关于 “” 的搜索结果, 共 2411 条
GaussDB200 部署
by
 犀牛
犀牛
https://hainiubl.com/topics/75660?
2021-06-09
⋅
3167
⋅
2
⋅
0
# 前言
GaussDB安装需要使用fi manager,目前支持的centos最高版本为7.4,不能选择高于该版本。推荐配置内存16G,cpu核心数8C,硬盘300G。
# 软件准备
解压gaussdb.tar包,并解压至/opt目录下
上传操作系统镜像CentOS-7-x86_64-DVD-1810.iso
 tongsq
tongsq
https://hainiubl.com/topics/75662?
2021-06-10
⋅
2363
⋅
0
⋅
5
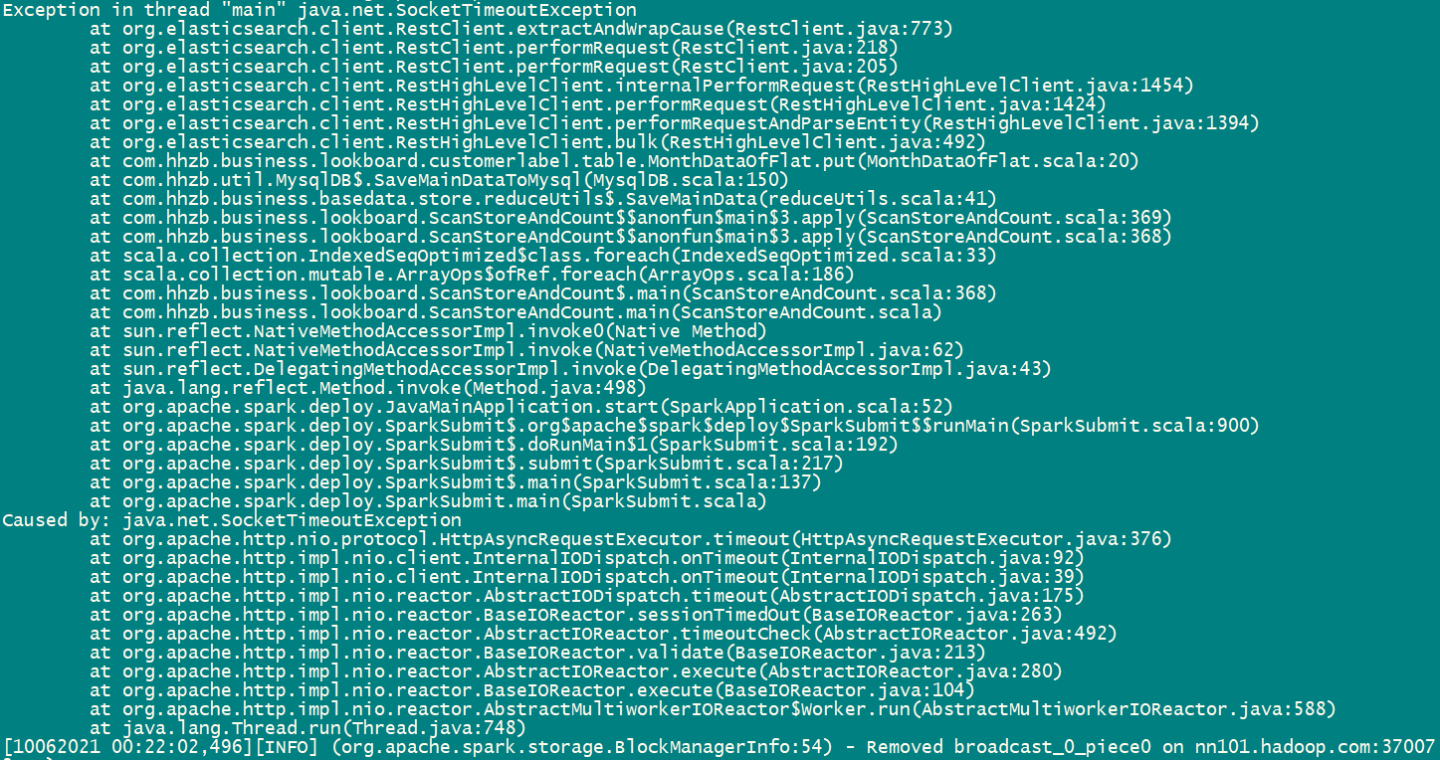
老师
这个问题是es压力太大了么
两千万条数据左右,spark批量插入es ,es索引5个主分片,2个副分片。
有什么优化措施么
还是要将每次插入的数据量减少些
Linux 中,手动释放 buff/cache 内存会对集群或应用造成什么影响么?
by
tongsq
https://hainiubl.com/topics/75663?
