关于 “” 的搜索结果, 共 2411 条
正文抽取 存入 Hbase 阶段预分 region 问题?
by
 饮水思源
饮水思源
https://hainiubl.com/topics/75401?
2021-03-07
⋅
2103
⋅
1
⋅
1
懂了没问题了
spark sql 分析血缘问题。在含有多个子查询(left join)的语句中怎么分析源表?
by
 ev7mtc3
ev7mtc3
https://hainiubl.com/topics/75403?
2021-03-18
⋅
2523
⋅
0
⋅
1
```
INSERT OVERWRITE TABLE ldldws.fact_mars_offtake PARTITION (partition_year_month)
SELECT *,DATE_FORMAT(mars_offtake_date,'yyyy-MM') AS partition_year_month
FROM
(
SELECT
t1.DOCNO AS mars_offtake_document,
t1.ODATE AS mars_offtake_...
对压缩文件进行 mapreduce,mapreduce 会对其进行解压缩吗?
by
 南无
南无
https://hainiubl.com/topics/75406?
2021-03-25
⋅
2230
⋅
0
⋅
1
如题,如果对一个snappy压缩过的文件进行mapreduce,是直接对压缩文件进行操作,还是框架会先对其进行解压缩呢
where exists (select 1 from text b where a.字段名 = b.字段名) 这个 where 条件的意义是什么?
by
ev7mtc3
https://hainiubl.com/topics/75408?
2021-03-26
⋅
2332
⋅
0
⋅
1
```
unit_cost是非空字段
update costs_20210326 t1
set t1.unit_cost=(select
case when p.promo_category='TV' then unit_cost+1
when p.promo_category='NO PROMOTION' then 0 end
from promotions p
where t1.promo_id=p.promo_id
and t1.time_id=last...
浅浅浅谈 Doris 的使用 -- 用来解决实时多维分析场景
by
 枫艾
枫艾
https://hainiubl.com/topics/75409?
2021-03-29
⋅
5413
⋅
3
⋅
1
#Doris浅谈
##1. 为什么使用Doris
- 最开始我们将我们的报表数据放在mysql中, 开开心心
- 后来我们发现了mysql出现了性能问题, 聪明的我们才用了Redis 来进行存储数据, 进行查询;
或者有钱的我们升级了 polar db 来存储我们的数据
- 后来随着数据量的提升和对数据...
`(pt_sales_date)?+.+`这行 sql 字段中?+.+ 这一串字符连用是什么意思?
by
ev7mtc3
https://hainiubl.com/topics/75410?
2021-04-07
⋅
2513
⋅
0
⋅
1
pt_sales_date 是销售时间
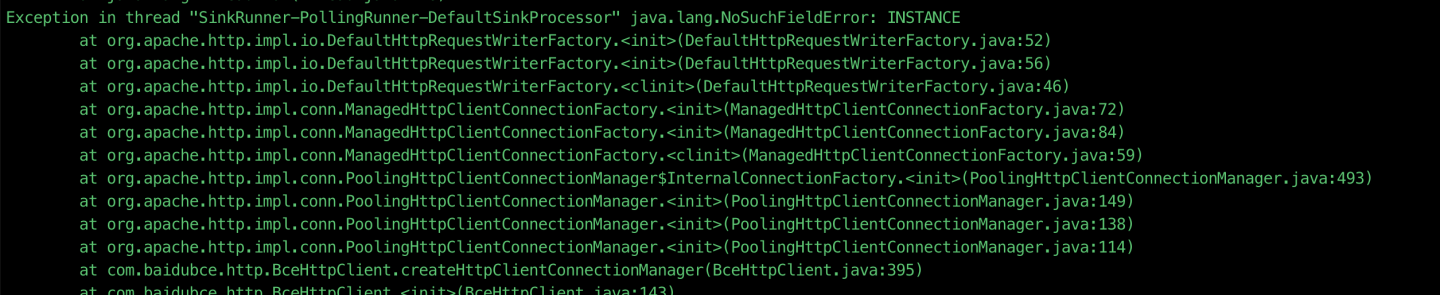
flume 往 hdfs 写日志时报错?
by
 LH
LH
https://hainiubl.com/topics/75411?
2021-04-15
⋅
2237
⋅
0
⋅
9
写的咱们课件上的第二个列子,就是flume往hdfs上写日志报错
北京急招算法工程师
by
 yang
yang
https://hainiubl.com/topics/75412?
