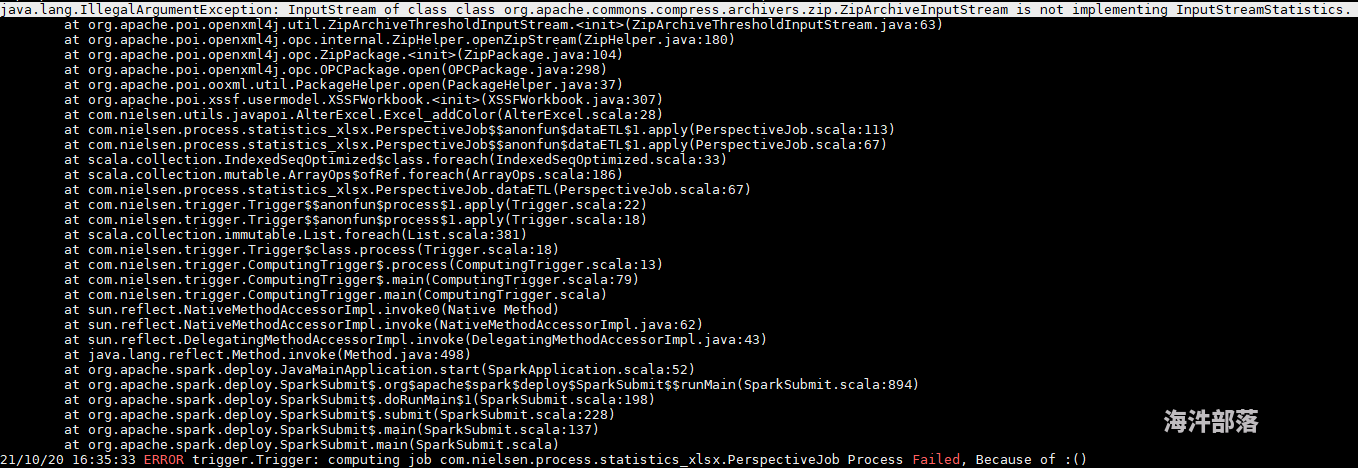
kerberos 认证了 之后,在 impala-shell 里面 create table ,怎么还会有权限问题?
by
hwanginsitein
https://hainiubl.com/topics/75794?
2021-10-25
⋅
2426
⋅
0
⋅
0
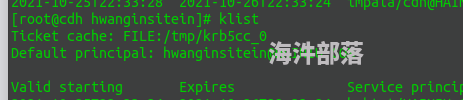

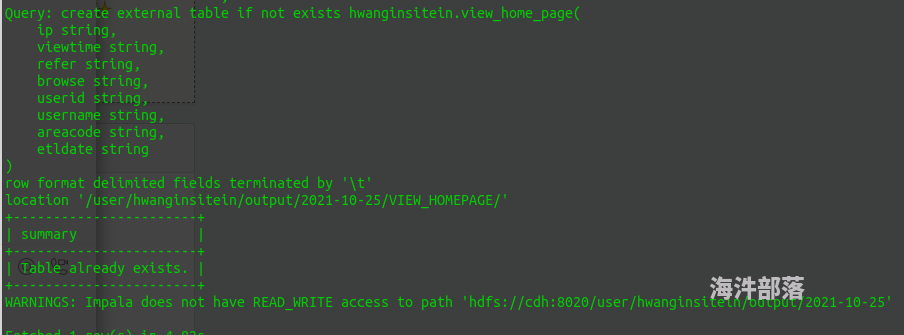
我用的是 **hwangins...
flink 写入 Redis 偶尔会出现 broken pipe ?
by
张浩
https://hainiubl.com/topics/75795?
2021-10-28
⋅
2604
⋅
0
⋅
1
一、出错信息
[图片]
二、
```
//通过这个配置对象对连接池进行相关参数的配置(如最大连接数,最大空数等)
public static JedisPoolConfig PoolConfig(){
JedisPool...