2021-06-10
⋅
3350
⋅
0
⋅
1
老师,在linux系统中,buff/cache 这部分偶尔会出现占用比较高的内存不释放,手动释放会对集群或应用造成什么影响么?
如果经常出现 buff/cache 这里占用内存不释放,配置个定时释放内存是否是好的解决方案
MySQL 元数据?
by
 52赫兹
52赫兹
https://hainiubl.com/topics/75664?
2021-06-10
⋅
2003
⋅
2
⋅
2
mysql中怎么查不同用户下所属的表名?
以及怎么查一张表中字段类型和字段注释呢?
MySQL 问题求助??
by
 恒古指针
恒古指针
https://hainiubl.com/topics/75665?
2021-06-10
⋅
1989
⋅
1
⋅
3
mysql load data怎么将导入数据中的decimal类型保持null值而不是转为默认0值?
Hadoop 集群搭建 -->2 zookeeper 搭建
by
 123456789987654321
123456789987654321
https://hainiubl.com/topics/75667?
2021-06-10
⋅
2166
⋅
0
⋅
0
# zookeeper安装
```shell
复制hadoop脚本文件,
删除ips中的s2 和s3
```
```shell
#分发zookeeper
[hadoop@nn1 zookeeper_base_op]$ sh scp_all.sh /tmp/upload/zookeeper-3.4.8.tar.gz /tmp/
#解压
[hadoop@nn1 zookeeper_base_op]$ sh ssh_root.sh...
scala 系列之 01scala 概述和开发环境搭建
by
 潘牛
潘牛
https://hainiubl.com/topics/75671?
2021-06-10
⋅
2354
⋅
1
⋅
0
# 1 scala介绍

Scala是一门现代的多范式编程语言,平滑地集成了<font color=red>面向对象和函数式语言</font>的特性,旨在以简练、优雅的方式...
scala 系列之 02scala 数据类型、变量、操作符、语句
by
潘牛
https://hainiubl.com/topics/75673?
2021-06-10
⋅
2286
⋅
0
⋅
0
# 3 数据类型、变量、操作符、语句
## 3.1 基本数据类型
scala 的基本类型有 8 种:
Byte、Char、Short、Int、Long、Float、Double、Boolean
Scala中没有基本数据类型的概念,所有的类型都是对象。
{
语句块1
}else if(表达式2){
语句块2
}else{
语句块3
}
```
运行逻辑和java相同,这块内容省略。
与java 不同的是,<font color= red > sc...
scala 系列之 04scala 方法和函数
by
潘牛
https://hainiubl.com/topics/75675?
2021-06-10
⋅
2108
⋅
1
⋅
0
# 5 方法与函数
## 5.1 方法
在scala中的操作符都被当成方法存在,比如说+、-、*、/
1+2就是1.+(2)的调用,
2.0 是doule类型,强调用Int类型的写法为1.+(2:Int)
、元组(Tuple)、列表(List)、映射(Map)、集合(Set)等。
Scala同时支持可变集合和不可变集合,不可变集合从不可变,可以安全的并发访问;
**不可变集合:scala.collec...
Linux 系列之七目录结构、文件属性及链接
by
 青牛
青牛
https://hainiubl.com/topics/75684?
2021-06-10
⋅
2393
⋅
0
⋅
0
# 1 linux目录结构

bin: 存放二进制可执行文件(ls,cat,mkdir等)
boot: 存放用于系统引导时使用的各种文件
**dev: 用于存放设备文件**
etc:存放系...
Linux 系列之八文件和目录管理
by
青牛
https://hainiubl.com/topics/75685?
2021-06-10
⋅
2355
⋅
0
⋅
0
# 4 建立文件和目录
## 4.1 建立目录:mkdir
linux mkdir 命令用来创建指定的名称的目录,要求创建目录的用户在当前目录中具有写权限,并且指定的目录名不能是当前目录中已有的目录。
**命令格式:**
```
mkdir [-参数] 目录
```
**命令功能:**
...
Hbase 二级索引如何选择?
by
tongsq
https://hainiubl.com/topics/75694?
2021-06-11
⋅
1988
⋅
0
⋅
2
最近在搞Hbase二级索引,es、solr、phoenix 哪个好一点呢
HDP版的Hadoop平台,单表字段较多,几亿条数据
phoenix 试了下,效果不太好,有啥好的方案么
能具体说一下这几个的区别不,嘻嘻嘻
CDH 集群安装问题?
by
 风中劲草
风中劲草
https://hainiubl.com/topics/75696?