2023-08-23
⋅
2614
⋅
1
⋅
0
急招算法工程师,薪资可谈,创业公司会辛苦些。
正文抽取中 hbase 的 rowkey 过长问题?
by
 螺旋的邂逅
螺旋的邂逅
https://hainiubl.com/topics/75413?
2021-04-16
⋅
2360
⋅
0
⋅
3
正文进入Hbase的rowkey设计是url+time+md5,发现rowkey过长大大影响查询速度,这个怎么解决?有什么好的调优方法吗?
spark 写入 Elasticsearch 丢失数据的问题?
by
 wzyaizx1314
wzyaizx1314
https://hainiubl.com/topics/75414?
2021-04-21
⋅
2732
⋅
1
⋅
7
使用官方的 elasticsearch-hadoop往es中导入数据,数据量大的时候,spark写入es会丢失一些数据,为什么?
两台服务器,每台上面两个虚拟机,怎么搭建集群?
by
 恒古指针
恒古指针
https://hainiubl.com/topics/75415?
2021-04-23
⋅
2141
⋅
0
⋅
2
两台服务器(8核,128G内存),每台服务器上创建两台虚拟机,怎么用这四台虚拟机搭建集群?
如何将一个 DataFrame 在不转换成 RDD 的情况下 将我查询出来的数据封装到一个样例里?
by
 岁月流年
岁月流年
https://hainiubl.com/topics/75418?
2021-05-20
⋅
2300
⋅
0
⋅
3
```
val bsInOut = spark.read.parquet(bsInOutPath).select("report_province", "imsi", "msisdn", "countryCode", "phone7", "countyId", "laccell", "procedureStartTime", "procedureEndTime", "longitude", "latitude").rdd
val personTrace = bsInOut.map(w =...
数据仓库分层及模型设计
by
 青牛
青牛
https://hainiubl.com/topics/75543?
2021-05-28
⋅
5033
⋅
2
⋅
2
# 数据仓库前置知识
## 数据仓库分层
使用数据分层目的,减少重复开发,隔离原始数据,按照业务需求设计层次。较为常见的为早期的四层架构(贴源层ods、明细层dwd、汇总层dws、集市层ads),如果是复杂数仓使用传统的四层架构不能满足需求,多采用五层架构(技术缓冲...
数据仓库应用场景
by
青牛
https://hainiubl.com/topics/75544?
2021-05-28
⋅
3025
⋅
1
⋅
0
# 电商行业应用
电商数仓收集各类业务日志、用户行为日志以及商品实体表等信息,按照实际业务需求设计模型,将数据规范化摆放、汇总,针对下游需求建设数据集市。如地域消费特点分析、客户消费习惯、分析影响消费因素、分析消费特点,根据数据仓库数据进行数据挖掘,...
数据仓库理论
by
青牛
https://hainiubl.com/topics/75545?
2021-05-28
⋅
2302
⋅
0
⋅
0
# 数据仓库理论
数据仓库(dataware house),一般简称DW或DWH,1990年由比尔.恩门首次提出,数据仓库建设特征四大特点面向主题、集成性、稳定性、时变性。
* 面向主题:将上游数据(结构化、非结构化)通过数据抽取加载至数据仓库,各种业务场景划分不同业务主题,按照...
java 通过 jdbc 操作 kerberos 环境下 impala
by
青牛
https://hainiubl.com/topics/75546?
2021-05-29
⋅
2184
⋅
0
⋅
0
# pom文件
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apa...
impala 实操
by
青牛
https://hainiubl.com/topics/75547?
2021-05-29
⋅
2755
⋅
3
⋅
0
# impala操作环境
* impala-shell
```sh
kinit -kt /data/impala.keytab impala
klist
impala-shell
```

```sh
# 连接impala时指定impalad,-i参数指定impalad节点(...
impala 理论
by
青牛
https://hainiubl.com/topics/75548?
2021-05-29
⋅
2634
⋅
1
⋅
0
# impala介绍
Cloudera Imapala是一款开源的MPP架构的SQL查询引擎,它提供在hadoop环境上的低延迟、高并发的BI/数据分析,是一款开源、与Hadoop高度集成,灵活可扩展的查询分析引擎,目标是基于SQL提供高并发的即席查询。
与其他的查询引擎系统(如presto、...