2021-06-12
⋅
2294
⋅
0
⋅
6
请问一下,安装CDH集群出现如下问题怎么解决呢?已经多次尝试重装,仍旧无法解决。

hadoop3.2.2 高可用集群搭建 (集成常用组件)
by
 忘尘
忘尘
https://hainiubl.com/topics/75697?
2021-06-12
⋅
3230
⋅
4
⋅
1
以下文章均发布在我的个人网站,懒得一篇篇复制过来,直接上链接
[从零开始搭建个人大数据集群——环境准备篇](https://www.kingc.top/archives/cong-ling-kai-shi-da-jian-ge-ren-da-shu-ju-ji-qun--huan-jing-zhun-bei-pian)
[从零开始搭建个人大数据集群(1)——zooke...
HDFS 集群搭建 -->1
by
123456789987654321
https://hainiubl.com/topics/75699?
2021-06-14
⋅
2244
⋅
0
⋅
0
# hdfs (对应腾讯课堂视频15)
# hadoop安装
```shell
#rz
-rw-r--r-- 1 hadoop hadoop 197966159 6月 14 2019 hadoop-2.7.3.tar.gz
-rw-r--r-- 1 hadoop hadoop 27279 7月 9 2020 hadoop.zip
#分发
[hadoop@nn1 hadoop_base_op]$ sh scp_all.sh /...
shell 编写问题?
by
 岁月流年
岁月流年
https://hainiubl.com/topics/75700?
2021-06-15
⋅
2148
⋅
0
⋅
6
```shell
#!/bin/bash
/usr/lib/spark/bin/spark-submit --master yarn \
--deploy-mode client \
--principal self_Research@WZJDH \
--keytab /home/wzjd_verify/szmt/auth/self_Research.keytab \
--conf "spark.executor.extraJavaOptions=-XX:+UseConcMarkSw...
flink 连接 hadoop 无法识别文件系统,无法连接文件系统?
by
 诺
诺
https://hainiubl.com/topics/75701?
2021-06-15
⋅
2153
⋅
0
⋅
2
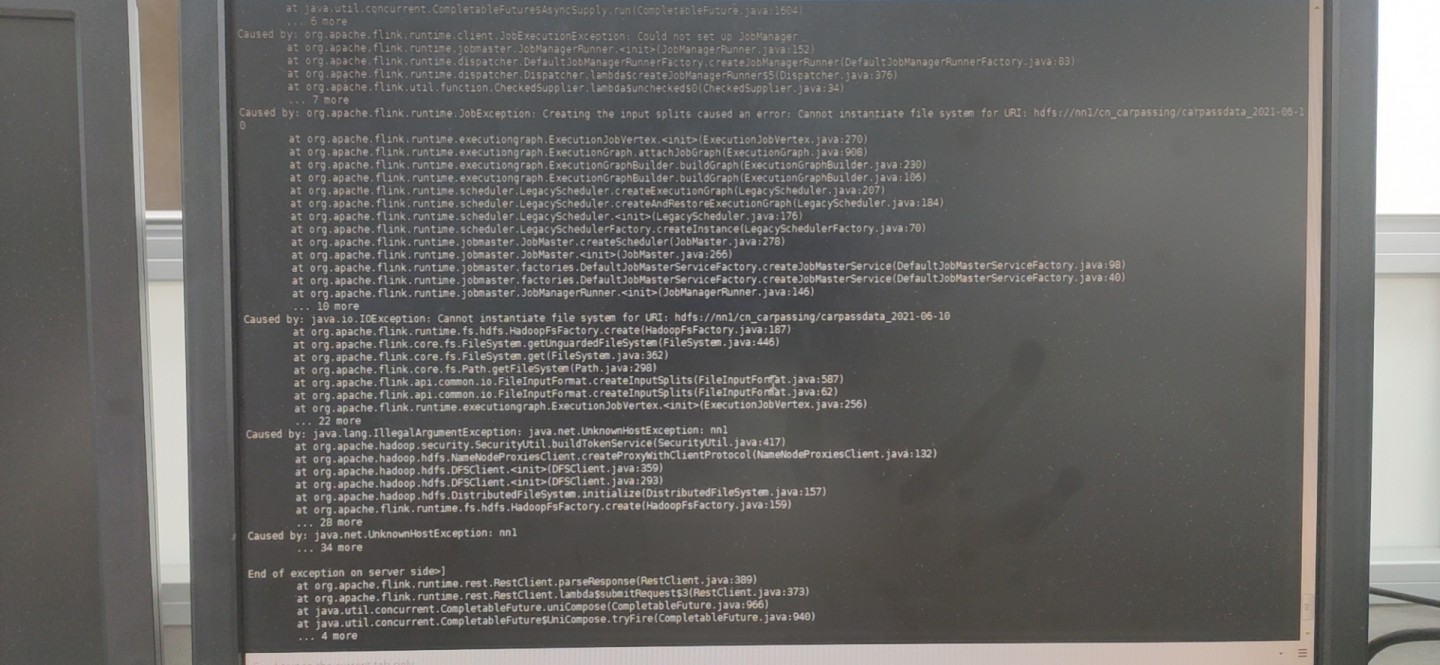
报错如图, 环境是arm架构下的单节点部署, hdfs单独使用正常, flink无法连接操作hdfs
HDFS 集群搭建 -->2 hdfs 基本命令
by
123456789987654321
https://hainiubl.com/topics/75702?
2021-06-15
⋅
2552
⋅
1
⋅
0
# hdfs命令
## 启动hdfs
```java
//启动分布式文件系统HDFS
/usr/local/hadoop/sbin/start-dfs.sh
//关闭分布式文件系统HDFS
/usr/local/hadoop/sbin/stop-dfs.sh
```
## #查看hadoop 命令的脚本
```java
//which查看可执行文件的位置
which hadoop...
hive 表的数据写入 Redis 里面 key value 怎么设计啊?
by
 Zpb
Zpb
https://hainiubl.com/topics/75703?
2021-06-16
⋅
2894
⋅
0
⋅
4
滴滴
ClickHouse 用 sql 如何实现 upsert?
by
 lghwyj
lghwyj
https://hainiubl.com/topics/75704?
2021-06-16
⋅
4673
⋅
0
⋅
1
ClickHouse实现upsert
gaussdb200 数据导出
by
犀牛
https://hainiubl.com/topics/75705?
2021-06-16
⋅
2496
⋅
1
⋅
0
# GDS导出数据
## 准备工作
```sh
# 准备导出目录
mkdir -p /output_data
chown -R gds_user:gdsgrp /output_data
```
## 创建外表
```sql
DROP FOREIGN TABLE IF EXISTS product_info_ext;
CREATE FOREIGN TABLE product_info_ext
(
product_...
gaussdb200 数据导入
by
犀牛
https://hainiubl.com/topics/75710?
2021-06-16
⋅
3463
⋅
1
⋅
0
# 数据导入方式概述
GaussDB 200提供了灵活的数据入库方式:GDS、INSERT、COPY以及gsql元命令\copy。各方式具有不同的特点:GDS因其并行的特点,导入效率高,适用于大批量数据的入库;其他三种方式适用于小批量数据入库,可以考虑其特点自行选择。
| 方式 | 特...
pom 文件报错?
by
 南无
南无
https://hainiubl.com/topics/75714?
2021-06-17
⋅
1828
⋅
0
⋅
2

怎么回事啊
superset 报表
by
犀牛
https://hainiubl.com/topics/75724?
2021-06-17
⋅
3083
⋅
0
⋅
0
# 环境准备
* 安装Python3
```sh
cd /opt
wget https://www.python.org/ftp/python/3.6.0/Python-3.6.0.tgz
```

* 解压&编译&安装
```sh
tar -zxvf Py...
怎么生成指定日期到需要的日期之间的时间维度表?
by
 然.
然.
https://hainiubl.com/topics/75725?
2021-06-18
⋅
2273
⋅
0
⋅
3
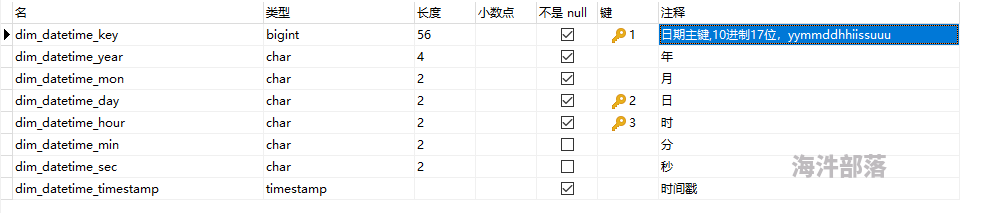
想生成这种格式的然后插入 比如2019年到2021年之间的 所有这样的 然后搞成这样的时间维度表 绝了
sqoop 原理与部署
by
犀牛
https://hainiubl.com/topics/75726?
2021-06-19
⋅
2493
⋅
1
⋅
0
# sqoop原理
* sqoop介绍
Sqoop是Apache旗下的一款“hadoop和关系型数据库服务器之间传送数据”的工具。
**导入数据**:MySQL、Oracle导入数据到hadoop的hdfs、hive、hbase等数据存储系统。
**导出数据**:从hadoop的文件系统中导出数据到关系型数据库中。
*...