年薪 50W,老学员硬核内推
by
yang
https://hainiubl.com/topics/75549?
2023-07-10
⋅
2700
⋅
0
⋅
1
【老学员硬核内推】
base地北京
大数据开发岗位JD:
做数据治理相关,对模型设计要求相对高点,有一些产品(大数据相关)思维最好;其他的大数据相关技术还好(要求一般),我们都能应付。
工作氛围:氛围相对还好一些,平时不咋加班,基本上965的样子,然后平时请假两...
怎么制作拉链表?
by
 doublek
doublek
https://hainiubl.com/topics/75555?
2021-06-02
⋅
2246
⋅
0
⋅
4
我有一张记录客户初始额度的表。 和一张记录客户额度变化的流水表,这张表只有额度变化了才有记录。怎么用这两张表做拉链表呢 并没有每天的全量数据
spark 操作 hbase 之读取 hbase
by
 潘牛
潘牛
https://hainiubl.com/topics/75560?
2021-06-02
⋅
2204
⋅
0
⋅
0
# 1 通过 scan 读取 hbase 表
**应用场景:**
当想读取hbase表数据,做进一步数据处理或数据分析时,需要用scan 读取 HBASE 表。
**读取方法:**
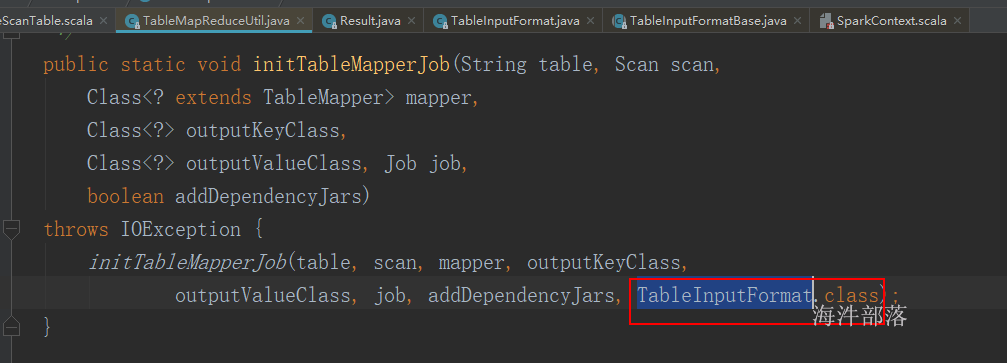...
spark 操作 hbase 之写入 hbase
by
潘牛
https://hainiubl.com/topics/75561?
2021-06-02
⋅
2383
⋅
1
⋅
0
# 1 概述
在大数据的应用场景中,hbase常用在实时读写。
写入 HBase 的方法大致有以下几种:
1)Java 调用 HBase 原生 API,HTable.add(List(Put))。
2)使用 TableOutputFormat 作为输出。
3)Bulk Load,先将数据按照 HBase 的内部数据格式生成持...
Linux 在线和离线安装 MySQL
by
潘牛
https://hainiubl.com/topics/75580?
2021-06-02
⋅
1932
⋅
0
⋅
0
# 1 linux的常用软件安装
配置阿里云的yum源
**1) 安装wget**
```shell
[root@localhost ~]# yum -y install wget
```
**2)下载yum源的配置文件**
```shell
[root@localhost ~]# wget http://mirrors.aliyun.com/repo/Centos-7.repo
```
**3) 替换原有的yum源*...
hive 聚合函数 count 的区别
by
潘牛
https://hainiubl.com/topics/75585?
2021-06-02
⋅
1644
⋅
0
⋅
0
针对于这个问题,我们来实际操作得出结论:
**建表:**
```sql
CREATE TABLE test_a(
id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
```
**生成7000003 条数据,其中7000000万条是null值,3条是有数据的**
```
1 name1
2 name2
3...
lily+Solr 原理与配置
by
 犀牛
犀牛
https://hainiubl.com/topics/75587?
2021-06-02
⋅
2079
⋅
1
⋅
0
# 概述
* 为什么要引入lily和solr
在Hbase中,表的RowKey 按照字典排序, 单一的通过RowKey检索数据的方式,不再满足更多的需求,查询成为Hbase的瓶颈,希望像Sql一样快速检索数据,Hbase之前定位的是大表的存储,要进行这样的查询,往往是要通过类似Hive、Pig等系统进...
kudu 理论
by
犀牛
https://hainiubl.com/topics/75593?
2021-06-03
⋅
2099
⋅
0
⋅
0
# kudu为何应运而生
kudu 是一个针对 Apache Hadoop 平台而开发的列式存储管理器,kudu是介于hive与hbase中间的一个组件,解决了hive的随机读写问题,同时提高了hbase的读吞吐量与组合查询效率。
* hive痛点
hive可以很高写吞吐量,但是不支持随机读写,支持组合...
kudu sql 实操
by
犀牛
https://hainiubl.com/topics/75594?
2021-06-03
⋅
1945
⋅
0
⋅
0
# impala操作kudu
## 建表
* hash分区
```sql
CREATE TABLE xiniu.my_first_table
(
id BIGINT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 16
STORED AS KUDU;
```

# pom
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www...
MySQL 驱动链接问题,已经导入 jar 包了还是链接不上?
by
岁月流年
https://hainiubl.com/topics/75596?
2021-06-04
⋅
2234
⋅
0
⋅
8
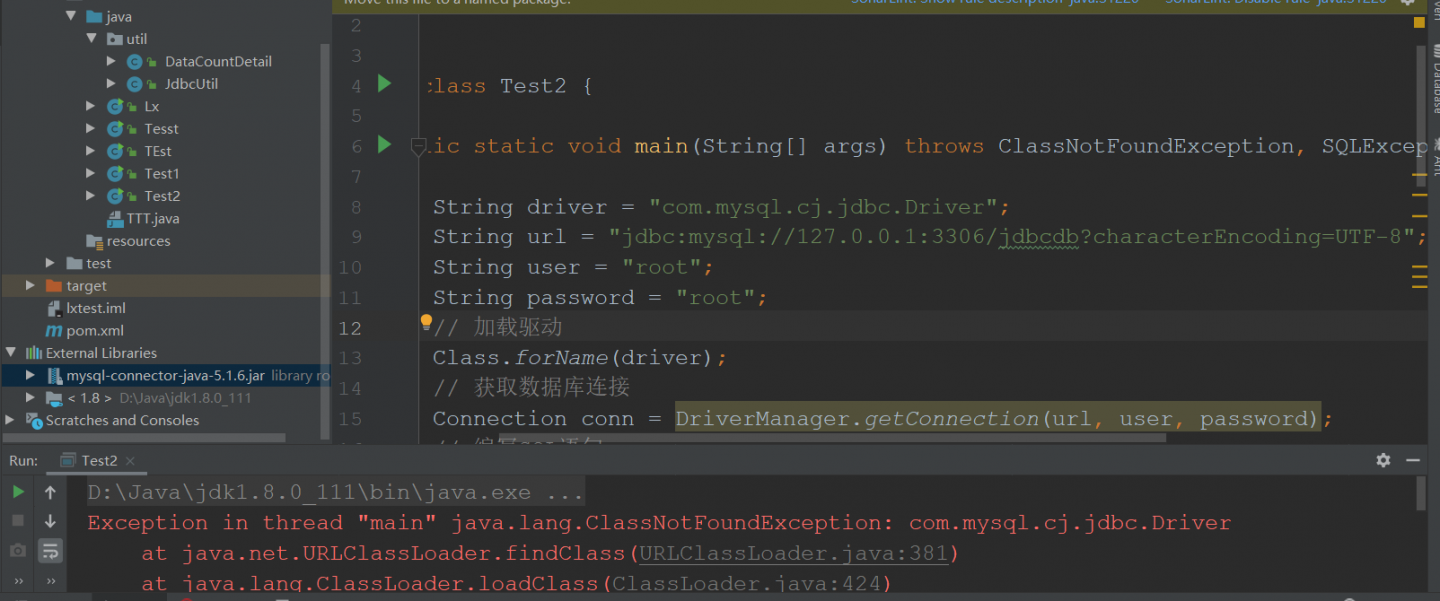
docker+k8s 报错
by
 透心凉
透心凉
https://hainiubl.com/topics/75611?
2021-06-04
⋅
2252
⋅
0
⋅
0
# docker+k8s报错
##### 问题点:docker容器中或者k8s的pod中执行systemctl相关后台服务
```sh
报错信息:Failed to get D-Bus connection: Operation not permitted
```
![file](http://www.hainiubl.com/uploads/md_images/202106/04/15/image-20210527193913599-...